ViReSkill: Vision-Grounded Replanning with Skill Memory for LLM-Based Planning in Lifelong Robot Learning
作者: Tomoyuki Kagaya, Subramanian Lakshmi, Anbang Ye, Thong Jing Yuan, Jayashree Karlekar, Sugiri Pranata, Natsuki Murakami, Akira Kinose, Yang You
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-09-29
💡 一句话要点
ViReSkill:基于视觉的技能记忆重规划,提升LLM在终身机器人学习中的规划能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 大型语言模型 视觉语言模型 运动规划 技能记忆
📋 核心要点
- 现有基于强化学习或模仿学习的机器人难以快速适应新任务,而直接使用LLM/VLM进行规划存在与环境交互不足和输出不稳定的问题。
- ViReSkill通过视觉引导的重规划和技能记忆机制,在失败时根据当前场景重新生成动作序列,成功时将计划存储为可重用技能。
- 实验表明,ViReSkill在模拟和真实机器人环境中均优于传统基线,显著提高了任务成功率,并展示了良好的泛化能力。
📝 摘要(中文)
强化学习(RL)或模仿学习(IL)训练的机器人通常难以快速适应新任务,而最近的大型语言模型(LLM)和视觉-语言模型(VLM)有望通过少量数据实现知识丰富的规划。然而,将LLM/VLM应用于运动规划面临两个主要障碍:(i)符号计划很少与场景几何和物体物理特性相关联,以及(ii)模型输出对于相同的提示可能不同,从而降低了执行可靠性。我们提出了ViReSkill,一个将视觉引导的重规划与技能记忆相结合的框架,用于积累和重用。当发生失败时,重规划器会根据当前场景生成新的动作序列,并根据观察到的状态进行调整。成功后,执行的计划将作为可重用的技能存储起来,并在未来的交互中重放,而无需额外调用LLM/VLM。这种反馈循环实现了自主的持续学习:每次尝试都会立即扩展技能集并稳定后续执行。我们在LIBERO和RLBench等模拟器以及物理机器人上评估了ViReSkill。在所有设置中,它在任务成功率方面始终优于传统基线,展示了强大的sim-to-real泛化能力。
🔬 方法详解
问题定义:论文旨在解决在终身机器人学习中,如何利用大型语言模型(LLM)或视觉-语言模型(VLM)进行有效的运动规划,同时克服其固有的局限性。现有方法,如直接使用LLM/VLM进行规划,存在两个主要痛点:一是生成的符号计划缺乏与实际场景几何和物体物理特性的关联,导致执行困难;二是LLM/VLM的输出具有不确定性,即使对于相同的输入,也可能产生不同的结果,从而影响执行的可靠性。
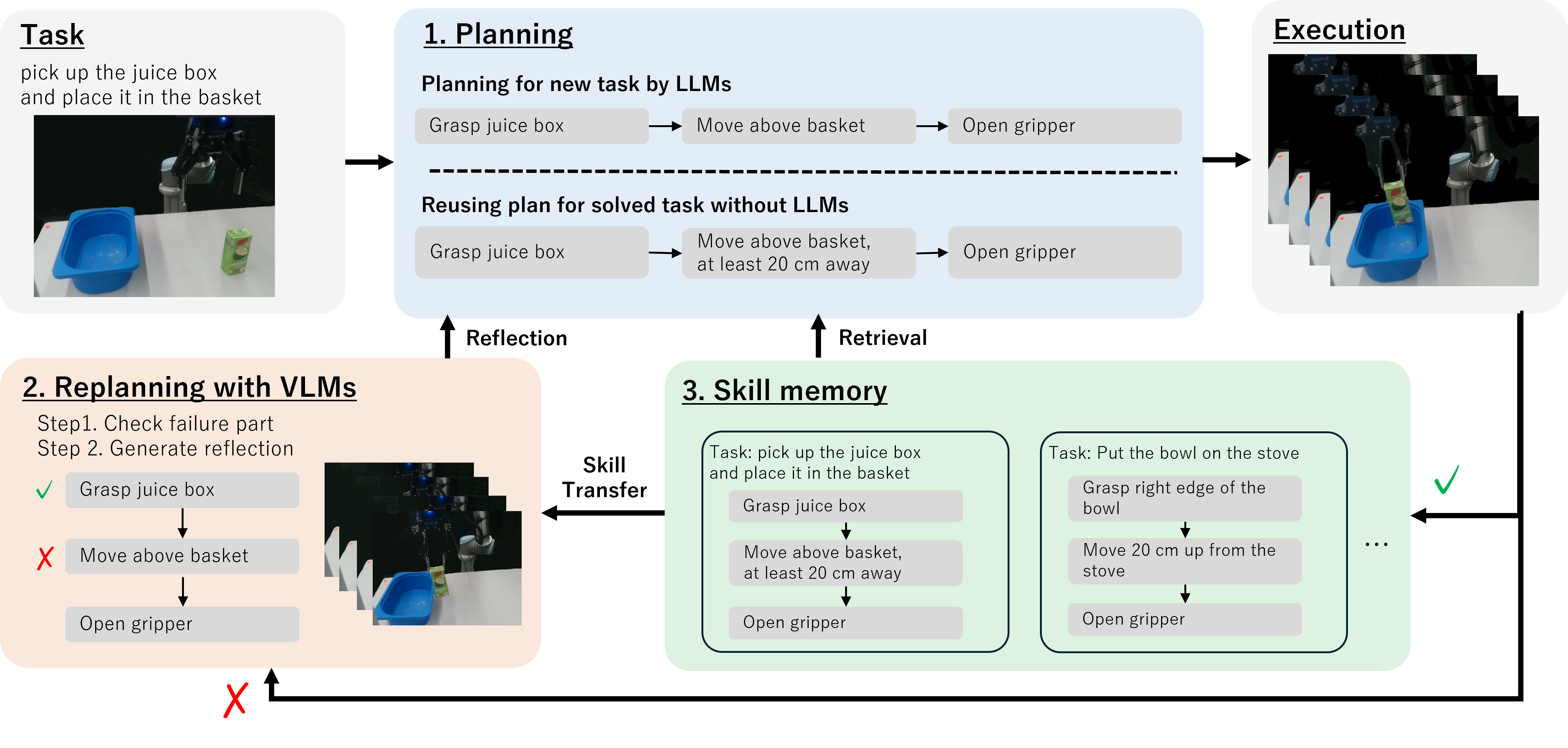
核心思路:ViReSkill的核心思路是将LLM/VLM的规划能力与视觉引导的重规划和技能记忆相结合。通过视觉信息对LLM/VLM生成的初始计划进行修正和调整,使其更好地适应实际环境。同时,利用技能记忆存储成功的计划,并在后续任务中重用,避免重复调用LLM/VLM,提高效率和稳定性。这种设计旨在弥补LLM/VLM在环境交互和输出稳定性方面的不足,实现更可靠的机器人运动规划。
技术框架:ViReSkill的整体框架包含以下几个主要模块:1) LLM/VLM规划器:根据任务目标生成初始的动作序列。2) 视觉感知模块:从环境中提取视觉信息,例如物体的位置、形状等。3) 重规划器:当执行失败时,根据视觉信息和当前状态,重新生成动作序列。4) 技能记忆:存储成功的计划,并在后续任务中重用。5) 执行器:执行动作序列。整个流程是一个闭环反馈系统,通过不断地尝试和学习,逐步完善技能记忆,提高任务成功率。
关键创新:ViReSkill最重要的技术创新点在于将视觉引导的重规划与技能记忆相结合,形成一个自主的持续学习框架。与传统的基于LLM/VLM的规划方法相比,ViReSkill能够更好地适应实际环境,提高执行的可靠性,并通过技能记忆实现知识的积累和重用。与传统的强化学习或模仿学习方法相比,ViReSkill能够利用LLM/VLM的知识,实现更快速的学习和泛化。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。但是,可以推断,视觉感知模块可能使用了卷积神经网络(CNN)等技术来提取视觉特征。重规划器可能使用了强化学习或模仿学习等方法来生成新的动作序列。技能记忆可能使用了某种形式的索引结构,以便快速检索和重用已存储的计划。具体的实现细节可能因不同的应用场景而有所不同。
🖼️ 关键图片

📊 实验亮点
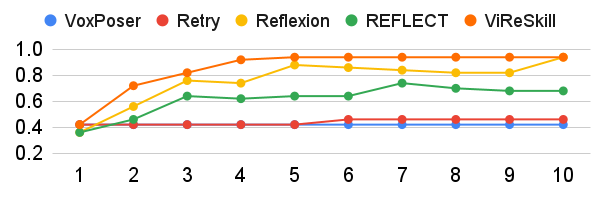
ViReSkill在LIBERO和RLBench等模拟器以及物理机器人上进行了评估,结果表明,ViReSkill在任务成功率方面始终优于传统基线。具体的数据和提升幅度在论文中没有明确给出,但摘要中强调了其在所有设置中的一致性和强大的sim-to-real泛化能力,表明该方法具有很强的实用价值。
🎯 应用场景
ViReSkill具有广泛的应用前景,可应用于各种需要机器人自主规划和执行任务的场景,例如家庭服务机器人、工业自动化、物流配送等。通过不断学习和积累技能,机器人能够更好地适应复杂多变的环境,完成各种任务,提高工作效率和安全性。该研究还有助于推动机器人技术的智能化和自主化发展。
📄 摘要(原文)
Robots trained via Reinforcement Learning (RL) or Imitation Learning (IL) often adapt slowly to new tasks, whereas recent Large Language Models (LLMs) and Vision-Language Models (VLMs) promise knowledge-rich planning from minimal data. Deploying LLMs/VLMs for motion planning, however, faces two key obstacles: (i) symbolic plans are rarely grounded in scene geometry and object physics, and (ii) model outputs can vary for identical prompts, undermining execution reliability. We propose ViReSkill, a framework that pairs vision-grounded replanning with a skill memory for accumulation and reuse. When a failure occurs, the replanner generates a new action sequence conditioned on the current scene, tailored to the observed state. On success, the executed plan is stored as a reusable skill and replayed in future encounters without additional calls to LLMs/VLMs. This feedback loop enables autonomous continual learning: each attempt immediately expands the skill set and stabilizes subsequent executions. We evaluate ViReSkill on simulators such as LIBERO and RLBench as well as on a physical robot. Across all settings, it consistently outperforms conventional baselines in task success rate, demonstrating robust sim-to-real generalization.