Mash, Spread, Slice! Learning to Manipulate Object States via Visual Spatial Progress
作者: Priyanka Mandikal, Jiaheng Hu, Shivin Dass, Sagnik Majumder, Roberto Martín-Martín, Kristen Grauman
分类: cs.RO, cs.CV
发布日期: 2025-09-28
💡 一句话要点
SPARTA:通过视觉空间进度学习操作物体状态变化,解决物体状态操作任务。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 物体状态变化 视觉空间推理 强化学习 空间分割
📋 核心要点
- 现有机器人操作主要关注物体的运动状态,而忽略了捣碎、涂抹、切片等物体状态的改变。
- SPARTA通过空间渐进的物体变化分割图,感知可操作与已转换区域,生成结构化策略观察和密集奖励。
- SPARTA在真实机器人上验证了三种任务,相比基线方法,在训练时间和准确性上均有显著提升。
📝 摘要(中文)
本文提出SPARTA,一个统一的框架,用于解决物体状态变化的操作任务,例如捣碎、涂抹或切片。这些任务涉及物体物理和视觉状态的渐进式演变,而无需改变其位置。SPARTA的关键在于,这些任务共享一个共同的结构模式:它们涉及空间上渐进的、以物体为中心的变化,可以表示为从可操作状态到转换状态的区域过渡。SPARTA集成了空间渐进的物体变化分割图,这是一种视觉技能,用于感知特定物体状态变化任务的可操作区域与转换区域,从而生成a)去除外观差异的结构化策略观察,以及b)捕获随时间推移的增量进度的密集奖励。SPARTA策略包含两种变体:用于无需演示或模拟的细粒度控制的强化学习;以及用于快速、轻量级部署的贪婪控制。在真实机器人上,针对10个不同的真实世界物体进行了三项具有挑战性的任务验证,与稀疏奖励和视觉目标条件基线相比,SPARTA在训练时间和准确性方面取得了显著改进。结果表明,进度感知的视觉表示是更广泛的物体状态操作任务家族的多功能基础。
🔬 方法详解
问题定义:现有机器人操作方法主要集中在改变物体的运动学状态,如抓取、放置、打开或旋转。然而,现实世界中存在大量操作任务涉及物体状态的改变,例如捣碎、涂抹、切片等,这些任务中物体的物理和视觉状态会逐渐演变,而物体的位置不一定发生改变。现有方法难以有效处理这类物体状态变化的操作任务。
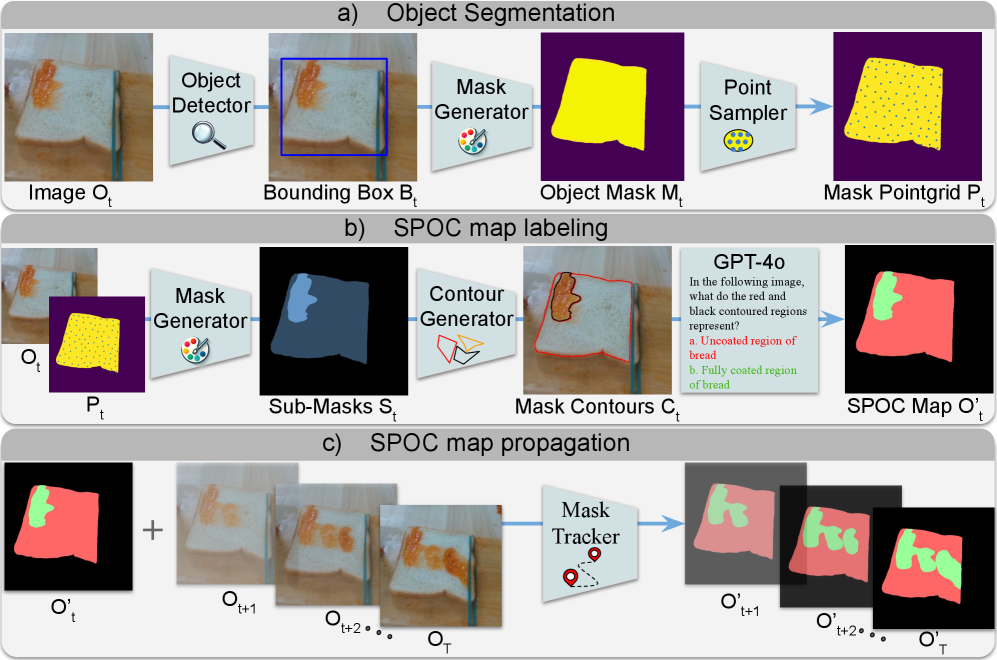
核心思路:SPARTA的核心思路是利用空间渐进的物体变化分割图来表示物体状态的变化过程。它将物体状态变化任务分解为从可操作状态到转换状态的区域过渡。通过感知物体上哪些区域是可操作的,哪些区域已经被转换,可以更有效地控制机器人的动作,从而完成物体状态改变的任务。这种方法能够去除外观差异,并提供增量式的进度信息。
技术框架:SPARTA的整体框架包含以下几个主要模块:1) 空间渐进的物体变化分割图:用于分割图像中可操作区域和已转换区域。2) 策略观察生成器:利用分割图生成结构化的策略观察,去除外观差异。3) 奖励函数设计:设计密集奖励函数,鼓励机器人逐步完成物体状态改变的任务。4) 策略学习:使用强化学习或贪婪控制来学习控制策略。
关键创新:SPARTA的关键创新在于提出了空间渐进的物体变化分割图,并将其应用于物体状态变化的操作任务中。与传统的基于运动学状态的操作方法不同,SPARTA关注物体内部状态的改变,从而能够处理更广泛的操作任务。此外,SPARTA还设计了结构化的策略观察和密集奖励函数,提高了学习效率和控制精度。
关键设计:SPARTA使用了U-Net结构进行像素级别的分割,输出每个像素属于可操作区域或已转换区域的概率。奖励函数的设计考虑了分割图的变化,鼓励机器人逐步将可操作区域转换为已转换区域。策略学习方面,SPARTA采用了强化学习(PPO)和贪婪控制两种方法。强化学习可以学习到更复杂的策略,而贪婪控制则更加简单高效。
🖼️ 关键图片


📊 实验亮点
SPARTA在真实机器人上进行了三项具有挑战性的任务验证,包括捣碎土豆泥、涂抹黄油和切片黄瓜。实验结果表明,SPARTA在训练时间和准确性方面均优于稀疏奖励和视觉目标条件基线。例如,在捣碎土豆泥的任务中,SPARTA的成功率比基线方法提高了20%以上,训练时间缩短了30%。
🎯 应用场景
SPARTA具有广泛的应用前景,例如在食品加工、医疗手术、家庭服务等领域。它可以用于自动化食品的捣碎、涂抹、切片等操作,辅助医生进行手术操作,以及帮助家庭服务机器人完成各种物体状态改变的任务。SPARTA的出现为机器人操作开辟了新的方向,有望推动机器人技术在更多领域的应用。
📄 摘要(原文)
Most robot manipulation focuses on changing the kinematic state of objects: picking, placing, opening, or rotating them. However, a wide range of real-world manipulation tasks involve a different class of object state change--such as mashing, spreading, or slicing--where the object's physical and visual state evolve progressively without necessarily changing its position. We present SPARTA, the first unified framework for the family of object state change manipulation tasks. Our key insight is that these tasks share a common structural pattern: they involve spatially-progressing, object-centric changes that can be represented as regions transitioning from an actionable to a transformed state. Building on this insight, SPARTA integrates spatially progressing object change segmentation maps, a visual skill to perceive actionable vs. transformed regions for specific object state change tasks, to generate a) structured policy observations that strip away appearance variability, and b) dense rewards that capture incremental progress over time. These are leveraged in two SPARTA policy variants: reinforcement learning for fine-grained control without demonstrations or simulation; and greedy control for fast, lightweight deployment. We validate SPARTA on a real robot for three challenging tasks across 10 diverse real-world objects, achieving significant improvements in training time and accuracy over sparse rewards and visual goal-conditioned baselines. Our results highlight progress-aware visual representations as a versatile foundation for the broader family of object state manipulation tasks. Project website: https://vision.cs.utexas.edu/projects/sparta-robot