DexFlyWheel: A Scalable and Self-improving Data Generation Framework for Dexterous Manipulation
作者: Kefei Zhu, Fengshuo Bai, YuanHao Xiang, Yishuai Cai, Xinglin Chen, Ruochong Li, Xingtao Wang, Hao Dong, Yaodong Yang, Xiaopeng Fan, Yuanpei Chen
分类: cs.RO
发布日期: 2025-09-28
备注: NeurIPS 2025, Spotlight
💡 一句话要点
DexFlyWheel:一种可扩展的、自提升的灵巧操作数据生成框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 灵巧操作 数据生成 模仿学习 强化学习 数据增强 机器人学习 自提升学习
📋 核心要点
- 现实应用中灵巧操作能力至关重要,但高质量、多样化的数据集仍然稀缺,限制了策略的泛化能力。
- DexFlyWheel通过模仿学习和残差强化学习相结合的自提升循环,持续生成多样化的数据,扩展策略性能。
- 实验表明,DexFlyWheel在多个任务上生成了大量多样化数据,训练的策略在模拟和真实世界中均取得了显著的成功率。
📝 摘要(中文)
本文提出了一种可扩展的数据生成框架DexFlyWheel,它采用自提升循环来持续丰富数据的多样性,从而解决灵巧操作中高质量数据集稀缺的问题。该框架从高效的种子演示预热开始,通过迭代循环扩展数据集。每个循环都遵循一个闭环流程,集成了模仿学习(IL)、残差强化学习(RL)、轨迹收集和数据增强。具体来说,IL从演示中提取类人行为,残差RL增强策略的泛化能力。然后,学习到的策略用于在模拟中生成轨迹,这些轨迹在不同的环境和空间配置中进一步增强,然后反馈到下一个循环中。通过连续的迭代,产生一种自提升的数据飞轮效应,生成覆盖各种场景的数据集,从而扩展策略性能。实验结果表明,DexFlyWheel在四个具有挑战性的任务中生成了超过2,000个不同的演示。在我们的数据集上训练的策略在挑战测试集上实现了平均81.9%的成功率,并通过数字孪生成功转移到现实世界,在双臂提升任务上实现了78.3%的成功率。
🔬 方法详解
问题定义:灵巧操作任务需要大量多样化的数据来训练鲁棒的策略,但现有数据收集方法要么依赖人工遥操作,成本高昂且效率低下,要么需要大量人工工程,要么生成的数据多样性有限,难以满足实际需求。现有方法难以扩展,且泛化能力受限。
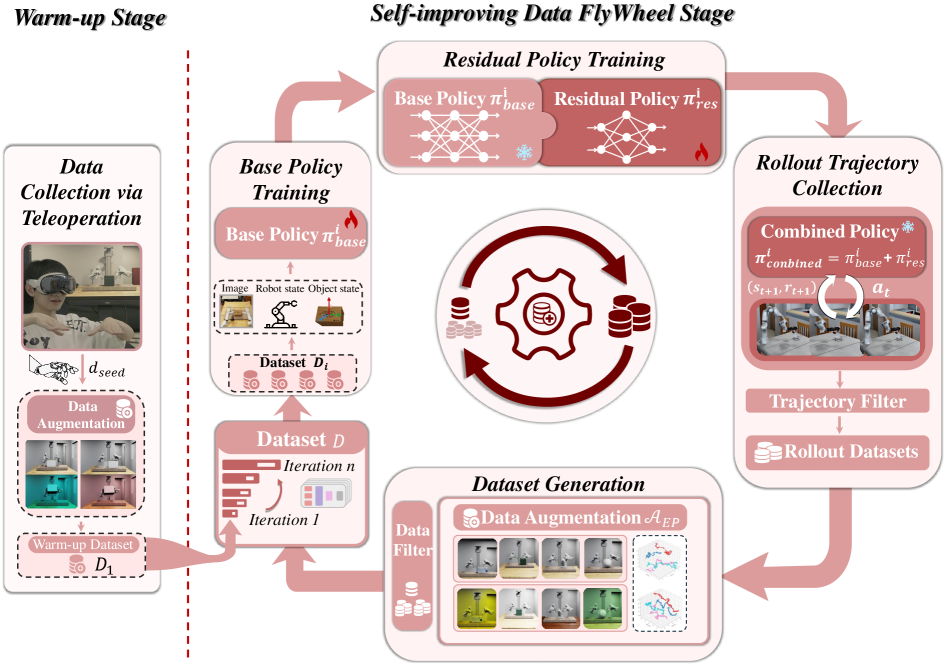
核心思路:DexFlyWheel的核心思路是构建一个自提升的数据生成循环,通过迭代的方式不断丰富数据集的多样性。该框架利用模仿学习从少量演示数据中学习初始策略,然后通过残差强化学习提升策略的泛化能力,并利用该策略生成更多样化的数据,再将这些数据用于下一轮的策略训练,从而形成一个正反馈循环。
技术框架:DexFlyWheel框架包含以下主要模块:1) 种子演示预热:利用少量人工或自动生成的演示数据作为初始数据集。2) 模仿学习(IL):从演示数据中学习初始策略,提取类人行为。3) 残差强化学习(RL):在模仿学习的基础上,利用强化学习进一步优化策略,提升泛化能力。4) 轨迹收集:利用学习到的策略在模拟环境中生成大量轨迹数据。5) 数据增强:对生成的轨迹数据进行增强,例如改变环境光照、物体位置等,增加数据的多样性。6) 数据反馈:将增强后的数据反馈到下一轮的策略训练中,形成自提升循环。
关键创新:DexFlyWheel的关键创新在于其自提升的数据生成循环。通过模仿学习和残差强化学习相结合的方式,能够有效地利用少量演示数据生成大量多样化的数据,从而避免了对大量人工标注数据的依赖。此外,该框架还采用了数据增强技术,进一步提升了数据的多样性。
关键设计:在残差强化学习中,策略被设计为模仿学习策略的残差,这有助于稳定训练过程并加速收敛。数据增强策略包括随机改变环境光照、物体位置、以及添加噪声等。损失函数包括模仿学习损失和强化学习奖励函数。具体参数设置未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DexFlyWheel在四个具有挑战性的任务中生成了超过2,000个不同的演示。在这些数据集上训练的策略在挑战测试集上实现了平均81.9%的成功率,并通过数字孪生成功转移到现实世界,在双臂提升任务上实现了78.3%的成功率。这些结果表明,DexFlyWheel能够有效地生成高质量、多样化的数据,并提升策略的性能。
🎯 应用场景
DexFlyWheel框架可应用于各种需要灵巧操作的机器人任务,例如装配、抓取、操作工具等。该框架能够降低数据收集的成本,提高策略的泛化能力,从而加速机器人在实际场景中的应用。未来,该框架可以进一步扩展到其他机器人任务,例如导航、规划等。
📄 摘要(原文)
Dexterous manipulation is critical for advancing robot capabilities in real-world applications, yet diverse and high-quality datasets remain scarce. Existing data collection methods either rely on human teleoperation or require significant human engineering, or generate data with limited diversity, which restricts their scalability and generalization. In this paper, we introduce DexFlyWheel, a scalable data generation framework that employs a self-improving cycle to continuously enrich data diversity. Starting from efficient seed demonstrations warmup, DexFlyWheel expands the dataset through iterative cycles. Each cycle follows a closed-loop pipeline that integrates Imitation Learning (IL), residual Reinforcement Learning (RL), rollout trajectory collection, and data augmentation. Specifically, IL extracts human-like behaviors from demonstrations, and residual RL enhances policy generalization. The learned policy is then used to generate trajectories in simulation, which are further augmented across diverse environments and spatial configurations before being fed back into the next cycle. Over successive iterations, a self-improving data flywheel effect emerges, producing datasets that cover diverse scenarios and thereby scaling policy performance. Experimental results demonstrate that DexFlyWheel generates over 2,000 diverse demonstrations across four challenging tasks. Policies trained on our dataset achieve an average success rate of 81.9\% on the challenge test sets and successfully transfer to the real world through digital twin, achieving a 78.3\% success rate on dual-arm lift tasks.