Focusing on What Matters: Object-Agent-centric Tokenization for Vision Language Action models
作者: Rokas Bendikas, Daniel Dijkman, Markus Peschl, Sanjay Haresh, Pietro Mazzaglia
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-09-28
备注: Presented at 9th Conference on Robot Learning (CoRL 2025), Seoul, Korea
💡 一句话要点
提出Oat-VLA,通过对象-智能体中心化Token化,提升VLA模型在机器人操作中的效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人操作 对象中心表示 Token化 计算效率 归纳偏置 深度学习
📋 核心要点
- 现有VLA模型在机器人操作中应用VLM时,视觉输入的Token化方案导致计算成本过高,效率低下。
- Oat-VLA通过引入对象和智能体中心化的Token化方法,减少视觉Token数量,降低计算复杂度。
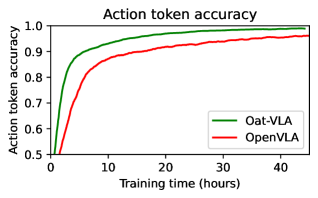
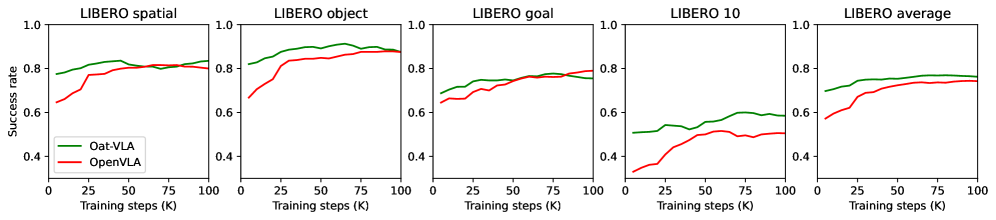
- 实验表明,Oat-VLA在LIBERO套件上的收敛速度是OpenVLA的两倍,并在真实世界的抓取放置任务中表现更优。
📝 摘要(中文)
视觉-语言-动作(VLA)模型通过将大型预训练视觉-语言模型(VLM)重新用于输出机器人动作,为大规模学习机器人操作提供了一种关键方法。然而,将VLM应用于机器人领域会带来不必要的高计算成本,我们将其归因于视觉输入的Token化方案。在这项工作中,我们旨在通过提出Oat-VLA(一种面向VLA的对象-智能体中心化Token化方法)来实现高效的VLA训练。基于对象中心表示学习的见解,我们的方法引入了对场景对象和智能体自身视觉信息的归纳偏置。结果表明,Oat-VLA可以在不牺牲性能的情况下,将视觉Token的数量大幅减少到几个。我们发现,在LIBERO套件上,Oat-VLA的收敛速度至少是OpenVLA的两倍,并且在各种真实世界的抓取和放置任务中也优于OpenVLA。
🔬 方法详解
问题定义:现有VLA模型直接采用VLM的视觉Token化方法,导致在机器人操作任务中存在大量冗余计算。这些方法没有充分利用机器人操作场景的特点,例如场景中的关键对象和智能体自身的状态信息,从而造成计算资源的浪费。现有方法的痛点在于计算效率低,难以进行大规模的机器人操作学习。
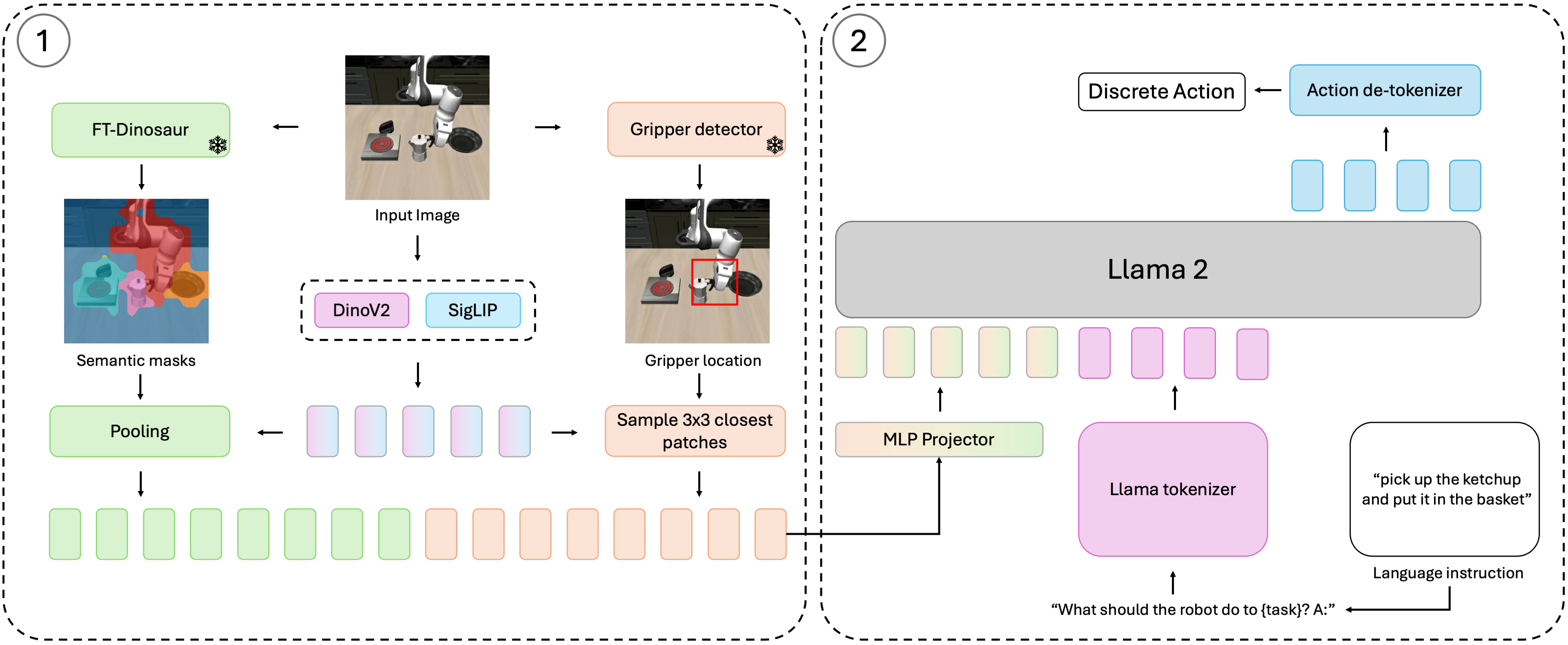
核心思路:Oat-VLA的核心思路是利用对象中心表示学习的优势,将视觉输入分解为与场景中关键对象和智能体自身相关的Token。通过引入对象和智能体中心化的归纳偏置,模型可以更有效地关注与任务相关的视觉信息,从而减少需要处理的Token数量,提高计算效率。这种设计基于机器人操作任务的特性,即智能体的行为通常与特定对象和自身状态密切相关。
技术框架:Oat-VLA的整体框架包括以下几个主要模块:1) 对象检测模块:用于检测场景中的关键对象;2) 智能体状态编码模块:用于编码智能体的自身状态信息(例如,机械臂的关节角度);3) Token化模块:将检测到的对象和智能体状态编码为视觉Token;4) VLA模型:使用处理后的Token作为输入,输出机器人动作。整个流程首先提取场景中的对象和智能体信息,然后将其转换为精简的Token序列,最后输入到VLA模型中进行动作预测。
关键创新:Oat-VLA最重要的技术创新点在于其对象-智能体中心化的Token化方法。与传统的基于图像块的Token化方法不同,Oat-VLA直接关注场景中的关键对象和智能体自身,从而能够更有效地提取与任务相关的视觉信息。这种方法能够显著减少Token数量,提高计算效率,同时保持甚至提升模型性能。
关键设计:Oat-VLA的关键设计包括:1) 使用预训练的对象检测模型(例如,Mask R-CNN)来检测场景中的对象;2) 使用神经网络来编码智能体的状态信息;3) 设计了一种特殊的Token化策略,将对象和智能体状态信息转换为视觉Token。具体的参数设置和网络结构细节在论文中进行了详细描述,例如对象检测模型的阈值、智能体状态编码网络的层数和激活函数等。损失函数方面,Oat-VLA可能采用了标准的交叉熵损失或回归损失,具体取决于机器人动作的表示方式。
🖼️ 关键图片
📊 实验亮点
Oat-VLA在LIBERO套件上的实验结果表明,其收敛速度至少是OpenVLA的两倍。此外,在真实世界的抓取和放置任务中,Oat-VLA也优于OpenVLA。这些结果表明,Oat-VLA能够显著提高VLA模型的训练效率和泛化能力。具体性能提升幅度未知,需要参考论文中的详细数据。
🎯 应用场景
Oat-VLA可应用于各种机器人操作任务,例如工业自动化、家庭服务机器人、医疗机器人等。通过提高VLA模型的训练效率,可以加速机器人在复杂环境中的学习和适应能力。该研究的实际价值在于降低了机器人操作学习的计算成本,使得大规模的机器人操作学习成为可能。未来,Oat-VLA可以与其他先进的机器人学习技术相结合,进一步提升机器人的智能化水平。
📄 摘要(原文)
Vision-Language-Action (VLA) models offer a pivotal approach to learning robotic manipulation at scale by repurposing large pre-trained Vision-Language-Models (VLM) to output robotic actions. However, adapting VLMs for robotic domains comes with an unnecessarily high computational cost, which we attribute to the tokenization scheme of visual inputs. In this work, we aim to enable efficient VLA training by proposing Oat-VLA, an Object-Agent-centric Tokenization for VLAs. Building on the insights of object-centric representation learning, our method introduces an inductive bias towards scene objects and the agent's own visual information. As a result, we find that Oat-VLA can drastically reduce the number of visual tokens to just a few tokens without sacrificing performance. We reveal that Oat-VLA converges at least twice as fast as OpenVLA on the LIBERO suite, as well as outperform OpenVLA in diverse real-world pick and place tasks.