Multi-Modal Manipulation via Multi-Modal Policy Consensus
作者: Haonan Chen, Jiaming Xu, Hongyu Chen, Kaiwen Hong, Binghao Huang, Chaoqi Liu, Jiayuan Mao, Yunzhu Li, Yilun Du, Katherine Driggs-Campbell
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-09-27 (更新: 2025-10-13)
备注: 9 pages, 7 figures. Project website: https://policyconsensus.github.io
💡 一句话要点
提出基于多模态策略共识的多模态操作方法,提升机器人操作的鲁棒性和灵活性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 机器人操作 扩散模型 策略学习 触觉感知 视觉感知 共识学习
📋 核心要点
- 现有方法在融合多模态信息时,视觉等主导模态易掩盖触觉等关键信息,且缺乏灵活性。
- 该方法将策略分解为多个模态特有扩散模型,通过路由网络学习共识权重自适应融合。
- 实验表明,该方法在模拟和真实操作任务中均优于特征拼接方法,并具有鲁棒性。
📝 摘要(中文)
有效整合多样化的传感器模态对于机器人操作至关重要。然而,传统的特征拼接方法通常并非最优:视觉等主导模态可能会淹没接触类任务中稀疏但关键的触觉信号,并且单体架构无法灵活地整合新的或缺失的模态,而无需重新训练。本文提出了一种方法,将策略分解为一组扩散模型,每个模型专门针对单个表征(例如,视觉或触觉),并采用一个路由网络,该网络学习共识权重以自适应地组合它们的贡献,从而能够增量地添加新的表征。我们在{RLBench}中的模拟操作任务以及真实世界的任务(如遮挡物体拾取、手中勺子重新定向和拼图插入)中评估了我们的方法,在需要多模态推理的场景中,它明显优于特征拼接基线。我们的策略进一步证明了对物理扰动和传感器损坏的鲁棒性。我们进一步进行了基于扰动的重要性分析,揭示了模态之间的自适应转移。
🔬 方法详解
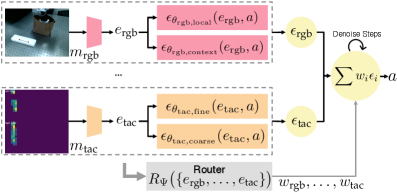
问题定义:现有机器人操作方法在处理多模态信息时,通常采用特征拼接的方式。这种方式的缺点在于,强势模态(如视觉)容易主导整个策略,而忽略了在特定任务中至关重要的弱势模态(如触觉)。此外,当需要加入新的模态或者某些模态缺失时,传统的单体架构需要重新训练,缺乏灵活性和可扩展性。
核心思路:本文的核心思路是将策略分解为多个独立的、模态特定的子策略,每个子策略专注于处理一种模态的信息。然后,通过一个路由网络学习不同子策略的共识权重,自适应地融合它们的输出,从而实现多模态信息的有效整合。这种解耦的设计使得系统可以灵活地添加或删除模态,而无需重新训练整个模型。
技术框架:整体框架包含以下几个主要模块:1) 多个模态特定的扩散模型,每个模型接收一种模态的输入(如视觉、触觉),并生成相应的动作建议。2) 一个路由网络,接收所有模态的特征表示,并学习一个权重向量,用于加权融合各个扩散模型的输出。3) 一个最终的策略执行器,接收加权融合后的动作建议,并执行相应的动作。整个流程是端到端可训练的。
关键创新:最重要的创新点在于将多模态策略分解为多个模态特定的子策略,并通过路由网络学习自适应的融合权重。这种解耦的设计使得系统可以更好地利用不同模态的信息,并具有更强的灵活性和可扩展性。与传统的特征拼接方法相比,该方法能够更好地平衡不同模态的贡献,避免强势模态淹没弱势模态。
关键设计:每个模态特定的扩散模型都采用标准的扩散模型架构,例如DDPM或DDIM。路由网络可以采用简单的多层感知机(MLP)结构。损失函数包括两部分:一是模仿学习损失,用于训练每个模态特定的扩散模型;二是共识损失,用于训练路由网络,使其能够学习到合理的融合权重。共识损失鼓励路由网络输出的权重能够反映不同模态对当前任务的重要性。
🖼️ 关键图片


📊 实验亮点
该方法在RLBench模拟环境和真实世界的操作任务中进行了评估,包括遮挡物体拾取、手中勺子重新定向和拼图插入。实验结果表明,该方法在需要多模态推理的场景中,显著优于特征拼接基线。例如,在遮挡物体拾取任务中,该方法能够利用触觉信息弥补视觉信息的不足,从而提高抓取成功率。此外,该方法还表现出对物理扰动和传感器损坏的鲁棒性。
🎯 应用场景
该研究成果可应用于各种需要多模态信息融合的机器人操作任务,例如:在遮挡环境下进行物体抓取、在复杂环境中进行装配、以及需要触觉反馈的精细操作。该方法能够提升机器人在复杂环境中的鲁棒性和适应性,具有广泛的应用前景。
📄 摘要(原文)
Effectively integrating diverse sensory modalities is crucial for robotic manipulation. However, the typical approach of feature concatenation is often suboptimal: dominant modalities such as vision can overwhelm sparse but critical signals like touch in contact-rich tasks, and monolithic architectures cannot flexibly incorporate new or missing modalities without retraining. Our method factorizes the policy into a set of diffusion models, each specialized for a single representation (e.g., vision or touch), and employs a router network that learns consensus weights to adaptively combine their contributions, enabling incremental of new representations. We evaluate our approach on simulated manipulation tasks in {RLBench}, as well as real-world tasks such as occluded object picking, in-hand spoon reorientation, and puzzle insertion, where it significantly outperforms feature-concatenation baselines on scenarios requiring multimodal reasoning. Our policy further demonstrates robustness to physical perturbations and sensor corruption. We further conduct perturbation-based importance analysis, which reveals adaptive shifts between modalities.