Leave No Observation Behind: Real-time Correction for VLA Action Chunks
作者: Kohei Sendai, Maxime Alvarez, Tatsuya Matsushima, Yutaka Matsuo, Yusuke Iwasawa
分类: cs.RO, cs.AI, cs.CV, eess.SY
发布日期: 2025-09-27
💡 一句话要点
提出A2C2实时修正VLA模型动作块,提升长时序任务的反应性和鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 动作块 实时控制 长时程规划 机器人控制
📋 核心要点
- VLA模型通过预测动作块来提高效率,但会牺牲实时性和长时程任务的反应性。
- A2C2通过轻量级的校正头,在每个控制步骤实时修正动作块,恢复闭环响应性。
- 实验表明,A2C2在多个任务中显著提升了成功率和鲁棒性,且开销很小。
📝 摘要(中文)
为了提高效率和时间连贯性,视觉-语言-动作(VLA)模型通常预测动作块;然而,这种动作分块损害了推理延迟和长时程下的反应性。我们引入了异步动作块校正(A2C2),这是一个轻量级的实时块校正头,它在每个控制步骤运行,并将时间感知的校正添加到任何现成的VLA的动作块中。该模块结合了最新的观察、来自VLA的预测动作(基础动作)、编码基础动作在块内的索引的位置特征以及来自基础策略的一些特征,然后输出每步校正。这保留了基础模型的能力,同时恢复了闭环响应性。该方法不需要重新训练基础策略,并且与诸如实时分块(RTC)之类的异步执行方案正交。在动态Kinetix任务套件(12个任务)和LIBERO Spatial上,我们的方法在增加延迟和执行范围的情况下,产生了持续的成功率提升(分别比RTC高+23%和+7%),并且即使在零注入延迟的情况下,也提高了长时程的鲁棒性。由于校正头很小且速度很快,因此与大型VLA模型的推理相比,开销很小。这些结果表明,A2C2是一种有效的插件机制,用于在实时控制中部署高容量分块策略。
🔬 方法详解
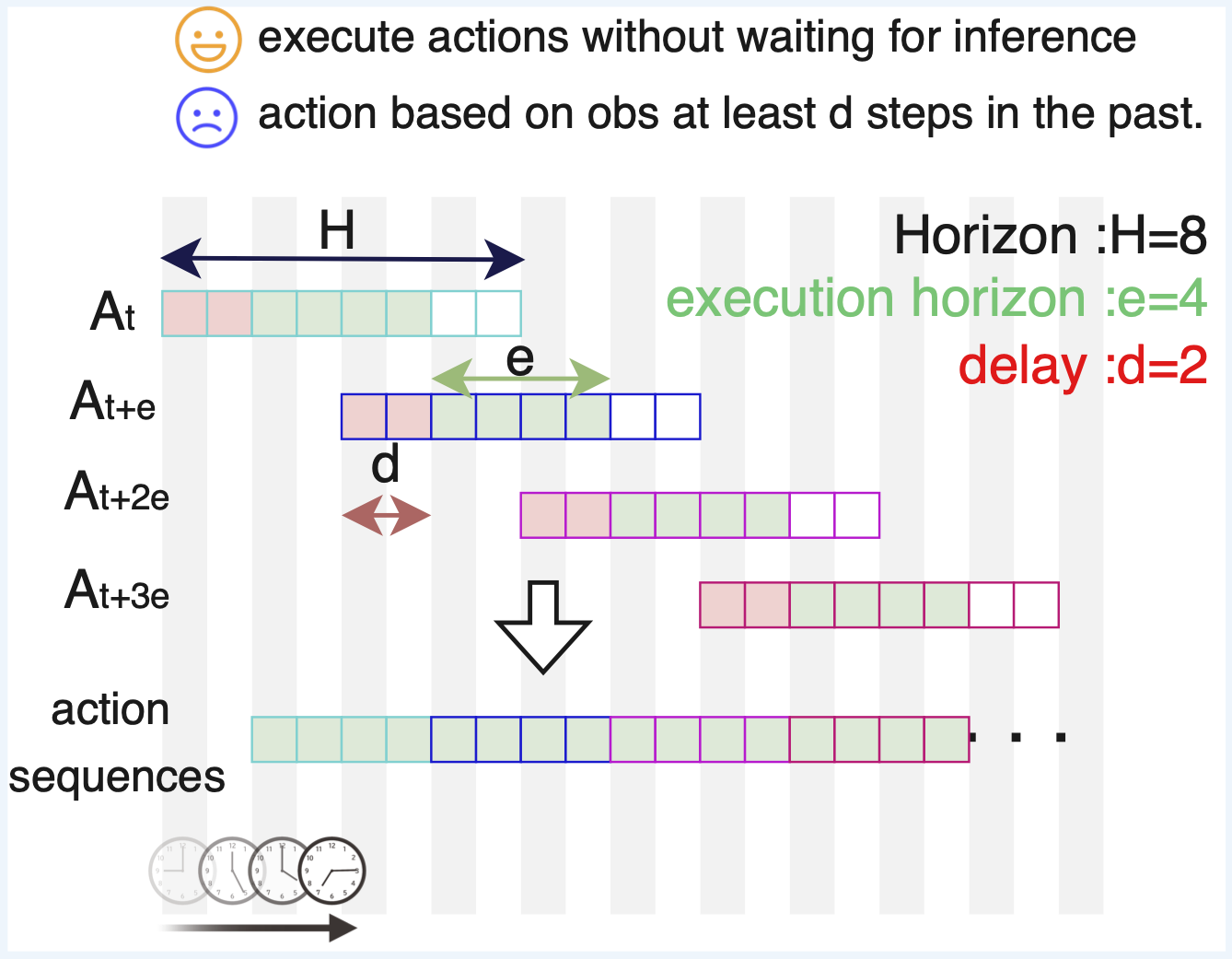
问题定义:VLA模型为了提高效率和时间连贯性,通常会预测动作块,即一次性预测多个时间步的动作。然而,这种做法会导致模型在面对推理延迟和长时程任务时,无法及时根据环境变化做出反应,从而降低了控制性能。现有方法如实时分块(RTC)虽然可以缓解这个问题,但仍然存在改进空间。
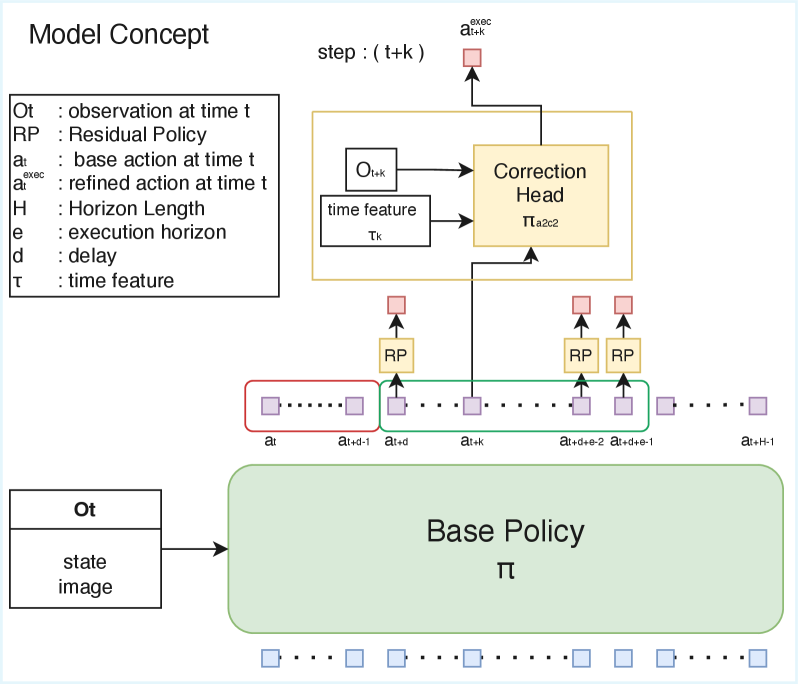
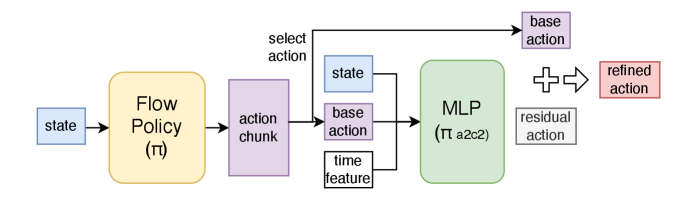
核心思路:A2C2的核心思路是在VLA模型预测的动作块的基础上,增加一个轻量级的实时校正模块。该模块在每个控制步骤运行,根据当前的环境观察和VLA模型预测的动作,对动作块中的每个动作进行微调,从而恢复模型的实时响应能力。这种方法无需重新训练VLA模型,可以即插即用。
技术框架:A2C2模块接收以下输入:最新的环境观察、VLA模型预测的动作(基础动作)、一个位置特征(指示当前动作在动作块中的位置)以及来自VLA模型的一些内部特征。这些输入被送入一个小型神经网络,输出一个每步的校正量。该校正量被加到基础动作上,得到最终的控制动作。整个过程可以看作是在VLA模型的基础上增加了一个实时的反馈控制环。
关键创新:A2C2的关键创新在于其轻量级和实时性。它不需要重新训练VLA模型,可以作为插件集成到现有的VLA系统中。同时,由于其计算量很小,因此可以保证实时性,不会引入额外的延迟。此外,A2C2还考虑了动作在动作块中的位置信息,从而可以更好地进行校正。
关键设计:A2C2模块的网络结构是一个小型多层感知机(MLP),输入包括环境观察、基础动作、位置编码和VLA模型的内部特征。损失函数通常采用均方误差(MSE),用于最小化校正后的动作与真实动作之间的差异。位置编码可以使用正弦余弦编码或学习到的嵌入向量。具体参数设置需要根据具体的VLA模型和任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,A2C2在Kinetix任务套件和LIBERO Spatial上均取得了显著的性能提升。在Kinetix任务套件上,A2C2相比于RTC,成功率提升了23%。在LIBERO Spatial上,A2C2相比于RTC,成功率提升了7%。此外,A2C2在长时程任务中表现出更强的鲁棒性,即使在零延迟的情况下也能取得良好的效果。这些结果证明了A2C2是一种有效的实时动作块校正方法。
🎯 应用场景
A2C2可广泛应用于需要实时控制和长时程规划的机器人任务中,例如自动驾驶、无人机控制、机器人操作等。它能够提升机器人在复杂动态环境中的适应性和鲁棒性,使其能够更好地完成各种任务。未来,A2C2还可以与其他先进的控制算法相结合,进一步提升机器人的智能水平。
📄 摘要(原文)
To improve efficiency and temporal coherence, Vision-Language-Action (VLA) models often predict action chunks; however, this action chunking harms reactivity under inference delay and long horizons. We introduce Asynchronous Action Chunk Correction (A2C2), which is a lightweight real-time chunk correction head that runs every control step and adds a time-aware correction to any off-the-shelf VLA's action chunk. The module combines the latest observation, the predicted action from VLA (base action), a positional feature that encodes the index of the base action within the chunk, and some features from the base policy, then outputs a per-step correction. This preserves the base model's competence while restoring closed-loop responsiveness. The approach requires no retraining of the base policy and is orthogonal to asynchronous execution schemes such as Real Time Chunking (RTC). On the dynamic Kinetix task suite (12 tasks) and LIBERO Spatial, our method yields consistent success rate improvements across increasing delays and execution horizons (+23% point and +7% point respectively, compared to RTC), and also improves robustness for long horizons even with zero injected delay. Since the correction head is small and fast, there is minimal overhead compared to the inference of large VLA models. These results indicate that A2C2 is an effective, plug-in mechanism for deploying high-capacity chunking policies in real-time control.