SAC-Loco: Safe and Adjustable Compliant Quadrupedal Locomotion
作者: Aoqian Zhang, Zixuan Zhuang, Chunzheng Wang, Shuzhi Sam Ge, Fan Shi, Cheng Xiang
分类: cs.RO, eess.SY
发布日期: 2025-09-27
💡 一句话要点
提出SAC-Loco框架,实现四足机器人安全且可调节的柔顺步态
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 柔顺控制 强化学习 安全策略 步态控制 师生学习 可恢复性网络
📋 核心要点
- 现有四足机器人控制方法缺乏动物所具备的关键能力:响应外部扰动的自适应和可调节柔顺性,且难以应对大型扰动。
- 论文提出一种切换策略框架,核心在于利用强化学习训练可调节柔顺等级的力柔顺策略,并结合安全策略和可恢复性网络。
- 该框架无需力传感器即可实现力柔顺控制,并能在严重外部扰动下保证四足机器人的安全性和鲁棒性。
📝 摘要(中文)
本文提出了一种用于四足机器人柔顺且安全步态的切换策略框架。首先,利用师生强化学习框架训练一个具有可调节柔顺等级的力柔顺策略,无需显式力传感。其次,开发一个基于捕获点概念的安全策略,以在柔顺策略失效时稳定机器人。最后,引入一个可恢复性网络来预测失效的可能性,并在柔顺策略和安全策略之间切换。该框架使四足机器人能够在受到严重外部扰动时实现力柔顺和鲁棒安全性。
🔬 方法详解
问题定义:现有四足机器人控制方法在应对外部扰动时,缺乏足够的柔顺性和自适应性,容易在受到较大扰动时失效。传统的控制方法往往依赖精确的力/力矩控制,需要昂贵的力传感器,且难以实现可调节的柔顺性。因此,需要一种能够在无需力传感器的情况下,实现安全且可调节柔顺步态的控制方法。
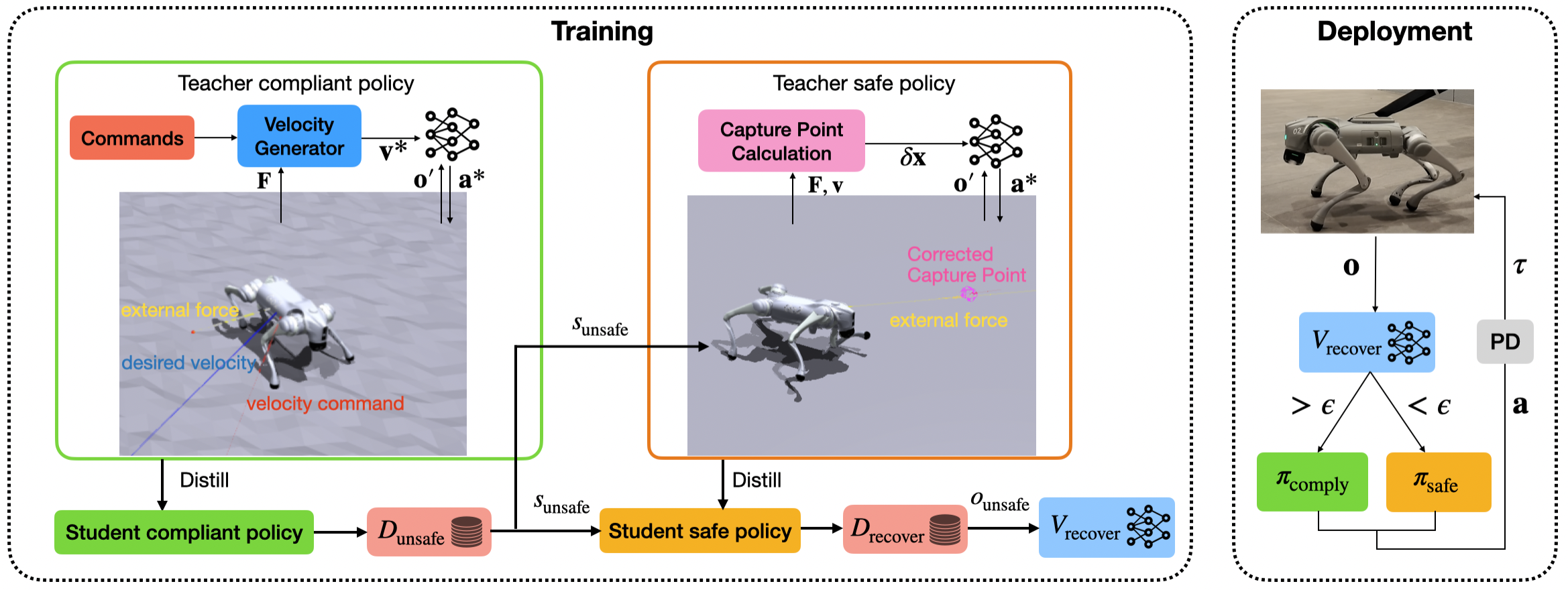
核心思路:论文的核心思路是利用强化学习训练一个力柔顺策略,并通过师生学习框架实现可调节的柔顺等级。同时,为了保证安全性,引入一个基于捕获点概念的安全策略,并在柔顺策略失效时切换到安全策略。通过可恢复性网络预测失效概率,实现策略之间的平滑切换。
技术框架:整体框架包含三个主要模块:1) 力柔顺策略:使用强化学习训练,输出期望的关节力矩,实现柔顺控制。2) 安全策略:基于捕获点理论设计,当机器人状态偏离安全区域时激活,保证机器人稳定。3) 可恢复性网络:预测当前状态下柔顺策略失效的概率,根据概率值在柔顺策略和安全策略之间进行切换。
关键创新:论文的关键创新在于:1) 提出了一种无需力传感器的力柔顺控制方法,降低了硬件成本和复杂性。2) 通过师生学习框架实现了可调节的柔顺等级,提高了控制的灵活性。3) 结合安全策略和可恢复性网络,保证了机器人在复杂环境下的安全性和鲁棒性。
关键设计:力柔顺策略使用Actor-Critic架构的强化学习算法(具体算法未知)。师生学习框架中,教师网络提供力矩目标,学生网络学习在没有力传感器的情况下复现教师网络的行为。可恢复性网络是一个分类网络,输入是机器人状态,输出是柔顺策略失效的概率。切换策略根据可恢复性网络的输出,使用加权平均的方式融合柔顺策略和安全策略的输出力矩。
🖼️ 关键图片

📊 实验亮点
论文提出SAC-Loco框架,实现了四足机器人在复杂环境下的安全且可调节的柔顺步态。通过强化学习训练的力柔顺策略,机器人能够在没有力传感器的情况下实现柔顺控制。安全策略和可恢复性网络的引入,保证了机器人在受到严重外部扰动时的安全性。具体的性能数据和对比基线未知。
🎯 应用场景
该研究成果可应用于搜索救援、物流运输、巡检等复杂地形环境下的四足机器人任务。通过可调节的柔顺性,机器人能够更好地适应不平整地面和外部干扰,提高运动效率和稳定性。安全策略的引入则保证了机器人在未知环境下的安全性,降低了发生碰撞或跌倒的风险。未来,该技术有望应用于更广泛的机器人领域,例如人机协作、医疗康复等。
📄 摘要(原文)
Quadruped robots are designed to achieve agile locomotion by mimicking legged animals. However, existing control methods for quadrupeds often lack one of the key capabilities observed in animals: adaptive and adjustable compliance in response to external disturbances. Most locomotion controllers do not provide tunable compliance and tend to fail under large perturbations. In this work, we propose a switched policy framework for compliant and safe quadruped locomotion. First, we train a force compliant policy with adjustable compliance levels using a teacher student reinforcement learning framework, eliminating the need for explicit force sensing. Next, we develop a safe policy based on the capture point concept to stabilize the robot when the compliant policy fails. Finally, we introduce a recoverability network that predicts the likelihood of failure and switches between the compliant and safe policies. Together, this framework enables quadruped robots to achieve both force compliance and robust safety when subjected to severe external disturbances.