LAGEA: Language Guided Embodied Agents for Robotic Manipulation
作者: Abdul Monaf Chowdhury, Akm Moshiur Rahman Mazumder, Rabeya Akter, Safaeid Hossain Arib
分类: cs.RO
发布日期: 2025-09-27 (更新: 2026-02-03)
💡 一句话要点
LAGEA:基于语言引导的具身智能体用于机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 强化学习 视觉语言模型 语言引导 具身智能 错误反馈 奖励塑造
📋 核心要点
- 现有机器人操作方法缺乏从自身错误中学习的有效机制,阻碍了其泛化能力和效率。
- LAGEA利用视觉语言模型生成情景化的语言反馈,指导强化学习智能体诊断错误并改进策略。
- 实验表明,LAGEA在多个机器人操作任务上显著提升了成功率和收敛速度,验证了语言反馈的有效性。
📝 摘要(中文)
机器人操作受益于描述目标的基础模型,但目前的智能体仍然缺乏从自身错误中学习的有效方法。本文探讨了自然语言是否可以作为反馈,一种错误推理信号,帮助具身智能体诊断错误并纠正方向。我们提出了LAGEA(Language Guided Embodied Agents),该框架将视觉语言模型(VLM)中情景化的、模式约束的反馈转化为强化学习的时间对齐指导。LAGEA用简洁的语言总结每次尝试,定位轨迹中的关键时刻,在共享表示中将反馈与视觉状态对齐,并将目标进度和反馈一致性转化为有界的、逐步的塑造奖励,其影响由自适应的、感知失败的系数调节。这种设计在探索需要指导时尽早产生密集的信号,并在能力增长时逐渐减弱。在Meta-World MT10和Robotic Fetch具身操作基准测试中,LAGEA在随机目标上的平均成功率比最先进的方法提高了9.0%,在固定目标上提高了5.3%,在fetch任务上提高了17%,并且收敛速度更快。这些结果支持了我们的假设:当语言被结构化并与时间对齐时,它是一种有效的机制,可以教导机器人自我反思错误并做出更好的选择。
🔬 方法详解
问题定义:现有机器人操作方法在从错误中学习方面存在不足。传统的强化学习方法通常依赖于稀疏或延迟的奖励信号,难以有效地指导智能体探索和改进策略。此外,现有方法缺乏对错误原因的理解,难以进行有效的自我反思和纠正。因此,如何让机器人能够理解自身的错误,并从中学习,是当前机器人操作领域面临的一个重要挑战。
核心思路:LAGEA的核心思路是利用自然语言作为反馈信号,指导机器人从错误中学习。具体来说,LAGEA使用视觉语言模型(VLM)对机器人的操作过程进行分析,并生成简洁的语言描述,指出操作中的错误和改进方向。这些语言反馈被转化为强化学习的奖励信号,引导智能体朝着正确的方向探索。通过将语言反馈与视觉状态对齐,LAGEA能够让智能体更好地理解错误的原因,并进行有效的自我反思。
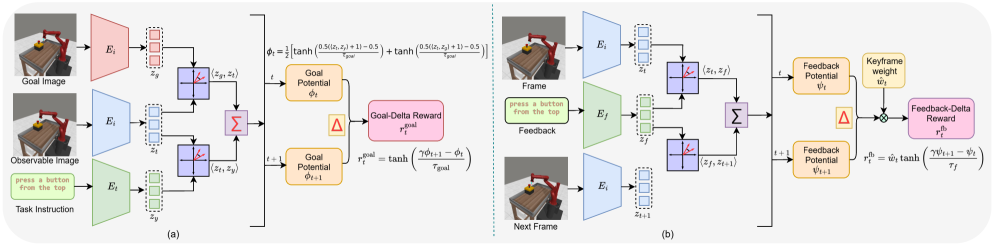
技术框架:LAGEA的整体框架包括以下几个主要模块:1) 视觉语言模型(VLM):用于分析机器人的操作过程,并生成语言反馈。2) 状态表示模块:用于将视觉状态和语言反馈编码为统一的表示。3) 强化学习模块:用于根据奖励信号学习最优策略。4) 奖励塑造模块:用于将语言反馈转化为强化学习的奖励信号,并根据智能体的表现动态调整奖励的权重。整个流程是,机器人执行动作后,VLM生成语言反馈,状态表示模块将视觉状态和语言反馈编码,奖励塑造模块生成奖励信号,强化学习模块根据奖励信号更新策略。
关键创新:LAGEA的关键创新在于利用语言作为反馈信号,指导机器人从错误中学习。与传统的强化学习方法相比,LAGEA能够提供更丰富、更细粒度的反馈信息,帮助智能体更好地理解错误的原因,并进行有效的自我反思。此外,LAGEA还提出了一种自适应的奖励塑造方法,能够根据智能体的表现动态调整奖励的权重,从而提高学习效率。
关键设计:LAGEA的关键设计包括:1) 使用预训练的视觉语言模型(如CLIP)生成语言反馈。2) 设计了一种基于Transformer的状态表示模块,用于将视觉状态和语言反馈编码为统一的表示。3) 提出了一种自适应的奖励塑造方法,根据目标进度和反馈一致性动态调整奖励的权重。奖励函数的设计是关键,它将VLM的反馈转化为可用于强化学习的信号,并且通过自适应系数来平衡探索和利用。
🖼️ 关键图片

📊 实验亮点
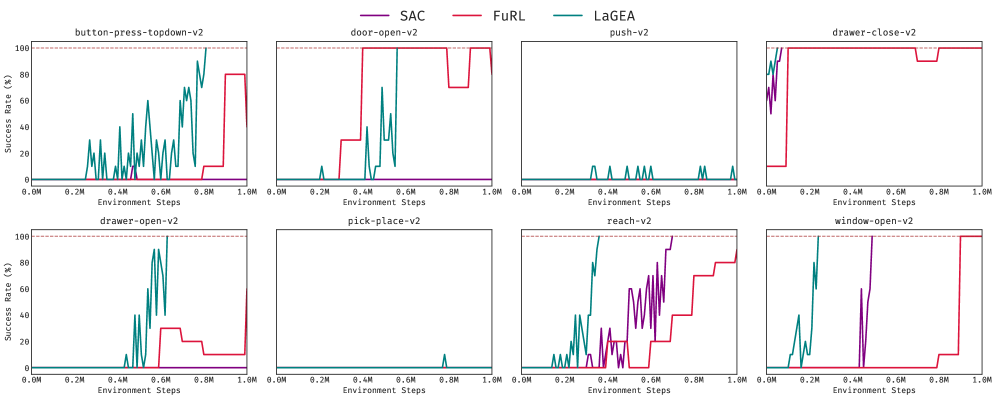
LAGEA在Meta-World MT10和Robotic Fetch基准测试中取得了显著的性能提升。在随机目标任务上,LAGEA的平均成功率比最先进的方法提高了9.0%;在固定目标任务上,提高了5.3%;在Fetch任务上,提高了17%。此外,LAGEA的收敛速度也明显快于其他方法,表明其具有更高的学习效率。
🎯 应用场景
LAGEA具有广泛的应用前景,可应用于各种机器人操作任务,如家庭服务、工业自动化、医疗辅助等。通过利用语言反馈,LAGEA能够显著提高机器人的学习效率和泛化能力,使其能够更好地适应复杂多变的环境。未来,LAGEA有望成为机器人操作领域的一项关键技术,推动机器人技术的进一步发展。
📄 摘要(原文)
Robotic manipulation benefits from foundation models that describe goals, but today's agents still lack a principled way to learn from their own mistakes. We ask whether natural language can serve as feedback, an error-reasoning signal that helps embodied agents diagnose what went wrong and correct course. We introduce LAGEA (Language Guided Embodied Agents), a framework that turns episodic, schema-constrained reflections from a vision language model (VLM) into temporally grounded guidance for reinforcement learning. LAGEA summarizes each attempt in concise language, localizes the decisive moments in the trajectory, aligns feedback with visual state in a shared representation, and converts goal progress and feedback agreement into bounded, step-wise shaping rewards whose influence is modulated by an adaptive, failure-aware coefficient. This design yields dense signals early when exploration needs direction and gracefully recedes as competence grows. On the Meta-World MT10 and Robotic Fetch embodied manipulation benchmark, LAGEA improves average success over the state-of-the-art (SOTA) methods by 9.0% on random goals, 5.3% on fixed goals, and 17% on fetch tasks, while converging faster. These results support our hypothesis: language, when structured and grounded in time, is an effective mechanism for teaching robots to self-reflect on mistakes and make better choices.