FTACT: Force Torque aware Action Chunking Transformer for Pick-and-Reorient Bottle Task
作者: Ryo Watanabe, Maxime Alvarez, Pablo Ferreiro, Pavel Savkin, Genki Sano
分类: cs.RO
发布日期: 2025-09-27
💡 一句话要点
FTACT:力/力矩感知的动作分块Transformer用于瓶子抓取与重定向任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 力/力矩传感 模仿学习 动作分块Transformer 多模态融合 机器人操作 零售自动化 接触力感知
📋 核心要点
- 零售环境中机械臂在处理富含接触的瓶子扶正任务时,纯视觉信息不足以应对细微的接触事件。
- 论文提出一种多模态模仿学习策略FTACT,结合力/力矩传感器增强动作分块Transformer,实现图像、关节状态和力/力矩的端到端学习。
- 在真实机器人平台上,FTACT通过检测和利用接触转换,显著提升了瓶子抓取和重定向任务的成功率。
📝 摘要(中文)
零售环境中越来越多地部署机械臂,但富含接触的边缘情况仍然会触发代价高昂的人工遥操作。一个典型的例子是扶正倾倒的饮料瓶,在这种情况下,纯视觉线索通常不足以解决精确操作所需的细微接触事件。我们提出了一种多模态模仿学习策略,该策略使用力/力矩传感增强了动作分块Transformer,从而实现了图像、关节状态以及力和力矩的端到端学习。在Telexistence Inc.的单臂平台Ghost上部署后,我们的方法通过检测和利用按压和放置过程中的接触转换,改进了瓶子的抓取和重定向任务。硬件实验表明,与匹配ACT观察空间的基线相比,我们的方法提高了任务成功率,并且实验表明,在视觉可观察性有限的按压和放置阶段,力和力矩信号是有益的,这支持了使用交互力作为富含接触技能的补充模态。结果表明,通过将现代模仿学习架构与轻量级力/力矩传感相结合,可以实现零售操作的实际扩展。
🔬 方法详解
问题定义:论文旨在解决零售环境中机械臂在执行瓶子抓取和重定向任务时,由于视觉信息不足而难以处理细微接触事件的问题。现有方法依赖纯视觉信息,无法准确感知和利用接触力,导致操作失败或需要人工干预。
核心思路:论文的核心思路是将力/力矩传感器信息融入模仿学习框架,利用力/力矩信号作为视觉信息的补充,从而更准确地感知和利用接触事件。通过学习力/力矩与动作之间的关系,机器人可以更好地执行需要精确接触的操作。
技术框架:FTACT (Force Torque aware Action Chunking Transformer) 的整体架构基于Action Chunking Transformer (ACT),并在此基础上增加了力/力矩传感器的输入。输入包括图像、关节状态以及力/力矩数据。模型通过Transformer结构学习这些多模态信息之间的关系,并预测一系列动作块。
关键创新:论文的关键创新在于将力/力矩信息融入到基于Transformer的模仿学习框架中。通过这种方式,模型可以同时利用视觉信息和力/力矩信息,从而更准确地感知和利用接触事件。这种多模态融合的方法显著提高了机器人处理富含接触任务的能力。
关键设计:FTACT的关键设计包括:1) 使用力/力矩传感器获取机器人与环境之间的交互力信息;2) 将力/力矩信息与视觉信息和关节状态信息进行融合,作为Transformer的输入;3) 使用模仿学习方法训练模型,使其能够学习专家演示中的动作序列;4) 损失函数的设计旨在最小化预测动作与专家动作之间的差异,同时考虑力/力矩信息的约束。
🖼️ 关键图片
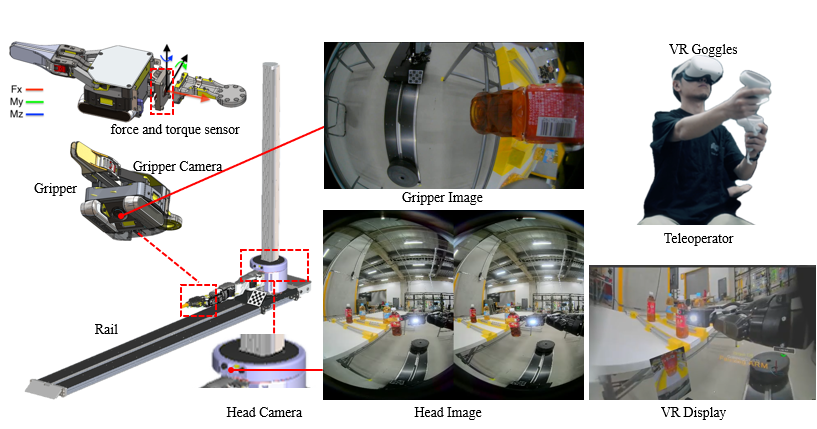
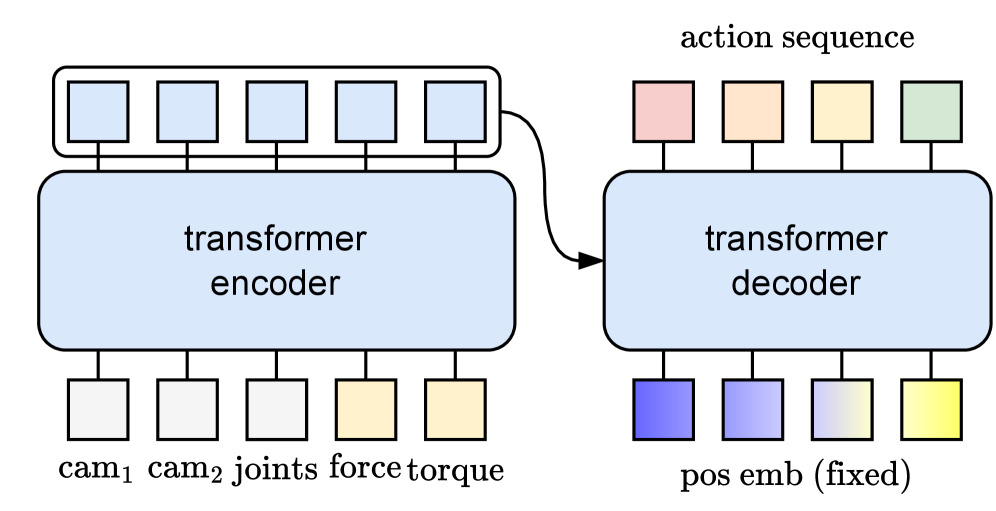
📊 实验亮点
实验结果表明,FTACT在瓶子抓取和重定向任务中显著优于基线方法。与仅使用视觉信息的ACT相比,FTACT的任务成功率得到了显著提升,尤其是在按压和放置阶段,力/力矩信号的加入起到了关键作用。这些结果验证了力/力矩信息作为视觉信息补充的有效性,并表明FTACT是一种实用的零售操作解决方案。
🎯 应用场景
该研究成果可应用于零售、仓储等场景,提升机械臂在复杂环境下的操作能力,例如处理摆放不规则的商品、执行需要精细接触的操作等。通过降低对纯视觉信息的依赖,可以减少人工干预,提高自动化水平,降低运营成本。未来,该技术有望扩展到其他需要力觉反馈的机器人应用领域,如医疗手术、精密装配等。
📄 摘要(原文)
Manipulator robots are increasingly being deployed in retail environments, yet contact rich edge cases still trigger costly human teleoperation. A prominent example is upright lying beverage bottles, where purely visual cues are often insufficient to resolve subtle contact events required for precise manipulation. We present a multimodal Imitation Learning policy that augments the Action Chunking Transformer with force and torque sensing, enabling end-to-end learning over images, joint states, and forces and torques. Deployed on Ghost, single-arm platform by Telexistence Inc, our approach improves Pick-and-Reorient bottle task by detecting and exploiting contact transitions during pressing and placement. Hardware experiments demonstrate greater task success compared to baseline matching the observation space of ACT as an ablation and experiments indicate that force and torque signals are beneficial in the press and place phases where visual observability is limited, supporting the use of interaction forces as a complementary modality for contact rich skills. The results suggest a practical path to scaling retail manipulation by combining modern imitation learning architectures with lightweight force and torque sensing.