Robot Learning from Any Images
作者: Siheng Zhao, Jiageng Mao, Wei Chow, Zeyu Shangguan, Tianheng Shi, Rong Xue, Yuxi Zheng, Yijia Weng, Yang You, Daniel Seita, Leonidas Guibas, Sergey Zakharov, Vitor Guizilini, Yue Wang
分类: cs.RO, cs.CV, cs.LG
发布日期: 2025-09-26 (更新: 2025-10-08)
备注: CoRL 2025 camera ready
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
RoLA:从任意图像生成交互式物理机器人环境,实现大规模机器人数据生成。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人学习 单视图重建 物理仿真 数据生成 视觉融合 图像到环境 强化学习 机器人控制
📋 核心要点
- 现有机器人学习方法依赖于昂贵的硬件或耗时的数字资产创建,限制了数据规模和泛化能力。
- RoLA通过单张图像恢复物理场景,并结合视觉融合技术,快速生成大规模、逼真的机器人交互数据。
- 实验证明RoLA在机器人数据生成、互联网图像学习以及实物到仿真到实物的迁移中表现出强大的通用性。
📝 摘要(中文)
本文介绍了一个名为RoLA的框架,该框架可以将任何真实场景图像转换为可交互的、具有物理属性的机器人环境。与以往方法不同,RoLA直接作用于单张图像,无需额外的硬件或数字资产。我们的框架通过从各种图像源(包括相机拍摄、机器人数据集和互联网图像)在几分钟内生成海量的视觉运动机器人演示,从而普及了机器人数据的生成。该方法的核心是将单视图物理场景恢复的新方法与用于照片级真实感数据收集的高效视觉融合策略相结合。我们展示了RoLA在可扩展的机器人数据生成和增强、从互联网图像进行机器人学习以及用于机械臂和人形机器人的单图像实物到仿真到实物系统等应用中的多功能性。
🔬 方法详解
问题定义:现有机器人学习方法通常需要大量的真实世界数据或精确的3D环境模型。获取真实世界数据成本高昂,而构建精确的3D模型则耗时费力。此外,这些方法难以利用互联网上丰富的图像资源进行机器人学习。因此,如何从任意图像中提取有用的信息,并将其转化为可用于机器人学习的环境,是一个重要的挑战。
核心思路:RoLA的核心思路是将单张图像转化为一个可交互的、具有物理属性的机器人环境。通过单视图物理场景恢复技术,从图像中估计场景的几何和物理属性。然后,利用视觉融合策略,将机器人模型融入到场景中,并模拟机器人与环境的交互。这样,就可以从任意图像中生成大量的机器人交互数据。
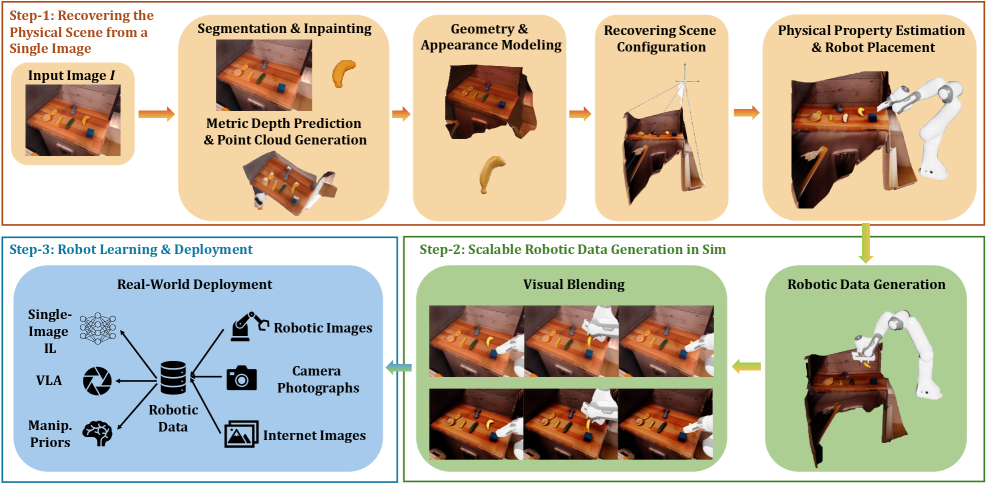
技术框架:RoLA框架主要包含两个阶段:1) 单视图物理场景恢复:该阶段从单张图像中估计场景的深度、表面法线、材质等物理属性。可以使用现有的单视图深度估计、表面法线估计等技术。2) 视觉融合与交互模拟:该阶段将机器人模型融入到恢复的场景中,并模拟机器人与环境的交互。可以使用现有的物理引擎(如PyBullet、MuJoCo)进行模拟。此外,还需要设计合适的视觉融合策略,以保证生成的数据具有照片级真实感。
关键创新:RoLA的关键创新在于它能够直接从单张图像生成可交互的机器人环境,而无需额外的硬件或数字资产。这使得RoLA可以利用互联网上大量的图像资源进行机器人学习,从而大大降低了数据获取的成本。此外,RoLA还提出了一种高效的视觉融合策略,可以生成具有照片级真实感的数据。
关键设计:RoLA的关键设计包括:1) 使用深度学习模型进行单视图物理场景恢复,例如使用卷积神经网络估计深度图和表面法线。2) 设计合适的视觉融合策略,例如使用图像合成技术将机器人模型无缝地融入到场景中。3) 使用物理引擎模拟机器人与环境的交互,例如使用力/位姿控制策略控制机器人的运动。
🖼️ 关键图片

📊 实验亮点
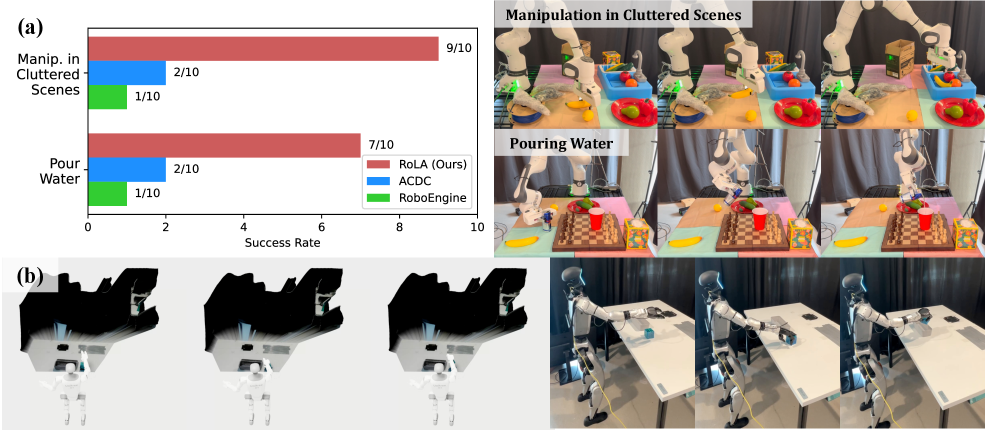
RoLA能够从任意图像生成高质量的机器人交互数据,显著降低了数据获取成本。实验结果表明,使用RoLA生成的数据训练的机器人控制策略,在真实世界中具有良好的泛化能力。例如,RoLA可以用于训练机械臂抓取物体,或者训练人形机器人行走。
🎯 应用场景
RoLA具有广泛的应用前景,包括:1) 大规模机器人数据生成与增强,用于训练更鲁棒的机器人控制策略。2) 从互联网图像进行机器人学习,利用互联网上丰富的图像资源提升机器人的泛化能力。3) 单图像实物到仿真到实物的迁移,实现机器人控制策略在真实世界中的快速部署。该技术有望加速机器人学习的研究进展,并推动机器人在各个领域的应用。
📄 摘要(原文)
We introduce RoLA, a framework that transforms any in-the-wild image into an interactive, physics-enabled robotic environment. Unlike previous methods, RoLA operates directly on a single image without requiring additional hardware or digital assets. Our framework democratizes robotic data generation by producing massive visuomotor robotic demonstrations within minutes from a wide range of image sources, including camera captures, robotic datasets, and Internet images. At its core, our approach combines a novel method for single-view physical scene recovery with an efficient visual blending strategy for photorealistic data collection. We demonstrate RoLA's versatility across applications like scalable robotic data generation and augmentation, robot learning from Internet images, and single-image real-to-sim-to-real systems for manipulators and humanoids. Video results are available at https://sihengz02.github.io/RoLA .