WoW: Towards a World omniscient World model Through Embodied Interaction
作者: Xiaowei Chi, Peidong Jia, Chun-Kai Fan, Xiaozhu Ju, Weishi Mi, Kevin Zhang, Zhiyuan Qin, Wanxin Tian, Kuangzhi Ge, Hao Li, Zezhong Qian, Anthony Chen, Qiang Zhou, Yueru Jia, Jiaming Liu, Yong Dai, Qingpo Wuwu, Chengyu Bai, Yu-Kai Wang, Ying Li, Lizhang Chen, Yong Bao, Zhiyuan Jiang, Jiacheng Zhu, Kai Tang, Ruichuan An, Yulin Luo, Qiuxuan Feng, Siyuan Zhou, Chi-min Chan, Chengkai Hou, Wei Xue, Sirui Han, Yike Guo, Shanghang Zhang, Jian Tang
分类: cs.RO, cs.CV, cs.MM
发布日期: 2025-09-26 (更新: 2025-10-16)
💡 一句话要点
WoW:通过具身交互构建世界全知世界模型,提升物理因果理解
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 具身交互 物理直觉 生成式模型 机器人学习
📋 核心要点
- 现有视频模型依赖被动观察,难以理解物理因果关系,阻碍了对世界的深入认知。
- WoW通过大规模机器人交互数据训练生成式世界模型,使模型能够主动学习物理规律。
- WoW在物理一致性和因果推理方面表现出色,证明了具身交互对提升物理直觉的重要性。
📝 摘要(中文)
本文提出了WoW,一个基于200万机器人交互轨迹训练的140亿参数生成式世界模型。研究表明,该模型对物理的理解表现为合理结果的概率分布,导致随机不稳定性和物理幻觉。为了约束模型并提升物理真实性,引入了SOPHIA,利用视觉-语言模型智能体评估DiT生成的输出,并通过迭代优化语言指令来指导改进。此外,共同训练的逆动力学模型将这些改进的计划转化为可执行的机器人动作,从而闭合了从想象到行动的循环。论文还提出了WoWBench,一个新的基准测试,专注于视频中的物理一致性和因果推理。WoW在人类和自主评估中均取得了最先进的性能,展示了在物理因果关系、碰撞动力学和物体永存方面的强大能力。该工作为大规模真实世界交互是发展人工智能物理直觉的基石提供了系统性证据。模型、数据和基准测试将开源。
🔬 方法详解
问题定义:现有视频生成模型,如Sora,主要依赖于被动观察学习,缺乏与环境的真实交互,导致其在理解物理世界的因果关系方面存在不足,容易产生不符合物理规律的幻觉。因此,如何让AI模型通过主动交互学习物理世界的规律,构建更符合真实世界的物理直觉是本文要解决的核心问题。
核心思路:论文的核心思路是通过大规模的真实机器人交互数据来训练一个生成式世界模型。这种方式模拟了人类通过与环境交互来学习物理规律的过程。通过让模型观察和参与大量的物理交互,使其能够学习到物理世界的因果关系,从而提升其对物理世界的理解和预测能力。
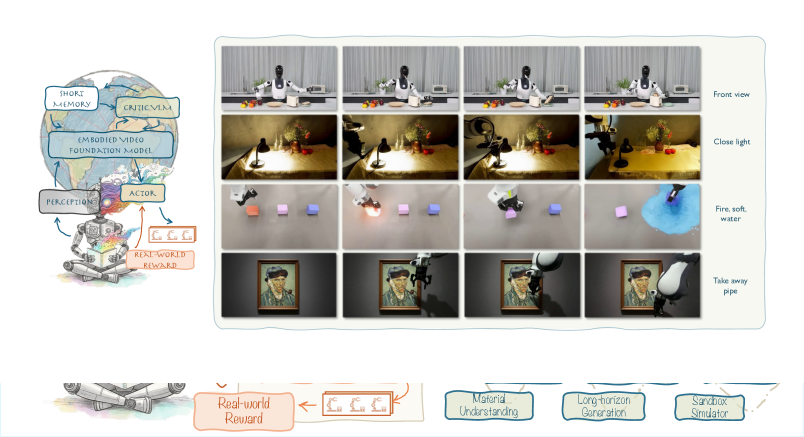
技术框架:WoW的整体框架包含以下几个主要模块:1) 数据收集:通过机器人与环境进行大量的交互,收集包含物理交互信息的轨迹数据。2) 世界模型训练:使用收集到的数据训练一个大规模的生成式世界模型(基于DiT架构),使其能够预测在给定状态和动作下的未来状态。3) SOPHIA优化:利用视觉-语言模型智能体SOPHIA评估世界模型生成的视频,并根据评估结果迭代优化语言指令,从而引导世界模型生成更符合物理规律的视频。4) 逆动力学模型:训练一个逆动力学模型,将SOPHIA优化后的语言指令转化为可执行的机器人动作,实现从想象到行动的闭环。
关键创新:论文的关键创新在于:1) 大规模具身交互数据:使用了大规模的真实机器人交互数据进行训练,这使得模型能够学习到更丰富的物理交互信息。2) SOPHIA引导的优化:利用视觉-语言模型智能体SOPHIA来评估和优化世界模型的生成结果,从而提升了生成视频的物理真实性。3) 闭环控制:通过逆动力学模型将优化后的计划转化为可执行的机器人动作,实现了从想象到行动的闭环控制。
关键设计:WoW模型使用了140亿参数的DiT架构作为生成式世界模型。SOPHIA使用预训练的视觉-语言模型来评估生成视频的物理合理性,并生成反馈信息。逆动力学模型使用Transformer架构,将语言指令映射到机器人动作。论文还设计了WoWBench基准测试,用于评估模型在物理一致性和因果推理方面的能力。具体的损失函数和训练细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
WoW在WoWBench基准测试中取得了最先进的性能,在物理因果关系、碰撞动力学和物体永存等方面表现出强大的能力。通过人类和自主评估,证明了WoW在生成物理上合理的视频方面的优越性。与现有方法相比,WoW能够更好地理解和预测物理世界的行为,减少了物理幻觉的产生。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。通过构建具有物理直觉的世界模型,可以使机器人在复杂环境中更好地进行决策和规划,提高其适应性和鲁棒性。此外,该研究也有助于开发更智能的虚拟助手和游戏AI,使其能够更真实地模拟物理世界的行为。
📄 摘要(原文)
Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.