MimicDreamer: Aligning Human and Robot Demonstrations for Scalable VLA Training
作者: Haoyun Li, Ivan Zhang, Runqi Ouyang, Xiaofeng Wang, Zheng Zhu, Zhiqin Yang, Zhentao Zhang, Boyuan Wang, Chaojun Ni, Wenkang Qin, Xinze Chen, Yun Ye, Guan Huang, Zhenbo Song, Xingang Wang
分类: cs.RO, cs.AI
发布日期: 2025-09-26 (更新: 2025-09-29)
💡 一句话要点
MimicDreamer:对齐人类与机器人演示,实现可扩展的VLA模型训练
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人学习 模仿学习 领域自适应 视频扩散模型
📋 核心要点
- 现有VLA模型训练依赖昂贵的机器人交互数据,而人类演示视频虽然易得,但与机器人视频存在显著领域差异。
- MimicDreamer框架通过视觉、视角和动作对齐,将人类演示转化为机器人可用的监督信息,用于VLA模型训练。
- 实验表明,仅使用合成数据训练的VLA模型即可在真实机器人上实现少样本执行,且性能优于仅使用真实机器人数据训练的模型。
📝 摘要(中文)
视觉-语言-动作(VLA)模型的能力源于多样化的训练数据,但收集具身机器人交互数据成本高昂。相比之下,人类演示视频更易于获取且成本效益更高,并且最近的研究证实了它们在训练VLA模型中的有效性。然而,人类视频和机器人执行的视频之间存在显著的领域差距,包括不稳定的相机视角、人类手部和机械臂之间的视觉差异以及运动动力学的差异。为了弥合这一差距,我们提出了MimicDreamer框架,该框架通过联合对齐视觉、视角和动作,将快速、低成本的人类演示转化为机器人可用的监督信息,从而直接支持策略训练。对于视觉对齐,我们提出了H2R Aligner,这是一种视频扩散模型,通过转移人类操作视频中的运动来生成高保真机器人演示视频。对于视角稳定,我们提出了EgoStabilizer,它通过单应性变换来规范化自我中心视频,并修复由扭曲引起的遮挡和失真。对于动作对齐,我们将人类手部轨迹映射到机器人坐标系,并应用约束逆运动学求解器来生成具有精确姿势跟踪的可行的、低抖动的关节命令。实验表明,仅在我们合成的人类到机器人视频上训练的VLA模型可以在真实机器人上实现少样本执行。此外,与仅在真实机器人数据上训练的模型相比,使用人类数据进行缩放训练可以显著提高性能;我们的方法在六个代表性操作任务中将平均成功率提高了14.7%。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作(VLA)模型训练中,机器人交互数据获取成本高昂的问题。现有方法难以有效利用低成本的人类演示数据,因为人类演示与机器人执行之间存在视觉差异、视角差异和运动动力学差异,直接使用会导致VLA模型性能下降。
核心思路:论文的核心思路是通过构建一个数据转换框架,将易于获取的人类演示视频转换为机器人可用的高质量训练数据。该框架通过视觉对齐、视角稳定和动作对齐三个关键步骤,弥合人类演示与机器人执行之间的领域差距,从而使VLA模型能够有效地从人类数据中学习。
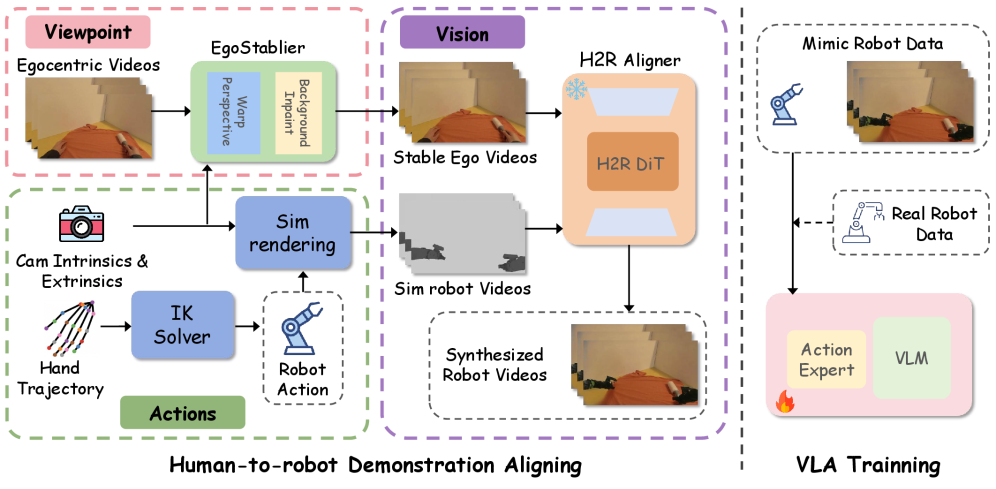
技术框架:MimicDreamer框架包含三个主要模块:H2R Aligner、EgoStabilizer和动作对齐模块。首先,H2R Aligner是一个视频扩散模型,用于将人类操作视频转换为高保真机器人演示视频,实现视觉对齐。其次,EgoStabilizer通过单应性变换规范化自我中心视角视频,并修复扭曲造成的遮挡和失真,实现视角稳定。最后,动作对齐模块将人类手部轨迹映射到机器人坐标系,并使用约束逆运动学求解器生成可行的机器人关节命令。
关键创新:该论文的关键创新在于提出了一个完整的框架,能够同时解决人类演示数据在视觉、视角和动作三个方面与机器人数据的差异。H2R Aligner利用视频扩散模型生成逼真的机器人视频,EgoStabilizer实现了鲁棒的视角稳定,动作对齐模块则保证了生成的机器人动作的可执行性。这种多方面的对齐方法使得VLA模型能够有效地从人类数据中学习,并泛化到真实机器人环境。
关键设计:H2R Aligner使用视频扩散模型,通过学习人类动作的条件分布来生成机器人视频。EgoStabilizer使用单应性变换来校正视角,并使用图像修复技术来填充遮挡区域。动作对齐模块使用约束逆运动学求解器,确保生成的机器人关节命令满足机器人的运动学约束,并具有较低的抖动。
🖼️ 关键图片

📊 实验亮点
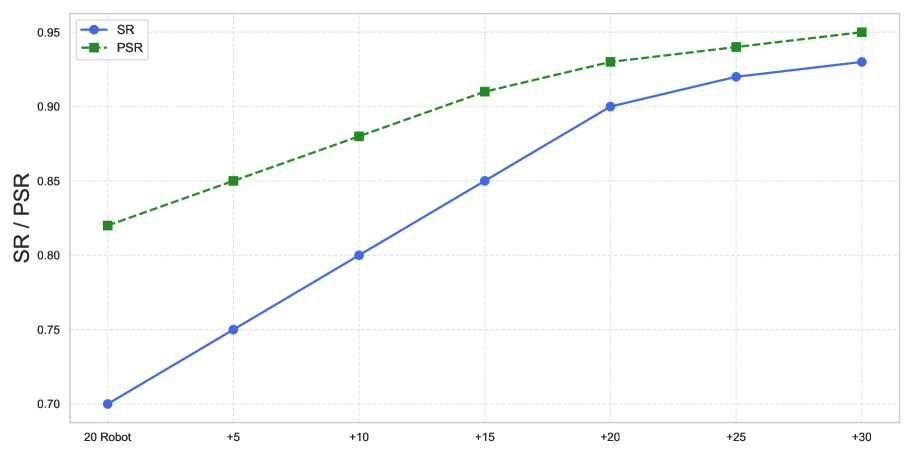
实验结果表明,仅使用MimicDreamer合成数据训练的VLA模型即可在真实机器人上实现少样本执行。与仅使用真实机器人数据训练的模型相比,使用合成数据进行缩放训练可以显著提高性能,在六个代表性操作任务中,平均成功率提高了14.7%。这表明MimicDreamer能够有效地弥合人类演示与机器人执行之间的领域差距。
🎯 应用场景
MimicDreamer框架可广泛应用于机器人操作技能学习领域,尤其是在数据收集成本高昂的场景下。该方法能够利用大量易于获取的人类演示数据,降低机器人训练的成本和时间,加速机器人在工业自动化、家庭服务等领域的应用。此外,该框架还可以用于生成更逼真的机器人仿真环境,从而促进机器人算法的开发和测试。
📄 摘要(原文)
Vision Language Action (VLA) models derive their generalization capability from diverse training data, yet collecting embodied robot interaction data remains prohibitively expensive. In contrast, human demonstration videos are far more scalable and cost-efficient to collect, and recent studies confirm their effectiveness in training VLA models. However, a significant domain gap persists between human videos and robot-executed videos, including unstable camera viewpoints, visual discrepancies between human hands and robotic arms, and differences in motion dynamics. To bridge this gap, we propose MimicDreamer, a framework that turns fast, low-cost human demonstrations into robot-usable supervision by jointly aligning vision, viewpoint, and actions to directly support policy training. For visual alignment, we propose H2R Aligner, a video diffusion model that generates high-fidelity robot demonstration videos by transferring motion from human manipulation footage. For viewpoint stabilization, EgoStabilizer is proposed, which canonicalizes egocentric videos via homography and inpaints occlusions and distortions caused by warping. For action alignment, we map human hand trajectories to the robot frame and apply a constrained inverse kinematics solver to produce feasible, low-jitter joint commands with accurate pose tracking. Empirically, VLA models trained purely on our synthesized human-to-robot videos achieve few-shot execution on real robots. Moreover, scaling training with human data significantly boosts performance compared to models trained solely on real robot data; our approach improves the average success rate by 14.7\% across six representative manipulation tasks.