DemoGrasp: Universal Dexterous Grasping from a Single Demonstration
作者: Haoqi Yuan, Ziye Huang, Ye Wang, Chuan Mao, Chaoyi Xu, Zongqing Lu
分类: cs.RO
发布日期: 2025-09-26
💡 一句话要点
DemoGrasp:基于单次演示的通用灵巧抓取方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 灵巧抓取 机器人操作 强化学习 轨迹编辑 模仿学习 通用抓取 单次演示
📋 核心要点
- 现有灵巧抓取方法依赖强化学习,但高维空间探索困难,需要复杂的奖励设计,导致泛化性不足。
- DemoGrasp从单次演示轨迹出发,通过编辑机器人动作适应新物体和姿态,简化了学习过程。
- 实验表明,DemoGrasp在模拟和真实环境中均表现出色,具有良好的泛化性和可迁移性。
📝 摘要(中文)
多指灵巧手的通用抓取是机器人操作中的一个根本性挑战。虽然最近的方法成功地使用强化学习(RL)学习了闭环抓取策略,但高维、长程探索的内在困难需要复杂的奖励和课程设计,这通常导致跨各种物体的次优解决方案。我们提出了DemoGrasp,一种简单而有效的学习通用灵巧抓取的方法。我们从抓取特定物体的单次成功演示轨迹开始,并通过编辑该轨迹中的机器人动作来适应新的物体和姿势:改变手腕姿势决定了抓取的位置,改变手部关节角度决定了抓取的方式。我们将这种轨迹编辑公式化为一个单步马尔可夫决策过程(MDP),并使用RL在模拟中并行优化数百个物体的通用策略,其奖励包括二元成功项和机器人-桌面碰撞惩罚。在模拟中,DemoGrasp在使用Shadow Hand的DexGraspNet对象上实现了95%的成功率,优于先前的最先进方法。它还显示出强大的可转移性,在仅使用175个对象进行训练的情况下,在六个未见过的对象数据集上的各种灵巧手形态上实现了84.6%的平均成功率。通过基于视觉的模仿学习,我们的策略成功地抓取了110个未见过的真实世界物体,包括小型、薄型物品。它可以推广到空间、背景和光照变化,支持RGB和深度输入,并扩展到杂乱场景中的语言引导抓取。
🔬 方法详解
问题定义:现有基于强化学习的灵巧抓取方法,在高维动作空间中探索效率低,需要精细设计的奖励函数和课程学习,难以泛化到不同物体和环境。因此,如何高效地学习通用的灵巧抓取策略是一个关键问题。
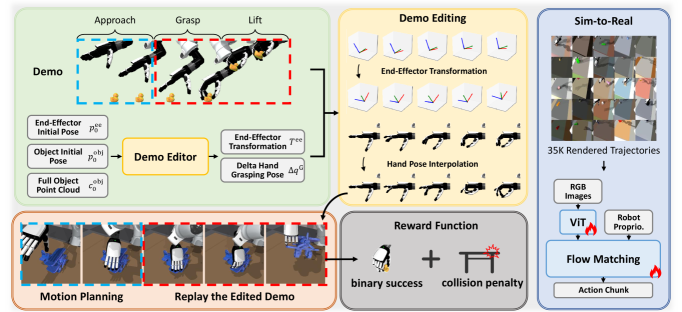
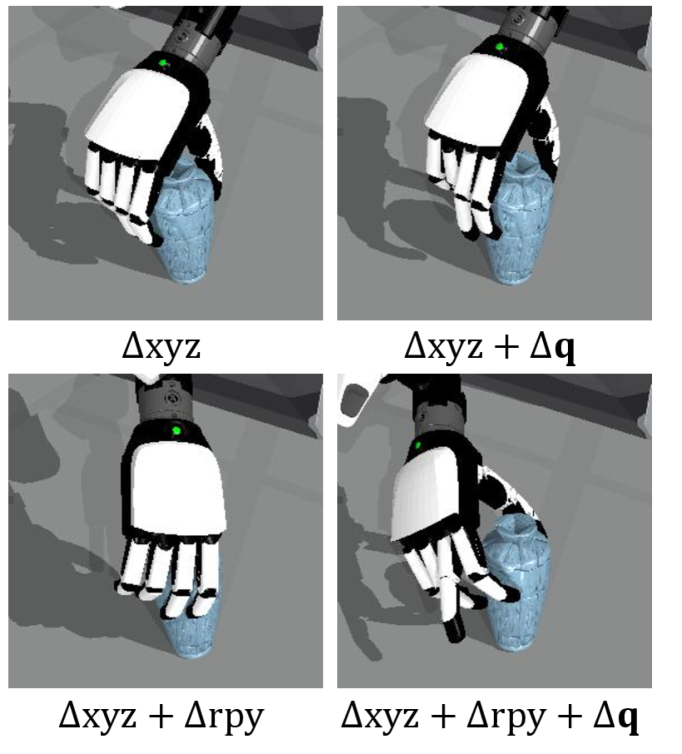
核心思路:DemoGrasp的核心思想是利用单次成功的抓取演示作为起点,通过编辑该轨迹中的机器人动作来适应新的物体和姿态。具体来说,通过调整手腕姿势来确定抓取位置,通过调整手部关节角度来确定抓取方式。这种方法将复杂的抓取策略学习问题简化为轨迹编辑问题,降低了学习难度。
技术框架:DemoGrasp的技术框架主要包括以下几个步骤:1) 从单次成功的抓取演示中获取初始轨迹;2) 将轨迹编辑问题建模为单步马尔可夫决策过程(MDP);3) 使用强化学习算法(如PPO)在模拟环境中并行优化数百个物体的通用策略;4) 通过视觉模仿学习将策略迁移到真实世界。
关键创新:DemoGrasp的关键创新在于将复杂的灵巧抓取策略学习问题转化为轨迹编辑问题,并利用单次演示作为学习的起点。这种方法避免了从零开始探索高维动作空间的困难,显著提高了学习效率和泛化能力。此外,该方法还能够通过调整手腕姿势和手部关节角度来实现对抓取位置和方式的精细控制。
关键设计:在MDP的奖励函数设计中,DemoGrasp采用了简单的二元成功奖励和机器人-桌面碰撞惩罚。在模拟环境中,使用了大量的物体进行并行训练,以提高策略的泛化能力。在视觉模仿学习中,使用了RGB和深度图像作为输入,并采用了数据增强技术来提高策略的鲁棒性。
🖼️ 关键图片
📊 实验亮点
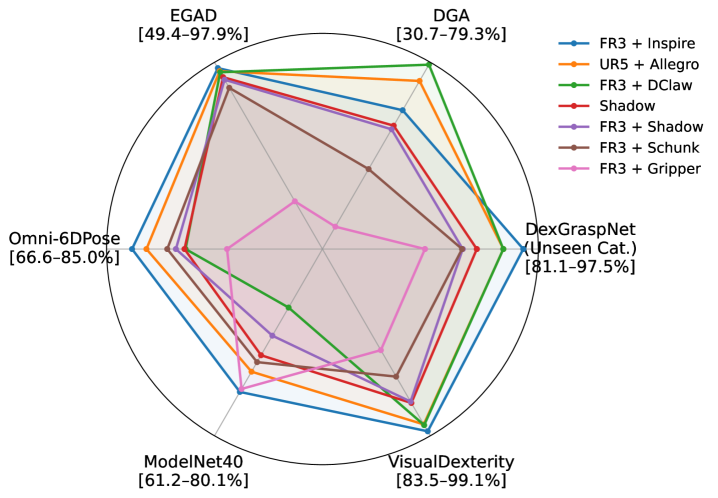
DemoGrasp在模拟环境中,使用Shadow Hand在DexGraspNet对象上实现了95%的抓取成功率,超越了现有技术水平。在六个未见过的对象数据集上,各种灵巧手形态的平均成功率达到84.6%,展示了强大的可迁移性。在真实世界中,成功抓取了110个未见过的物体,包括小型和薄型物体,验证了该方法在真实环境中的有效性。
🎯 应用场景
DemoGrasp具有广泛的应用前景,例如在智能制造中,机器人可以利用该方法快速学习抓取不同形状和大小的零件;在家庭服务机器人中,可以用于抓取各种日常用品;在医疗领域,可以用于辅助医生进行手术操作。该研究的实际价值在于降低了机器人灵巧抓取的学习成本,提高了抓取的效率和鲁棒性,为实现通用机器人操作奠定了基础。未来,该方法可以进一步扩展到更复杂的任务和环境,例如在拥挤的环境中进行抓取,或者在未知环境中进行探索和抓取。
📄 摘要(原文)
Universal grasping with multi-fingered dexterous hands is a fundamental challenge in robotic manipulation. While recent approaches successfully learn closed-loop grasping policies using reinforcement learning (RL), the inherent difficulty of high-dimensional, long-horizon exploration necessitates complex reward and curriculum design, often resulting in suboptimal solutions across diverse objects. We propose DemoGrasp, a simple yet effective method for learning universal dexterous grasping. We start from a single successful demonstration trajectory of grasping a specific object and adapt to novel objects and poses by editing the robot actions in this trajectory: changing the wrist pose determines where to grasp, and changing the hand joint angles determines how to grasp. We formulate this trajectory editing as a single-step Markov Decision Process (MDP) and use RL to optimize a universal policy across hundreds of objects in parallel in simulation, with a simple reward consisting of a binary success term and a robot-table collision penalty. In simulation, DemoGrasp achieves a 95% success rate on DexGraspNet objects using the Shadow Hand, outperforming previous state-of-the-art methods. It also shows strong transferability, achieving an average success rate of 84.6% across diverse dexterous hand embodiments on six unseen object datasets, while being trained on only 175 objects. Through vision-based imitation learning, our policy successfully grasps 110 unseen real-world objects, including small, thin items. It generalizes to spatial, background, and lighting changes, supports both RGB and depth inputs, and extends to language-guided grasping in cluttered scenes.