Action-aware Dynamic Pruning for Efficient Vision-Language-Action Manipulation
作者: Xiaohuan Pei, Yuxing Chen, Siyu Xu, Yunke Wang, Yuheng Shi, Chang Xu
分类: cs.RO, cs.AI
发布日期: 2025-09-26
💡 一句话要点
提出动作感知动态剪枝ADP,提升视觉-语言-动作模型在机器人操作中的效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉-语言-动作模型 动态剪枝 动作感知 多模态学习
📋 核心要点
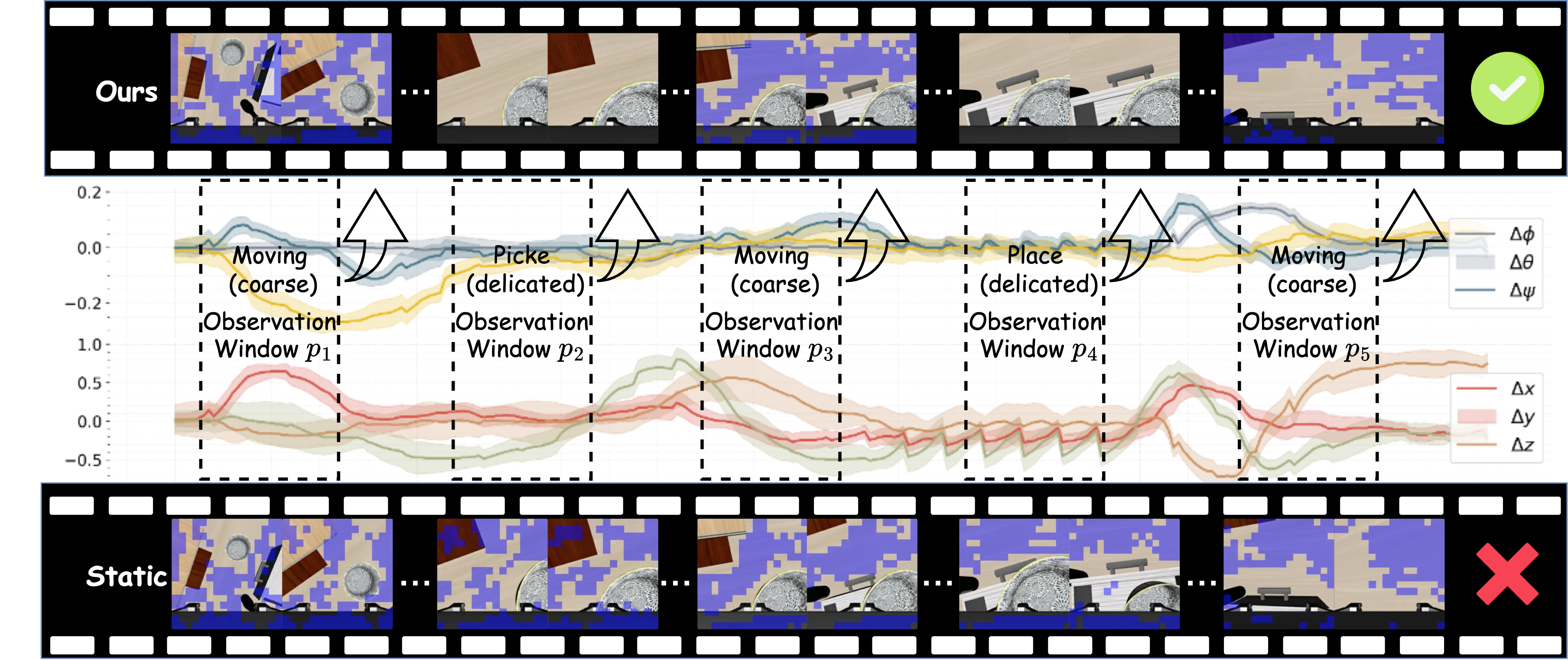
- 现有VLA模型在机器人操作中计算成本高昂,尤其是在密集视觉token的注意力机制上,且忽略了不同操作阶段视觉冗余度的差异。
- ADP框架通过动作感知的轨迹门控机制,根据机器人操作的动态变化,自适应地调整视觉token的保留率,实现计算效率和感知精度的平衡。
- 实验结果表明,ADP在降低计算复杂度的同时,显著提升了VLA模型在机器人操作任务中的成功率和推理速度。
📝 摘要(中文)
本文提出了一种名为动作感知动态剪枝(ADP)的多模态剪枝框架,旨在提高视觉-语言-动作(VLA)模型在机器人操作中的推理效率。该方法观察到视觉token的冗余度在粗略操作阶段高于精细操作阶段,并且与动作动态密切相关。ADP集成了文本驱动的token选择和动作感知的轨迹门控,利用过去的运动窗口来调整token保留率,从而在不同操作阶段平衡计算效率和感知精度。在LIBERO套件和真实场景中的实验表明,ADP显著降低了FLOPs和动作推理延迟(例如,在OpenVLA-OFT上加速1.35倍),同时保持了具有竞争力的成功率(例如,OpenVLA提升25.8%),为高效机器人策略提供了一种简单的插件式路径,提升了机器人操作的效率和性能。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作(VLA)模型在机器人操作中推理效率低下的问题。现有的方法主要集中在减少VLA模型内部的视觉冗余,但忽略了机器人操作不同阶段视觉冗余度的差异性,尤其是在粗略操作和精细操作阶段,视觉token的冗余度存在显著差异。这种静态的剪枝策略无法充分利用操作过程中的动态信息,导致效率提升有限。
核心思路:论文的核心思路是利用机器人操作的动作动态信息,自适应地调整视觉token的保留率。作者观察到视觉token的冗余度与动作动态密切相关,因此提出了一种动作感知的动态剪枝(ADP)框架。通过分析过去的动作轨迹,ADP可以预测当前操作阶段的视觉信息需求,并相应地调整token的剪枝比例,从而在保证感知精度的前提下,最大程度地减少计算量。
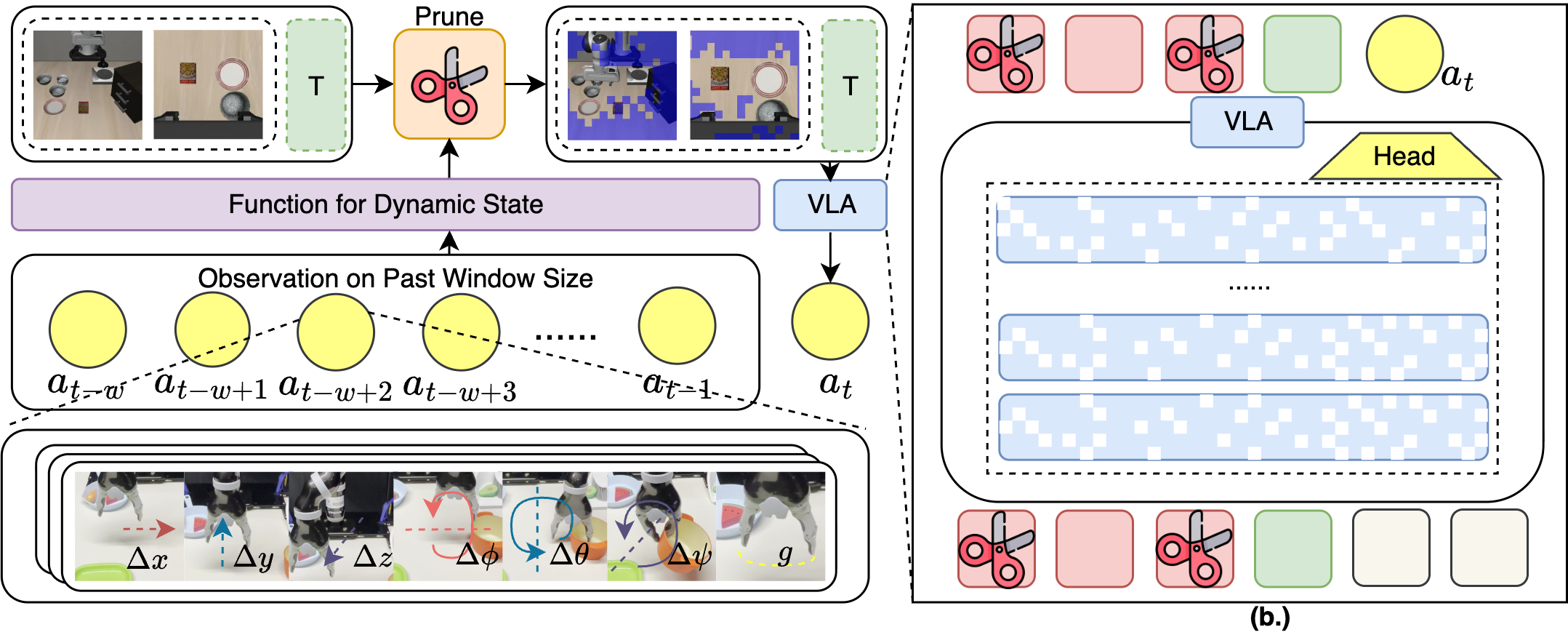
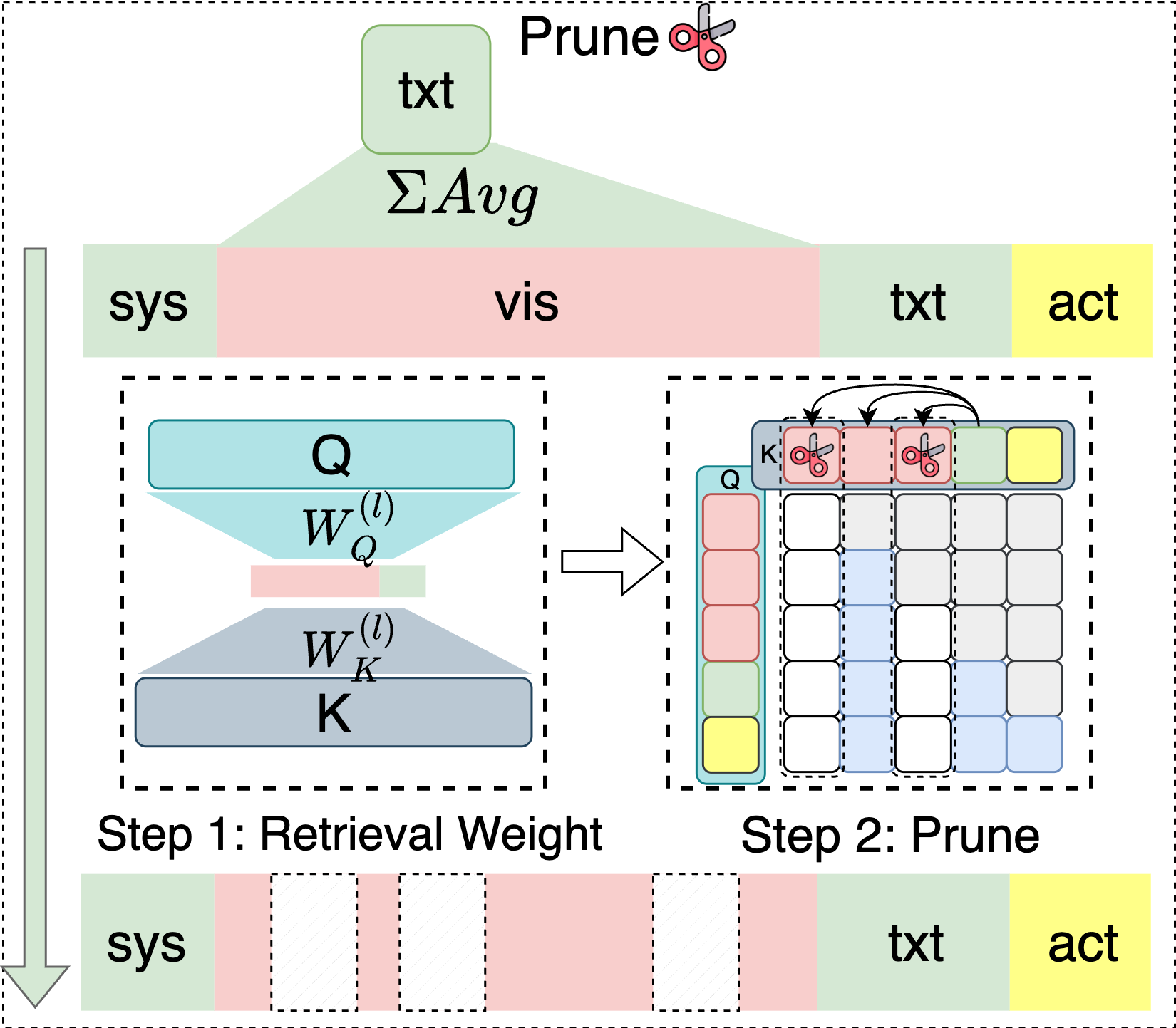
技术框架:ADP框架主要包含两个核心模块:文本驱动的token选择和动作感知的轨迹门控。首先,文本驱动的token选择模块根据文本指令,初步筛选出与任务相关的视觉token。然后,动作感知的轨迹门控模块利用过去的动作轨迹,对token的重要性进行重新评估,并根据动作动态自适应地调整token的保留率。整个框架可以作为一个插件,集成到现有的VLA模型中。
关键创新:ADP的关键创新在于引入了动作感知的动态剪枝机制。与传统的静态剪枝方法不同,ADP能够根据机器人操作的动态变化,自适应地调整视觉token的保留率。这种动态调整机制使得模型能够在不同操作阶段平衡计算效率和感知精度,从而显著提升了整体的推理效率。
关键设计:动作感知的轨迹门控模块是ADP的关键组成部分。该模块使用一个门控网络,以过去的动作轨迹作为输入,输出一个门控信号,用于调整token的保留率。门控网络的具体结构和训练方式未知。损失函数的设计目标是平衡计算效率和感知精度,具体形式未知。论文中提到使用过去的运动窗口来调整token保留率,窗口大小等参数设置未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ADP方法在LIBERO套件和真实场景中均取得了显著的性能提升。例如,在OpenVLA-OFT模型上,ADP实现了1.35倍的加速,同时在OpenVLA模型上,成功率提升了25.8%。这些结果表明,ADP能够有效地降低计算复杂度,同时保持甚至提升模型的性能。
🎯 应用场景
该研究成果可广泛应用于机器人操作领域,例如工业自动化、家庭服务机器人、医疗机器人等。通过提高VLA模型的推理效率,可以使机器人能够更快、更准确地完成复杂的操作任务,从而提高生产效率和服务质量。此外,该方法还可以应用于其他需要处理长序列多模态数据的场景,例如自动驾驶、视频理解等。
📄 摘要(原文)
Robotic manipulation with Vision-Language-Action models requires efficient inference over long-horizon multi-modal context, where attention to dense visual tokens dominates computational cost. Existing methods optimize inference speed by reducing visual redundancy within VLA models, but they overlook the varying redundancy across robotic manipulation stages. We observe that the visual token redundancy is higher in coarse manipulation phase than in fine-grained operations, and is strongly correlated with the action dynamic. Motivated by this observation, we propose \textbf{A}ction-aware \textbf{D}ynamic \textbf{P}runing (\textbf{ADP}), a multi-modal pruning framework that integrates text-driven token selection with action-aware trajectory gating. Our method introduces a gating mechanism that conditions the pruning signal on recent action trajectories, using past motion windows to adaptively adjust token retention ratios in accordance with dynamics, thereby balancing computational efficiency and perceptual precision across different manipulation stages. Extensive experiments on the LIBERO suites and diverse real-world scenarios demonstrate that our method significantly reduces FLOPs and action inference latency (\textit{e.g.} $1.35 \times$ speed up on OpenVLA-OFT) while maintaining competitive success rates (\textit{e.g.} 25.8\% improvements with OpenVLA) compared to baselines, thereby providing a simple plug-in path to efficient robot policies that advances the efficiency and performance frontier of robotic manipulation. Our project website is: \href{https://vla-adp.github.io/}{ADP.com}.