SAGE: Scene Graph-Aware Guidance and Execution for Long-Horizon Manipulation Tasks
作者: Jialiang Li, Wenzheng Wu, Gaojing Zhang, Yifan Han, Wenzhao Lian
分类: cs.RO, cs.AI
发布日期: 2025-09-26
💡 一句话要点
SAGE:基于场景图的长程操作任务引导与执行框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 长程操作 场景图 视觉语言模型 任务规划 图像编辑 机器人控制 语义推理
📋 核心要点
- 现有长程操作任务方法在泛化性和语义推理方面存在不足,图像条件控制难以适应新任务。
- SAGE利用场景图桥接任务级语义推理和像素级视觉运动控制,实现可控的子目标图像合成。
- 实验证明,SAGE在多个长程任务上取得了优于现有技术的性能表现。
📝 摘要(中文)
解决长程操作任务仍然是一个根本性的挑战。这类任务涉及扩展的动作序列和复杂的对象交互,在高层符号规划和低层连续控制之间存在关键差距。为了弥合这一差距,需要两种基本能力:鲁棒的长程任务规划和有效的以目标为条件的操控。现有的任务规划方法,包括传统方法和基于LLM的方法,通常表现出有限的泛化能力或稀疏的语义推理。同时,图像条件控制方法难以适应未见过的任务。为了解决这些问题,我们提出了SAGE,一种用于长程操作任务中场景图感知引导和执行的新框架。SAGE利用语义场景图作为场景状态的结构化表示。结构化场景图能够桥接任务级语义推理和像素级视觉运动控制。这也促进了精确、新颖的子目标图像的可控合成。SAGE由两个关键组件组成:(1)一个基于场景图的任务规划器,它使用VLM和LLM来解析环境并推理物理相关的场景状态转换序列,以及(2)一个解耦的结构化图像编辑管道,它通过图像修复和组合将每个目标子目标图可控地转换为相应的图像。大量的实验表明,SAGE在不同的长程任务上实现了最先进的性能。
🔬 方法详解
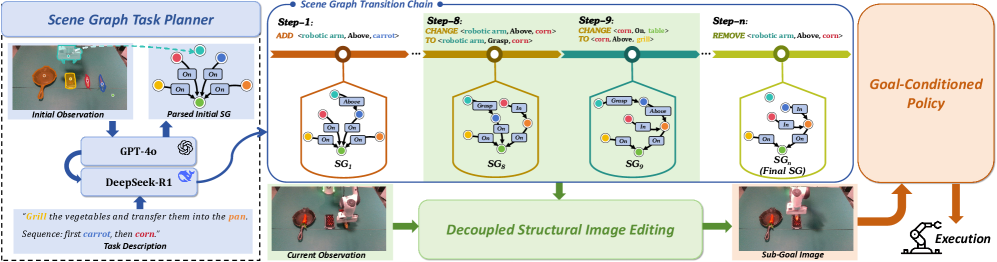
问题定义:论文旨在解决长程操作任务中,高层符号规划与低层连续控制之间的鸿沟。现有方法,如传统规划方法和基于LLM的规划方法,泛化能力有限,语义推理能力不足。同时,图像条件控制方法难以适应未见过的任务,导致长程任务难以完成。
核心思路:论文的核心思路是利用语义场景图作为场景状态的结构化表示,从而桥接任务级语义推理和像素级视觉运动控制。通过场景图,可以更好地理解环境,并进行物理相关的推理,从而实现更鲁棒的任务规划和更有效的目标条件控制。此外,通过可控的图像编辑,可以合成精确的子目标图像,指导低层控制器的执行。
技术框架:SAGE框架包含两个主要模块:(1)基于场景图的任务规划器:该模块利用VLM和LLM解析环境,并推理物理相关的场景状态转换序列,生成任务规划。(2)解耦的结构化图像编辑管道:该模块将每个目标子目标图可控地转换为相应的图像,通过图像修复和组合等技术,生成视觉上逼真的子目标图像。这两个模块协同工作,实现长程操作任务的规划和执行。
关键创新:SAGE的关键创新在于使用语义场景图作为中间表示,连接了高层语义推理和低层视觉运动控制。这种结构化的表示方式使得任务规划器能够更好地理解环境,并进行物理相关的推理。同时,解耦的图像编辑管道能够生成高质量的子目标图像,为低层控制器提供更有效的指导。
关键设计:在任务规划器中,VLM和LLM被用于解析环境和推理状态转换。具体的VLM和LLM选择以及prompt设计未知。在图像编辑管道中,使用了图像修复和组合等技术来生成子目标图像。具体的图像修复和组合算法以及损失函数等技术细节未知。
🖼️ 关键图片


📊 实验亮点
SAGE在多个长程操作任务上取得了state-of-the-art的性能。具体性能数据和对比基线未知,但论文强调SAGE在不同任务上均表现出优越性,证明了其泛化能力和有效性。SAGE通过场景图表示和可控图像编辑,显著提升了长程操作任务的成功率。
🎯 应用场景
SAGE框架具有广泛的应用前景,例如在家庭服务机器人、工业自动化、自动驾驶等领域。它可以用于解决复杂的长程操作任务,例如物品整理、装配、导航等。通过结合视觉信息和语义推理,SAGE能够使机器人更好地理解环境,并执行复杂的任务,从而提高机器人的智能化水平和工作效率。
📄 摘要(原文)
Successfully solving long-horizon manipulation tasks remains a fundamental challenge. These tasks involve extended action sequences and complex object interactions, presenting a critical gap between high-level symbolic planning and low-level continuous control. To bridge this gap, two essential capabilities are required: robust long-horizon task planning and effective goal-conditioned manipulation. Existing task planning methods, including traditional and LLM-based approaches, often exhibit limited generalization or sparse semantic reasoning. Meanwhile, image-conditioned control methods struggle to adapt to unseen tasks. To tackle these problems, we propose SAGE, a novel framework for Scene Graph-Aware Guidance and Execution in Long-Horizon Manipulation Tasks. SAGE utilizes semantic scene graphs as a structural representation for scene states. A structural scene graph enables bridging task-level semantic reasoning and pixel-level visuo-motor control. This also facilitates the controllable synthesis of accurate, novel sub-goal images. SAGE consists of two key components: (1) a scene graph-based task planner that uses VLMs and LLMs to parse the environment and reason about physically-grounded scene state transition sequences, and (2) a decoupled structural image editing pipeline that controllably converts each target sub-goal graph into a corresponding image through image inpainting and composition. Extensive experiments have demonstrated that SAGE achieves state-of-the-art performance on distinct long-horizon tasks.