VLBiMan: Vision-Language Anchored One-Shot Demonstration Enables Generalizable Bimanual Robotic Manipulation
作者: Huayi Zhou, Kui Jia
分类: cs.RO
发布日期: 2025-09-26 (更新: 2026-02-03)
备注: accepted by ICLR 2026. The project link is https://hnuzhy.github.io/projects/VLBiMan/
💡 一句话要点
VLBiMan:基于视觉-语言锚定的单样本示教实现通用双臂机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 双臂机器人 视觉-语言 grounding 单样本学习 任务分解 机器人操作
📋 核心要点
- 现有双臂操作方法在泛化性和效率之间存在trade-off,模仿学习需要大量数据,模块化方法缺乏灵活性。
- VLBiMan通过视觉-语言锚定,从单样本示教中提取可复用的技能,并动态适应场景变化,实现高效泛化。
- 实验表明,VLBiMan在减少演示需求、组合泛化、鲁棒性和跨形态迁移方面均表现出色。
📝 摘要(中文)
实现通用的双臂操作需要系统能够从最少的人工输入中高效学习,同时适应真实世界的不确定性和不同的机器人形态。现有方法面临两难:模仿策略学习需要大量的演示来覆盖任务变化,而模块化方法通常缺乏在动态场景中的灵活性。我们引入了VLBiMan,该框架通过任务感知的分解从单个人工示例中导出可重用的技能,保留不变的基元作为锚点,同时通过视觉-语言 grounding 动态调整可调整的组件。这种自适应机制解决了由背景变化、物体重新定位或视觉混乱引起的场景歧义,而无需策略重新训练,利用了语义解析和几何可行性约束。此外,该系统继承了类人的混合控制能力,能够混合同步和异步地使用双臂。大量的实验验证了VLBiMan在工具使用和多物体任务中的有效性,证明了:(1)与模仿基线相比,演示需求大幅减少;(2)通过原子技能拼接实现长时程任务的组合泛化;(3)对新的但语义相似的物体和外部干扰的鲁棒性;(4)强大的跨形态迁移,表明从人类演示中学习的技能可以在不同的机器人平台上实例化,而无需重新训练。通过将人类先验知识与视觉-语言锚定的自适应相结合,我们的工作朝着在非结构化环境中实现实用且通用的双臂操作迈出了一步。
🔬 方法详解
问题定义:现有双臂机器人操作方法难以在泛化性和学习效率之间取得平衡。模仿学习需要大量的示教数据来覆盖任务的各种变化,成本高昂。而模块化的方法虽然可以重用一些技能,但在面对动态变化的场景时,缺乏足够的灵活性和适应性,难以处理视觉歧义和干扰。
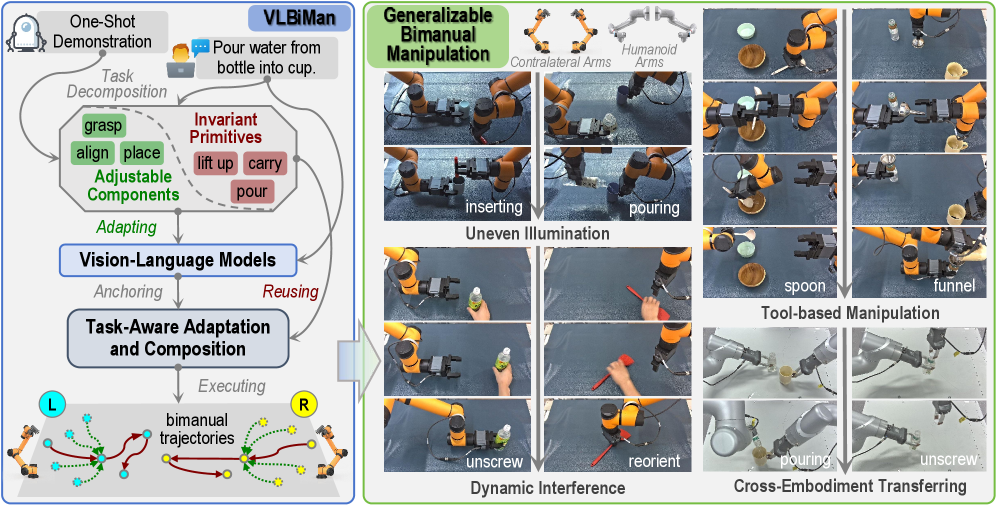
核心思路:VLBiMan的核心思路是从单个人工示教中提取任务相关的可重用技能,并利用视觉-语言 grounding 来动态调整这些技能,从而实现对新场景的泛化。该方法将任务分解为不变的基元(作为锚点)和可调整的组件,通过视觉-语言信息来理解场景,并调整可调整的组件以适应新的环境。
技术框架:VLBiMan框架包含以下主要模块:1) 任务分解模块:将人类示教分解为一系列原子技能,并识别出不变的基元和可调整的组件。2) 视觉-语言 grounding 模块:利用视觉信息和语言指令来理解场景,并确定如何调整可调整的组件。3) 运动规划与控制模块:根据调整后的技能,生成机器人的运动轨迹,并控制机器人执行任务。该框架利用语义解析和几何可行性约束来保证操作的合理性。
关键创新:VLBiMan的关键创新在于将视觉-语言 grounding 引入到双臂机器人操作中,并将其与任务分解相结合。这使得系统能够从单样本示教中学习,并动态适应新的场景,而无需重新训练。与传统的模仿学习方法相比,VLBiMan大大减少了对示教数据的需求。与模块化方法相比,VLBiMan具有更强的灵活性和适应性。
关键设计:VLBiMan的关键设计包括:1) 使用视觉-语言模型来解析场景,并提取语义信息。2) 设计了一种基于几何可行性约束的运动规划算法,以保证操作的安全性。3) 采用混合控制策略,允许双臂同步和异步地执行任务。具体的网络结构和损失函数细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VLBiMan仅需单样本示教即可完成复杂的双臂操作任务,与模仿学习基线相比,大大减少了对示教数据的需求。VLBiMan还展现出强大的组合泛化能力,能够通过拼接原子技能来完成长时程任务。此外,VLBiMan对新的但语义相似的物体和外部干扰具有很强的鲁棒性,并且能够实现跨形态迁移,即在不同机器人平台上复用学习到的技能。
🎯 应用场景
VLBiMan在自动化装配、家庭服务机器人、医疗辅助机器人等领域具有广泛的应用前景。它可以帮助机器人更高效地学习新的操作技能,并适应复杂多变的真实环境,从而提高机器人的智能化水平和服务能力。该研究为实现通用双臂机器人操作奠定了基础。
📄 摘要(原文)
Achieving generalizable bimanual manipulation requires systems that can learn efficiently from minimal human input while adapting to real-world uncertainties and diverse embodiments. Existing approaches face a dilemma: imitation policy learning demands extensive demonstrations to cover task variations, while modular methods often lack flexibility in dynamic scenes. We introduce VLBiMan, a framework that derives reusable skills from a single human example through task-aware decomposition, preserving invariant primitives as anchors while dynamically adapting adjustable components via vision-language grounding. This adaptation mechanism resolves scene ambiguities caused by background changes, object repositioning, or visual clutter without policy retraining, leveraging semantic parsing and geometric feasibility constraints. Moreover, the system inherits human-like hybrid control capabilities, enabling mixed synchronous and asynchronous use of both arms. Extensive experiments validate VLBiMan across tool-use and multi-object tasks, demonstrating: (1) a drastic reduction in demonstration requirements compared to imitation baselines, (2) compositional generalization through atomic skill splicing for long-horizon tasks, (3) robustness to novel but semantically similar objects and external disturbances, and (4) strong cross-embodiment transfer, showing that skills learned from human demonstrations can be instantiated on different robotic platforms without retraining. By bridging human priors with vision-language anchored adaptation, our work takes a step toward practical and versatile dual-arm manipulation in unstructured settings.