Towards Versatile Humanoid Table Tennis: Unified Reinforcement Learning with Prediction Augmentation
作者: Muqun Hu, Wenxi Chen, Wenjing Li, Falak Mandali, Zijian He, Renhong Zhang, Praveen Krisna, Katherine Christian, Leo Benaharon, Dizhi Ma, Karthik Ramani, Yan Gu
分类: cs.RO
发布日期: 2025-09-25 (更新: 2025-10-21)
💡 一句话要点
提出基于预测增强的统一强化学习框架,实现通用人形机器人乒乓球控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 乒乓球 强化学习 预测增强 运动控制
📋 核心要点
- 现有方法难以让人形机器人同时具备快速感知、主动全身运动和敏捷步法,尤其是在严格的时间限制下。
- 论文提出一种基于预测增强的统一强化学习框架,直接将球的位置信息映射到全身关节指令,实现击球和移动的协同控制。
- 实验表明,该方法在模拟和真实机器人上均表现出色,在模拟环境中击球率和成功率分别达到96%和92%,并在真实机器人上实现了零样本部署。
📝 摘要(中文)
本文提出了一种强化学习框架,旨在实现通用人形机器人乒乓球控制。该框架直接将球的位置观测映射到全身关节指令,从而控制手臂击球和腿部移动。通过预测信号和密集的、物理引导的奖励来增强学习效果。一个轻量级的学习预测器,以最近的球的位置为输入,估计未来的球的状态,并增强策略的观测,从而实现主动决策。在训练过程中,一个基于物理的预测器提供精确的未来状态,以构建密集的、信息丰富的奖励,从而促进有效的探索。在模拟环境中,该策略在不同的发球范围内都取得了良好的性能(击球率≥96%,成功率≥92%)。消融研究证实,学习预测器和预测奖励设计对于端到端学习至关重要。该策略在具有23个旋转关节的Booster T1人形机器人上进行了零样本部署,产生了协调的横向和前后步法,以及准确、快速的回球,这表明了实现通用、有竞争力的人形机器人乒乓球的实际途径。
🔬 方法详解
问题定义:现有的人形机器人乒乓球控制方法通常难以同时处理快速感知、主动全身运动和敏捷步法,尤其是在严格的时间限制下。这导致机器人难以有效地回击不同类型的来球,并且缺乏足够的泛化能力。现有的方法通常依赖于复杂的运动规划或分层控制结构,这些方法计算成本高昂,难以适应快速变化的环境。
核心思路:本文的核心思路是利用强化学习直接学习一个端到端的策略,该策略能够将球的位置观测映射到全身关节指令,从而实现手臂击球和腿部移动的协同控制。为了提高策略的性能和泛化能力,作者引入了预测增强机制,利用学习到的预测器来估计未来的球的状态,并将其作为策略的输入,从而实现主动决策。
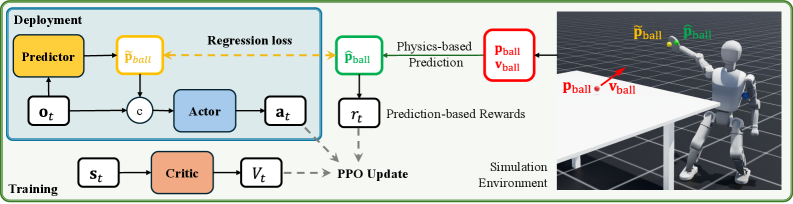
技术框架:该框架包含以下主要模块:1) 强化学习策略网络,用于将球的位置观测映射到全身关节指令;2) 学习预测器,用于估计未来的球的状态;3) 基于物理的预测器,用于在训练过程中提供精确的未来状态,以构建密集的、信息丰富的奖励;4) 奖励函数,用于引导策略的学习。整体流程是:首先,机器人观测当前球的位置;然后,学习预测器估计未来的球的状态;接着,强化学习策略网络根据当前球的位置和未来的球的状态,生成全身关节指令;最后,机器人执行这些指令,并根据奖励函数更新策略网络。
关键创新:最重要的技术创新点在于引入了预测增强机制,利用学习到的预测器来估计未来的球的状态,并将其作为策略的输入。这使得策略能够提前预测球的运动轨迹,从而做出更主动的决策。与现有方法相比,该方法不需要复杂的运动规划或分层控制结构,可以直接学习一个端到端的策略,从而降低了计算成本,提高了响应速度。
关键设计:学习预测器是一个轻量级的神经网络,以最近的球的位置为输入,输出未来的球的状态。奖励函数的设计采用了密集的、物理引导的奖励,包括击球奖励、成功奖励、运动奖励等。在训练过程中,作者使用了基于物理的预测器来提供精确的未来状态,以构建密集的、信息丰富的奖励,从而促进有效的探索。强化学习算法使用了PPO(Proximal Policy Optimization)算法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在模拟环境中取得了良好的性能,击球率达到96%以上,成功率达到92%以上。消融研究证实,学习预测器和预测奖励设计对于端到端学习至关重要。更重要的是,该策略在真实的Booster T1人形机器人上进行了零样本部署,产生了协调的横向和前后步法,以及准确、快速的回球,验证了该方法的有效性和泛化能力。
🎯 应用场景
该研究成果可应用于人形机器人的运动控制,例如体育竞技、人机协作等领域。通过学习复杂的运动技能,人形机器人可以更好地适应动态环境,完成各种任务。此外,该方法还可以推广到其他类型的机器人,例如四足机器人、无人机等,从而提高机器人的自主性和智能化水平。未来,该研究有望推动人形机器人在服务、医疗、娱乐等领域的广泛应用。
📄 摘要(原文)
Humanoid table tennis (TT) demands rapid perception, proactive whole-body motion, and agile footwork under strict timing -- capabilities that remain difficult for unified controllers. We propose a reinforcement learning framework that maps ball-position observations directly to whole-body joint commands for both arm striking and leg locomotion, strengthened by predictive signals and dense, physics-guided rewards. A lightweight learned predictor, fed with recent ball positions, estimates future ball states and augments the policy's observations for proactive decision-making. During training, a physics-based predictor supplies precise future states to construct dense, informative rewards that lead to effective exploration. The resulting policy attains strong performance across varied serve ranges (hit rate $\geq$ 96% and success rate $\geq$ 92%) in simulations. Ablation studies confirm that both the learned predictor and the predictive reward design are critical for end-to-end learning. Deployed zero-shot on a physical Booster T1 humanoid with 23 revolute joints, the policy produces coordinated lateral and forward-backward footwork with accurate, fast returns, suggesting a practical path toward versatile, competitive humanoid TT.