Real-Time Indoor Object SLAM with LLM-Enhanced Priors
作者: Yang Jiao, Yiding Qiu, Henrik I. Christensen
分类: cs.RO
发布日期: 2025-09-25
💡 一句话要点
提出LLM增强先验的实时室内物体SLAM,解决稀疏观测下的优化难题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 物体SLAM 大型语言模型 先验知识 图优化 室内场景 机器人导航
📋 核心要点
- 物体级SLAM面临稀疏观测导致的欠约束优化问题,传统方法依赖人工标注的常识知识,泛化性差。
- 利用大型语言模型(LLM)提供物体几何属性的常识知识,作为先验信息融入图优化SLAM框架。
- 在TUM RGB-D和3RScan数据集上,地图构建精度相比基线方法提升36.8%,并展示了实时性能。
📝 摘要(中文)
本文提出了一种基于大型语言模型(LLM)增强先验的物体级同步定位与地图构建(SLAM)方法,旨在解决由于稀疏观测导致的欠约束优化问题。传统的物体SLAM依赖人工标注的常识知识,泛化性较差且耗时。本文利用LLM提供物体几何属性(如尺寸和方向)的常识知识,并将其作为先验因子融入到基于图优化的SLAM框架中。这些先验信息在物体观测数据有限的初始阶段尤为重要。实验结果表明,该系统在TUM RGB-D和3RScan数据集上实现了鲁棒的数据关联和实时物体SLAM,相比最新的基线方法,地图构建精度提高了36.8%。补充视频展示了该系统在真实环境中的实时性能。
🔬 方法详解
问题定义:物体级SLAM旨在构建包含语义信息的场景地图,但由于物体观测的稀疏性,优化过程容易出现欠约束,导致定位和地图构建精度下降。现有方法通常依赖人工标注的常识知识来增加约束,但这种方式成本高昂且难以泛化到各种物体类别。
核心思路:利用大型语言模型(LLM)蕴含的丰富常识知识,特别是关于物体几何属性(如尺寸、方向)的先验信息,为物体SLAM提供额外的约束。LLM能够根据物体类别推断出合理的尺寸和方向范围,从而减少优化过程中的不确定性。
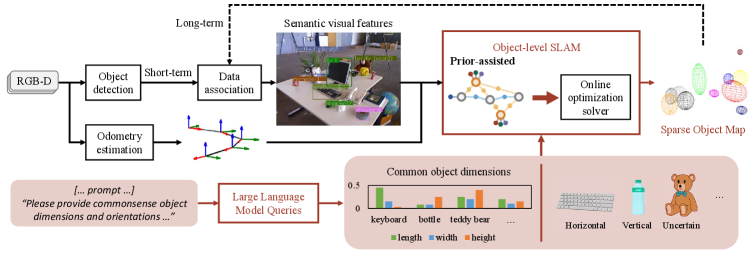
技术框架:该系统采用基于图优化的SLAM框架,将LLM提供的物体几何属性先验作为因子加入到优化图中。整个流程包括:1) RGB-D图像输入;2) 物体检测与识别;3) 利用LLM获取物体尺寸和方向的先验信息;4) 将先验信息作为因子加入到图优化中,与视觉观测信息融合;5) 优化位姿和地图。
关键创新:将大型语言模型(LLM)引入物体SLAM,利用其常识知识为物体几何属性提供先验信息,从而增强SLAM系统的鲁棒性和精度。与传统方法相比,该方法无需人工标注常识知识,具有更好的泛化能力。
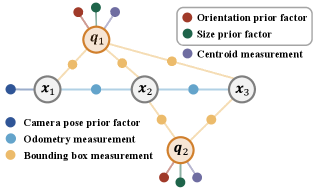
关键设计:LLM被用于预测物体尺寸和方向的概率分布,这些分布被转换为先验因子,并添加到SLAM的优化图中。具体来说,尺寸先验可以表示为物体边界框的宽度、高度和深度上的高斯分布。方向先验可以表示为物体朝向的角度上的高斯分布。这些先验信息与视觉观测信息(例如,物体在图像中的位置和大小)相结合,以估计物体的位姿和地图。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该系统在TUM RGB-D和3RScan数据集上取得了显著的性能提升。与最新的基线方法相比,地图构建精度提高了36.8%。此外,补充视频展示了该系统在真实环境中的实时性能,验证了其在实际应用中的可行性。
🎯 应用场景
该研究成果可应用于室内机器人导航、场景理解、增强现实等领域。例如,机器人可以在未知环境中利用物体SLAM构建语义地图,从而更好地理解环境并执行任务。在AR应用中,可以利用该技术将虚拟物体与真实场景中的物体进行精确对齐。
📄 摘要(原文)
Object-level Simultaneous Localization and Mapping (SLAM), which incorporates semantic information for high-level scene understanding, faces challenges of under-constrained optimization due to sparse observations. Prior work has introduced additional constraints using commonsense knowledge, but obtaining such priors has traditionally been labor-intensive and lacks generalizability across diverse object categories. We address this limitation by leveraging large language models (LLMs) to provide commonsense knowledge of object geometric attributes, specifically size and orientation, as prior factors in a graph-based SLAM framework. These priors are particularly beneficial during the initial phase when object observations are limited. We implement a complete pipeline integrating these priors, achieving robust data association on sparse object-level features and enabling real-time object SLAM. Our system, evaluated on the TUM RGB-D and 3RScan datasets, improves mapping accuracy by 36.8\% over the latest baseline. Additionally, we present real-world experiments in the supplementary video, demonstrating its real-time performance.