RetoVLA: Reusing Register Tokens for Spatial Reasoning in Vision-Language-Action Models
作者: Jiyeon Koo, Taewan Cho, Hyunjoon Kang, Eunseom Pyo, Tae Gyun Oh, Taeryang Kim, Andrew Jaeyong Choi
分类: cs.RO
发布日期: 2025-09-25
期刊: 2026 IEEE International Conference on Robotics and Automation (ICRA)
💡 一句话要点
RetoVLA:通过复用Register Tokens增强VLA模型在机器人操作中的空间推理能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人操作 空间推理 Transformer Register Tokens
📋 核心要点
- 现有VLA模型体积庞大,计算成本高昂,难以实际部署,而轻量化方法又往往牺牲空间推理能力。
- RetoVLA的核心思想是复用视觉Transformer中原本用于伪影移除后被丢弃的Register Tokens,将其注入Action Expert以增强空间推理。
- 实验表明,RetoVLA在定制的7自由度机器人手臂上,复杂操作任务的成功率提升了17.1%。
📝 摘要(中文)
现有的视觉-语言-动作(VLA)模型在机器人领域展现了出色的泛化能力,但其庞大的规模和计算成本限制了实际部署。轻量化方法通常会牺牲关键能力,特别是空间推理能力,导致效率和性能之间的权衡。为了解决这个问题,本文提出RetoVLA,一种新颖的架构,它复用Register Tokens,这些tokens最初用于视觉Transformer中的伪影移除,但随后被丢弃。我们假设这些tokens包含重要的空间信息,并通过将它们直接注入到Action Expert中来重新利用它们。RetoVLA在保持轻量级结构的同时,利用这种重新利用的空间上下文来增强推理能力。通过一系列全面的实验,证明了RetoVLA的有效性。在定制的7自由度机器人手臂上,该模型在复杂操作任务中的成功率实现了17.1%的绝对提升。结果证实,直接复用Register Tokens可以增强空间推理能力,表明以前被丢弃的伪影实际上是机器人智能的一个有价值的、未被探索的资源。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作(VLA)模型在机器人操作任务中,模型体积大、计算成本高,以及轻量化后空间推理能力下降的问题。现有方法在追求效率时,往往牺牲了对环境空间信息的理解,导致在复杂操作任务中表现不佳。
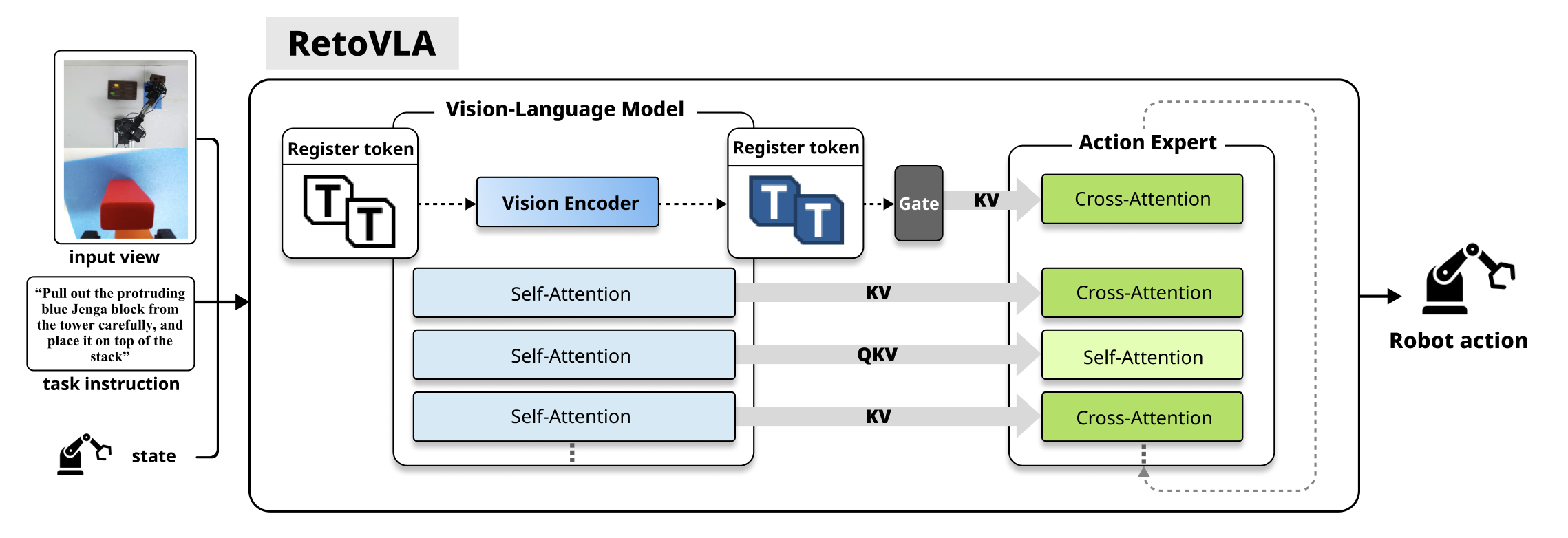
核心思路:论文的核心思路是复用视觉Transformer中原本用于伪影移除的Register Tokens。作者认为这些tokens包含了重要的空间信息,可以被重新利用以增强模型的空间推理能力。通过将这些tokens注入到Action Expert中,模型可以在不显著增加计算负担的情况下,更好地理解和利用空间信息。
技术框架:RetoVLA的整体架构基于现有的VLA模型,主要改进在于Register Token的利用。首先,图像通过视觉Transformer提取特征,其中包括Register Tokens。然后,这些Register Tokens被直接注入到Action Expert模块中,Action Expert负责根据视觉和语言输入生成动作指令。Action Expert的输出控制机器人的动作执行。
关键创新:RetoVLA的关键创新在于对Register Tokens的重新利用。以往的研究通常将这些tokens视为伪影并丢弃,而本文则发现了它们所蕴含的空间信息价值,并提出了一种简单有效的利用方法。这种方法避免了引入额外的复杂模块,保持了模型的轻量化。
关键设计:Register Tokens的注入方式是关键设计之一。具体实现细节论文中可能没有详细说明,但可以推测可能采用concat、attention等方式将Register Tokens的信息融入到Action Expert的特征表示中。损失函数方面,应该沿用了原VLA模型的损失函数,没有做特殊修改。
🖼️ 关键图片
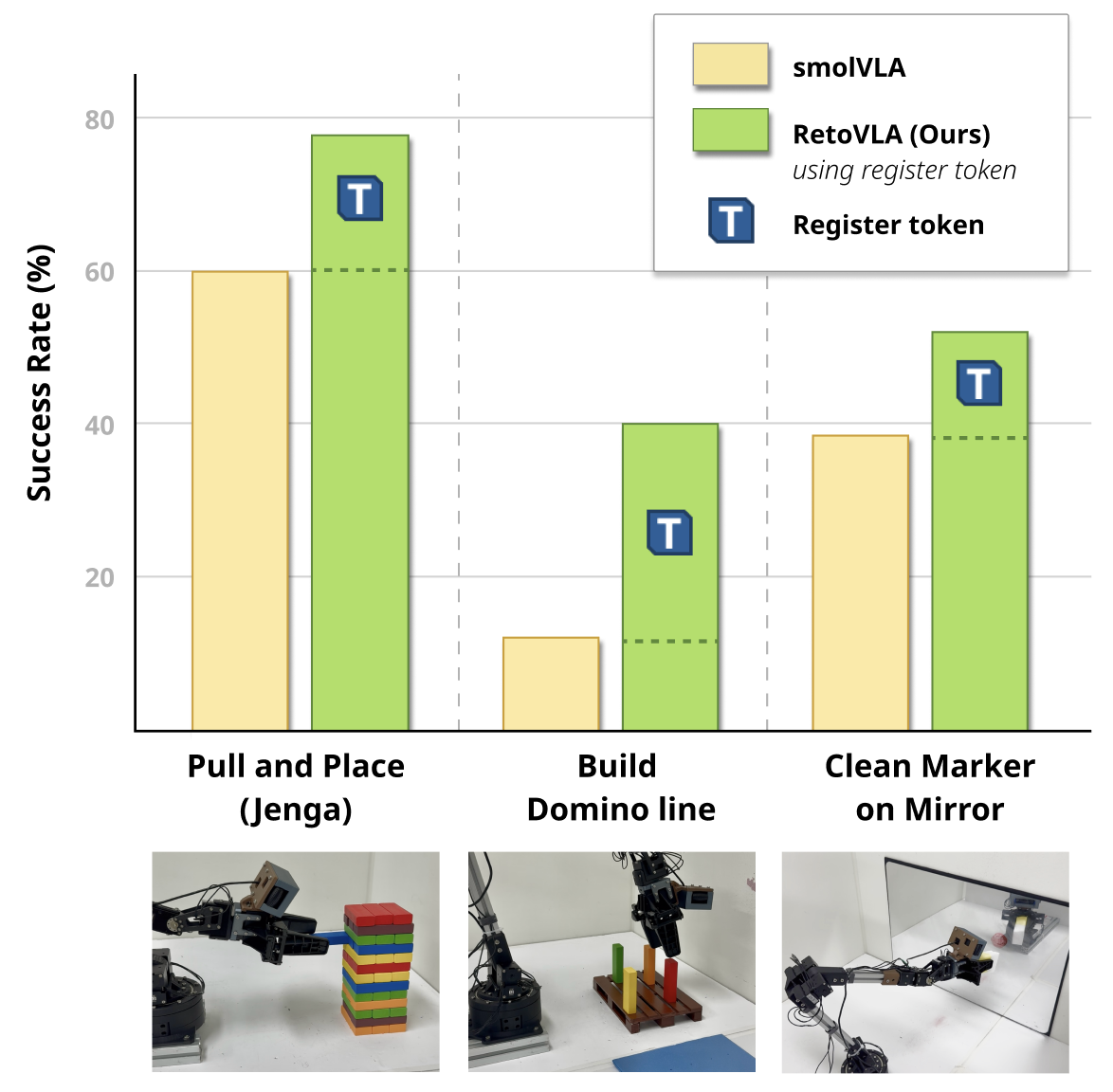

📊 实验亮点
RetoVLA在定制的7自由度机器人手臂上进行了实验,结果表明,在复杂操作任务中,RetoVLA的成功率比基线模型提高了17.1%。这一显著的提升证明了Register Tokens在空间推理中的重要作用,以及RetoVLA架构的有效性。该结果表明,即使是原本被认为是伪影的信息,也可能蕴含着重要的价值。
🎯 应用场景
RetoVLA具有广泛的应用前景,尤其是在资源受限的机器人应用场景中。例如,它可以应用于低功耗机器人、移动机器人和嵌入式机器人系统中,使其能够在复杂环境中执行精确的操作任务。此外,该研究思路也可以推广到其他视觉-语言任务中,通过复用中间特征来提升模型性能。
📄 摘要(原文)
Recent Vision-Language-Action (VLA) models demonstrate remarkable generalization in robotics but are restricted by their substantial size and computational cost, limiting real-world deployment. However, conventional lightweighting methods often sacrifice critical capabilities, particularly spatial reasoning. This creates a trade-off between efficiency and performance. To address this challenge, our work reuses Register Tokens, which were introduced for artifact removal in Vision Transformers but subsequently discarded. We suppose that these tokens contain essential spatial information and propose RetoVLA, a novel architecture that reuses them directly by injecting them into the Action Expert. RetoVLA maintains a lightweight structure while leveraging this repurposed spatial context to enhance reasoning. We demonstrate RetoVLA's effectiveness through a series of comprehensive experiments. On our custom-built 7-DOF robot arm, the model achieves a 17.1%p absolute improvement in success rates for complex manipulation tasks. Our results confirm that reusing Register Tokens directly enhances spatial reasoning, demonstrating that what was previously discarded as an artifact is in fact a valuable, unexplored resource for robotic intelligence. A video demonstration is available at: https://youtu.be/2CseBR-snZg