Cross-Modal Instructions for Robot Motion Generation
作者: William Barron, Xiaoxiang Dong, Matthew Johnson-Roberson, Weiming Zhi
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-09-25
💡 一句话要点
提出CrossInstruct框架,利用跨模态指令生成机器人运动轨迹
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 机器人运动生成 跨模态学习 视觉-语言模型 强化学习 机器人控制
📋 核心要点
- 传统机器人行为学习依赖于人工示教,数据收集困难且难以扩展,限制了机器人泛化能力。
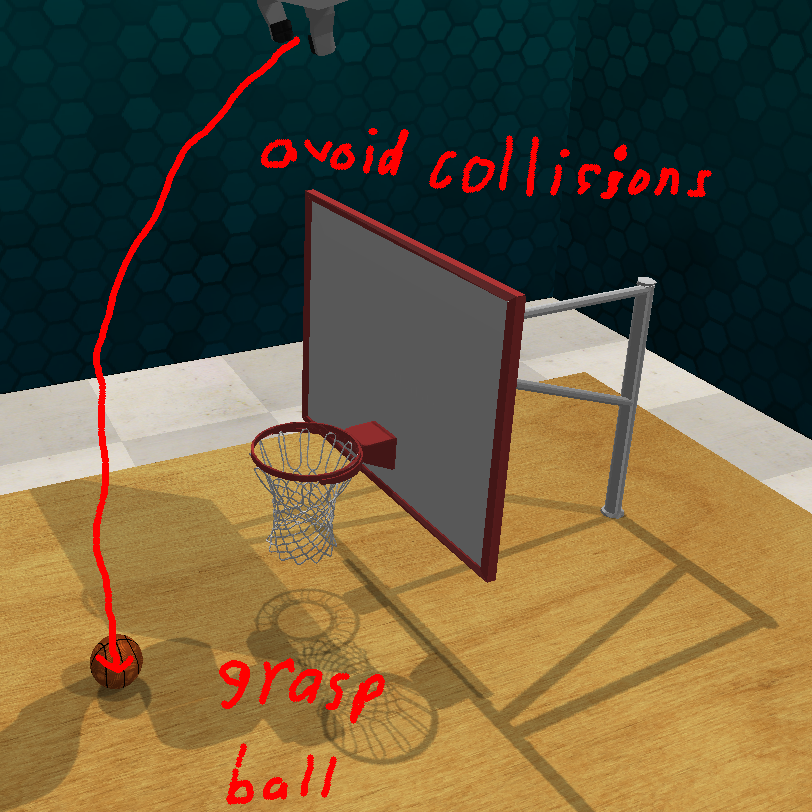
- CrossInstruct框架利用视觉-语言模型,通过文本指令和粗略标注引导机器人学习,无需精确的运动演示。
- 实验表明,CrossInstruct在模拟和真实环境中均有效,并能为强化学习提供良好的策略初始化。
📝 摘要(中文)
本文提出了一种新的机器人行为学习范式:从跨模态指令中学习。该方法利用粗略的标注(包含自由文本标签)作为运动演示,替代传统的遥操作或物理引导。论文提出了CrossInstruct框架,将跨模态指令作为上下文输入到基础视觉-语言模型(VLM)中。VLM迭代查询一个较小的、微调后的模型,并综合多个2D视图上的期望运动。这些运动随后被融合为机器人工作空间中3D运动轨迹的连贯分布。通过结合大型VLM的推理能力和精细的指向模型,CrossInstruct生成可执行的机器人行为,这些行为可以泛化到有限指令示例环境之外。此外,论文还引入了一个下游强化学习流程,利用CrossInstruct的输出高效地学习完成精细任务的策略。在基准模拟任务和真实硬件上的评估表明,CrossInstruct无需额外微调即可有效工作,并为后续通过强化学习改进的策略提供了强大的初始化。
🔬 方法详解
问题定义:现有机器人行为学习方法主要依赖于遥操作或物理示教,需要大量的人工干预和精确的运动轨迹数据。这种方式数据收集成本高昂,难以扩展到新的任务和环境,并且示教数据往往难以泛化。因此,如何利用更简洁、更易获取的指令来引导机器人学习,是一个重要的挑战。
核心思路:CrossInstruct的核心思路是利用跨模态指令(例如文本描述和粗略的视觉标注)作为机器人行为的指导信号,替代传统的精确运动轨迹。通过结合大型视觉-语言模型(VLM)的强大推理能力和精细的指向模型,CrossInstruct能够理解指令的意图,并生成相应的机器人运动轨迹。这种方法降低了数据收集的难度,并提高了模型的泛化能力。
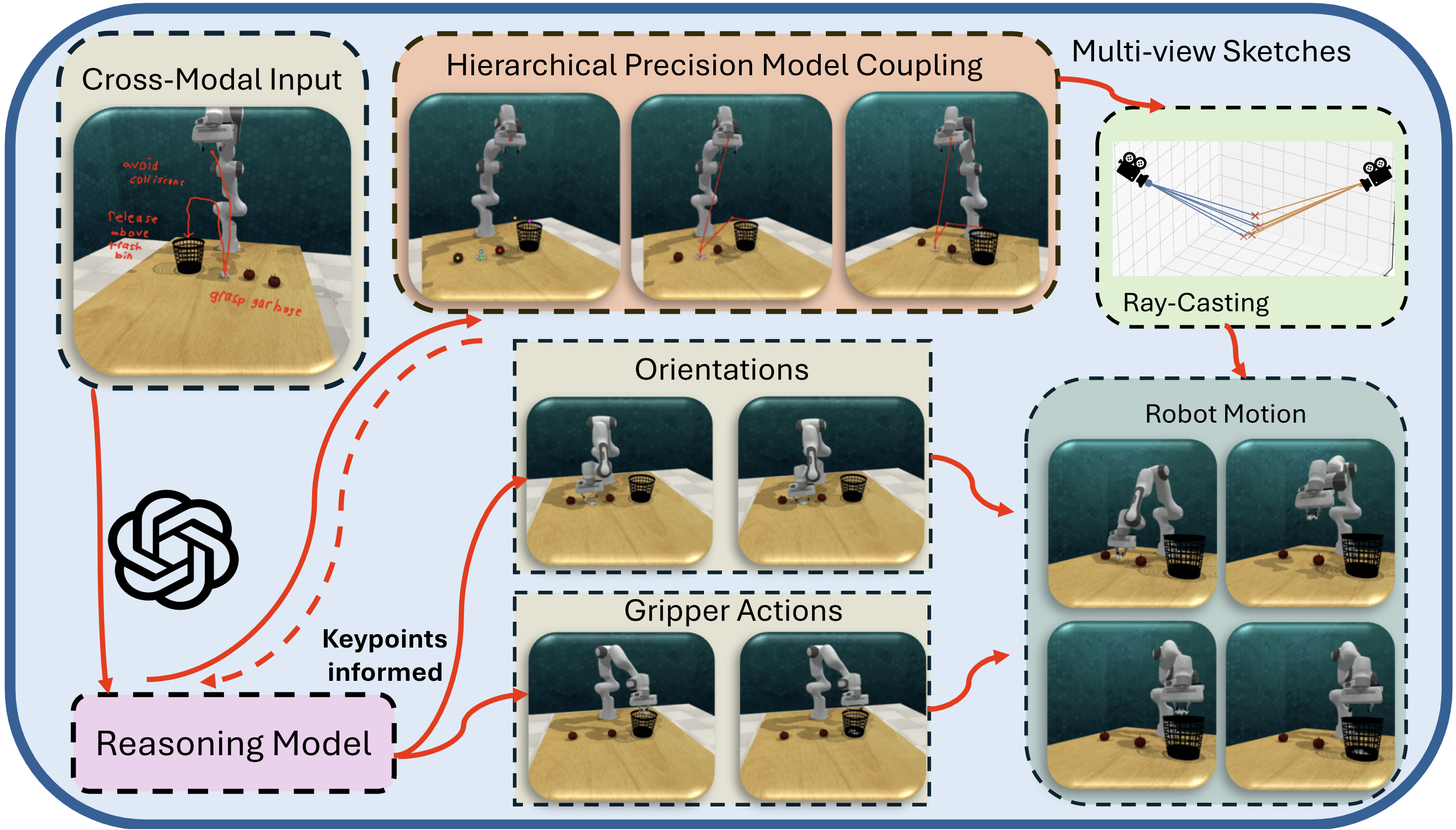
技术框架:CrossInstruct框架主要包含以下几个模块:1) 跨模态指令编码器:将文本指令和视觉标注编码为特征向量。2) 视觉-语言模型(VLM):利用预训练的VLM,将指令特征向量作为上下文输入,推理出期望的机器人运动。3) 运动合成模块:VLM迭代查询一个微调后的指向模型,在多个2D视图上合成期望的运动轨迹。4) 3D运动融合模块:将多个2D视图上的运动轨迹融合为机器人工作空间中的3D运动轨迹分布。5) 强化学习模块(可选):利用CrossInstruct生成的运动轨迹作为初始化,通过强化学习进一步优化策略。
关键创新:CrossInstruct的关键创新在于:1) 跨模态指令学习范式:使用文本和视觉标注作为指令,降低了数据收集的难度。2) VLM的集成:利用大型VLM的推理能力,提高了模型对指令的理解和泛化能力。3) 2D-3D运动融合:将多个2D视图上的运动轨迹融合为3D运动轨迹,提高了运动的准确性和鲁棒性。
关键设计:在VLM部分,论文使用了预训练的视觉-语言模型,并针对机器人运动生成任务进行了微调。在运动合成模块,论文设计了一个指向模型,用于预测每个时间步的期望运动方向。在3D运动融合模块,论文使用了一种基于高斯混合模型的融合方法,将多个2D视图上的运动轨迹融合为3D运动轨迹分布。损失函数包括指令理解损失、运动预测损失和轨迹平滑损失。
🖼️ 关键图片

📊 实验亮点
CrossInstruct在模拟和真实机器人实验中均取得了显著成果。在模拟环境中,CrossInstruct能够成功生成各种复杂的机器人运动轨迹,并且能够泛化到新的环境和任务。在真实机器人实验中,CrossInstruct无需额外微调即可完成物体抓取任务,并且能够为强化学习提供良好的策略初始化,加速策略学习过程。
🎯 应用场景
CrossInstruct框架可应用于各种机器人任务,例如物体抓取、装配、导航等。它降低了机器人编程的门槛,使得非专业人员也能通过简单的文本指令和视觉标注来指导机器人完成复杂任务。该技术在智能制造、家庭服务、医疗康复等领域具有广阔的应用前景,有望加速机器人的普及和应用。
📄 摘要(原文)
Teaching robots novel behaviors typically requires motion demonstrations via teleoperation or kinaesthetic teaching, that is, physically guiding the robot. While recent work has explored using human sketches to specify desired behaviors, data collection remains cumbersome, and demonstration datasets are difficult to scale. In this paper, we introduce an alternative paradigm, Learning from Cross-Modal Instructions, where robots are shaped by demonstrations in the form of rough annotations, which can contain free-form text labels, and are used in lieu of physical motion. We introduce the CrossInstruct framework, which integrates cross-modal instructions as examples into the context input to a foundational vision-language model (VLM). The VLM then iteratively queries a smaller, fine-tuned model, and synthesizes the desired motion over multiple 2D views. These are then subsequently fused into a coherent distribution over 3D motion trajectories in the robot's workspace. By incorporating the reasoning of the large VLM with a fine-grained pointing model, CrossInstruct produces executable robot behaviors that generalize beyond the environment of in the limited set of instruction examples. We then introduce a downstream reinforcement learning pipeline that leverages CrossInstruct outputs to efficiently learn policies to complete fine-grained tasks. We rigorously evaluate CrossInstruct on benchmark simulation tasks and real hardware, demonstrating effectiveness without additional fine-tuning and providing a strong initialization for policies subsequently refined via reinforcement learning.