SemSight: Probabilistic Bird's-Eye-View Prediction of Multi-Level Scene Semantics for Navigation
作者: Jiaxuan He, Jiamei Ren, Chongshang Yan, Wenjie Song
分类: cs.RO
发布日期: 2025-09-25
💡 一句话要点
SemSight:用于导航的多层次场景语义概率鸟瞰图预测
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 鸟瞰图预测 语义地图 自主导航 场景理解 掩码约束学习
📋 核心要点
- 现有导航方法侧重于单个物体或几何地图,忽略了房间级语义结构,限制了环境理解能力。
- SemSight通过联合推断结构布局、场景上下文和目标分布,预测未探索区域的多层次语义信息。
- 实验表明,SemSight在语义预测和导航效率上均优于现有方法,尤其是在结构一致性方面。
📝 摘要(中文)
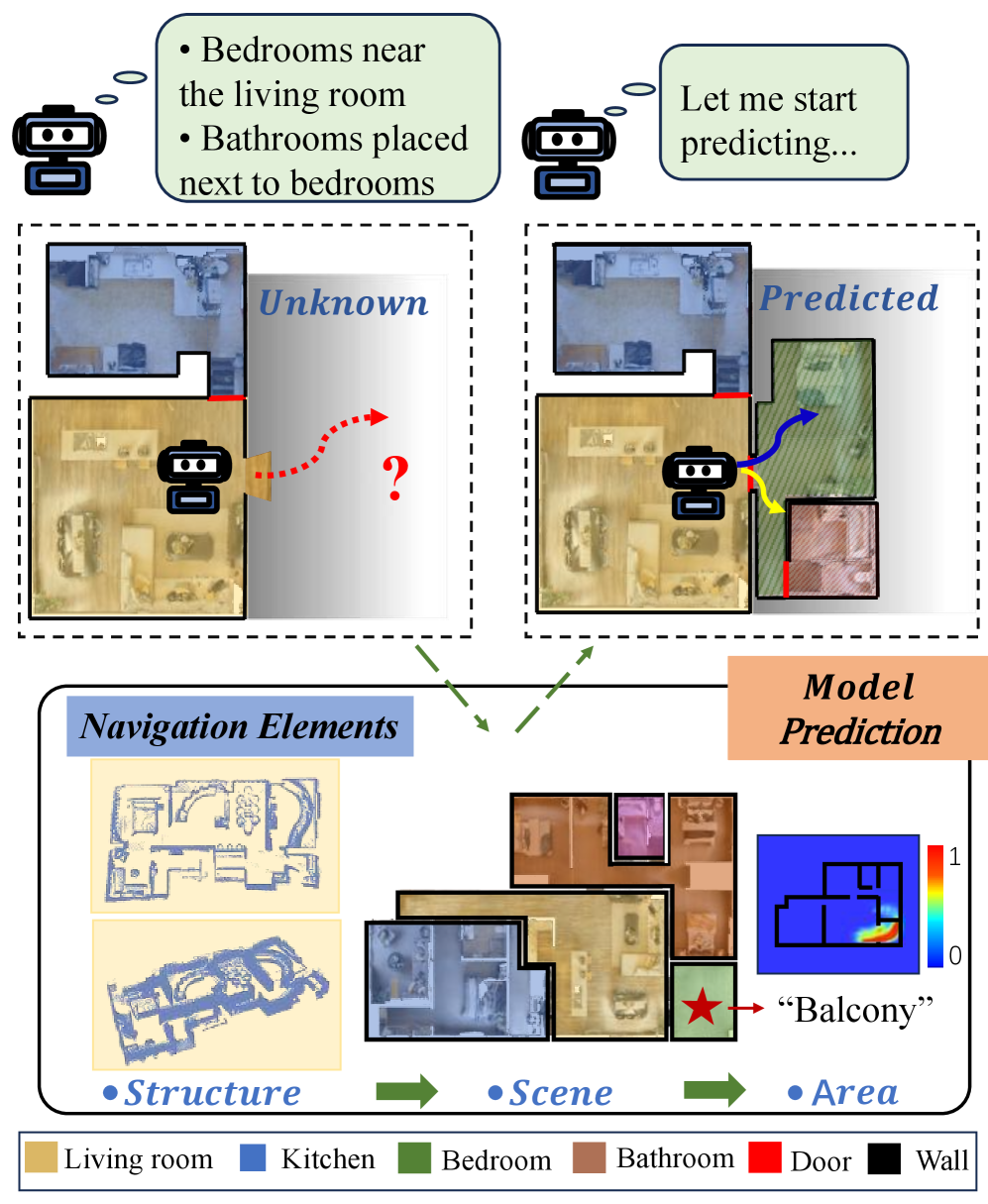
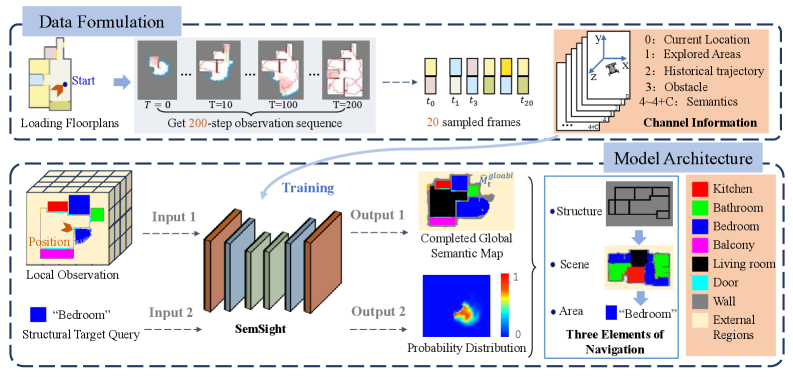
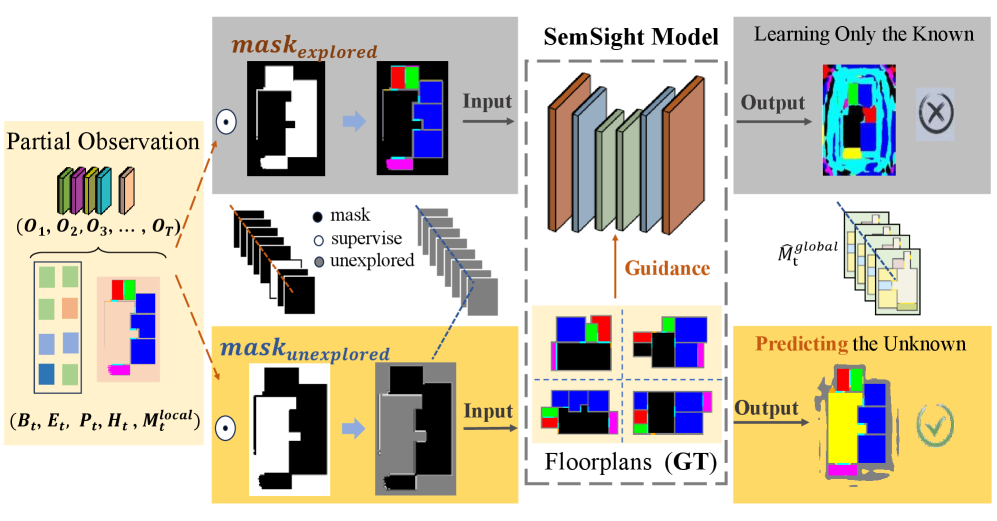
在目标驱动导航和自主探索中,对未知区域的合理预测对于高效导航和环境理解至关重要。现有方法主要关注单个对象或几何占据地图,缺乏对房间级语义结构建模的能力。我们提出了SemSight,一个用于多层次场景语义的概率鸟瞰图预测模型。该模型联合推断结构布局、全局场景上下文和目标区域分布,在完成未探索区域的语义地图的同时,估计目标类别的概率图。为了训练SemSight,我们在2000个室内布局图上模拟了前沿驱动的探索,构建了一个包含40000个连续的以自我为中心的观察结果与完整语义地图配对的多样化数据集。我们采用编码器-解码器网络作为核心架构,并引入了一种掩码约束监督策略。该策略应用未探索区域的二元掩码,使监督只关注未知区域,迫使模型从观察到的上下文中推断语义结构。实验结果表明,SemSight提高了未探索区域中关键功能类别的预测性能,并在结构一致性(SC)和区域识别准确率(PA)等指标上优于非掩码监督方法。它还提高了闭环模拟中的导航效率,减少了引导机器人朝向目标区域的搜索步骤。
🔬 方法详解
问题定义:现有基于视觉的导航方法,特别是目标驱动的导航,在未知环境中面临挑战。它们通常依赖于对单个物体或几何占据地图的预测,而忽略了更高级别的语义结构,例如房间布局和功能区域。这种局限性阻碍了机器人对环境的整体理解和高效探索。因此,需要一种能够预测未知区域多层次语义信息的模型,从而提升导航性能。
核心思路:SemSight的核心思路是利用概率鸟瞰图预测来推断未知区域的多层次语义信息。通过联合建模结构布局、全局场景上下文和目标区域分布,该模型能够完成未探索区域的语义地图,并估计目标类别的概率图。这种方法允许机器人不仅了解环境的几何结构,还能理解其语义含义,从而做出更明智的导航决策。
技术框架:SemSight采用编码器-解码器网络作为核心架构。编码器负责从以自我为中心的观察中提取特征,解码器则基于这些特征预测鸟瞰图中的多层次语义信息。整个框架通过模拟前沿驱动的探索过程生成的数据集进行训练。该数据集包含连续的以自我为中心的观察结果以及对应的完整语义地图。
关键创新:SemSight的关键创新在于引入了一种掩码约束监督策略。该策略使用未探索区域的二元掩码,使得监督信号只作用于未知区域。这种方法迫使模型从已观察到的上下文中推断语义结构,而不是简单地复制已知的区域。这种掩码约束监督策略显著提高了模型在未知区域的预测性能。
关键设计:SemSight的关键设计包括:1) 使用编码器-解码器网络进行特征提取和语义预测;2) 采用掩码约束监督策略,只监督未知区域的预测;3) 通过模拟前沿驱动的探索过程生成大规模训练数据集;4) 使用结构一致性(SC)和区域识别准确率(PA)等指标评估模型的性能。
🖼️ 关键图片
📊 实验亮点
SemSight在实验中表现出色,显著提高了未探索区域中关键功能类别的预测性能。与非掩码监督方法相比,SemSight在结构一致性(SC)和区域识别准确率(PA)等指标上取得了显著提升。此外,SemSight还提高了闭环模拟中的导航效率,减少了引导机器人朝向目标区域的搜索步骤。这些结果表明,SemSight是一种有效的多层次场景语义预测模型,具有很强的实用价值。
🎯 应用场景
SemSight具有广泛的应用前景,包括自主导航、机器人探索、智能家居和虚拟现实等领域。它可以帮助机器人在未知环境中更有效地导航和探索,提高机器人的环境理解能力,并为用户提供更智能、更个性化的服务。例如,在智能家居中,机器人可以利用SemSight来理解房间布局和物体摆放,从而更好地完成清洁、整理等任务。
📄 摘要(原文)
In target-driven navigation and autonomous exploration, reasonable prediction of unknown regions is crucial for efficient navigation and environment understanding. Existing methods mostly focus on single objects or geometric occupancy maps, lacking the ability to model room-level semantic structures. We propose SemSight, a probabilistic bird's-eye-view prediction model for multi-level scene semantics. The model jointly infers structural layouts, global scene context, and target area distributions, completing semantic maps of unexplored areas while estimating probability maps for target categories. To train SemSight, we simulate frontier-driven exploration on 2,000 indoor layout graphs, constructing a diverse dataset of 40,000 sequential egocentric observations paired with complete semantic maps. We adopt an encoder-decoder network as the core architecture and introduce a mask-constrained supervision strategy. This strategy applies a binary mask of unexplored areas so that supervision focuses only on unknown regions, forcing the model to infer semantic structures from the observed context. Experimental results show that SemSight improves prediction performance for key functional categories in unexplored regions and outperforms non-mask-supervised approaches on metrics such as Structural Consistency (SC) and Region Recognition Accuracy (PA). It also enhances navigation efficiency in closed-loop simulations, reducing the number of search steps when guiding robots toward target areas.