SLAM-Free Visual Navigation with Hierarchical Vision-Language Perception and Coarse-to-Fine Semantic Topological Planning
作者: Guoyang Zhao, Yudong Li, Weiqing Qi, Kai Zhang, Bonan Liu, Kai Chen, Haoang Li, Jun Ma
分类: cs.RO, cs.CV
发布日期: 2025-09-25
💡 一句话要点
提出一种基于视觉-语言分层感知和粗细粒度语义拓扑规划的无SLAM视觉导航框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉导航 无SLAM 视觉-语言感知 语义拓扑地图 粗细粒度规划
📋 核心要点
- 传统SLAM方法在腿式机器人导航中易受快速运动和传感器漂移影响,且缺乏足够的语义推理能力。
- 该论文提出一种无SLAM的导航框架,利用视觉-语言感知和语义拓扑地图进行粗细粒度规划。
- 实验结果表明,该方法在语义准确性、规划质量和导航成功率方面均优于现有方法。
📝 摘要(中文)
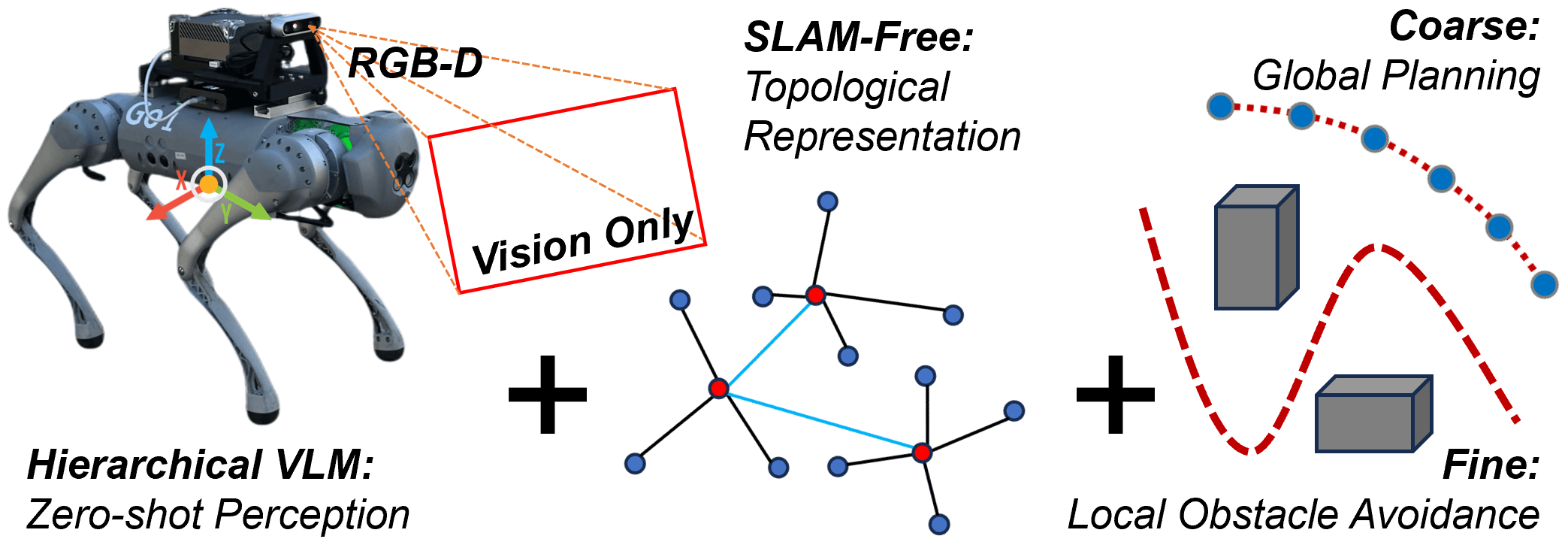
本文提出了一种纯视觉、无SLAM的导航框架,旨在解决传统SLAM在快速运动、标定需求和传感器漂移下的脆弱性,并提升任务驱动探索的语义推理能力。该框架利用分层视觉-语言感知模块融合场景级上下文和对象级线索,实现鲁棒的语义推理。语义概率拓扑地图支持粗细粒度的规划:基于LLM的全局推理用于子目标选择,基于视觉的局部规划用于避障。该框架与强化学习运动控制器集成,可部署在不同的腿式机器人平台上。仿真和真实环境的实验表明,该框架在语义准确性、规划质量和导航成功率方面均有持续改进,消融研究进一步证明了分层感知和精细局部规划的必要性。这项工作为无SLAM、视觉-语言驱动的导航引入了一种新范式,将机器人探索从以几何为中心的映射转变为以语义为中心的决策。
🔬 方法详解
问题定义:传统SLAM方法在腿式机器人导航中存在诸多问题,例如对快速运动敏感、需要精确标定、容易受到传感器漂移的影响。此外,传统方法主要关注几何信息的构建,缺乏对场景语义信息的理解,难以支持任务驱动的探索。
核心思路:该论文的核心思路是利用视觉-语言感知来替代传统的几何SLAM,构建一个语义化的环境表示,并在此基础上进行导航规划。通过融合场景级和对象级的语义信息,提高环境理解的鲁棒性。利用LLM进行全局推理,选择合适的子目标,并结合视觉信息进行局部避障,实现粗细粒度的导航规划。
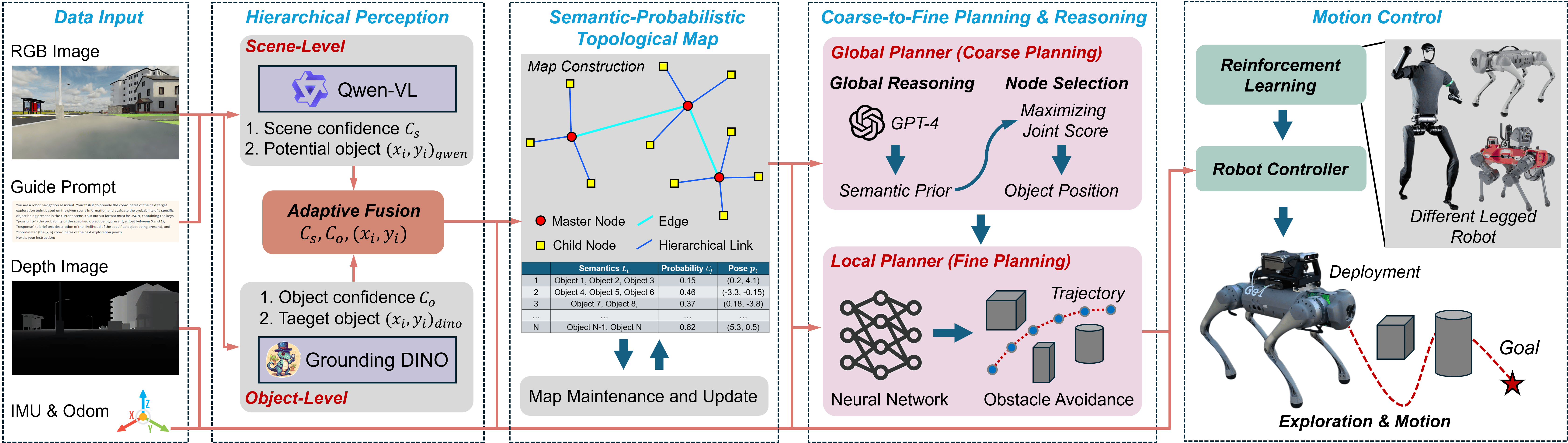
技术框架:该框架主要包含三个模块:1) 分层视觉-语言感知模块:用于提取场景的语义信息,包括场景级的上下文信息和对象级的线索信息。2) 语义概率拓扑地图:用于表示环境的拓扑结构,并存储每个节点的语义信息。3) 粗细粒度规划模块:利用LLM进行全局推理,选择合适的子目标,并结合视觉信息进行局部避障。
关键创新:该论文的关键创新在于提出了一种无SLAM的、基于视觉-语言的导航框架。该框架将机器人探索从以几何为中心的映射转变为以语义为中心的决策,从而提高了导航的鲁棒性和效率。此外,该框架还利用LLM进行全局推理,从而可以更好地理解任务目标,并选择合适的导航策略。
关键设计:分层视觉-语言感知模块的具体实现细节未知,但可以推测其可能采用了多模态融合的方法,将视觉信息和语言信息进行融合,从而提高语义理解的准确性。语义概率拓扑地图的具体构建方法也未知,但可以推测其可能采用了概率图模型来表示环境的拓扑结构,并利用贝叶斯方法来更新地图。粗细粒度规划模块中,LLM的具体选择和使用方式未知,但可以推测其可能采用了prompt engineering的方法来引导LLM生成合适的导航策略。
🖼️ 关键图片
📊 实验亮点
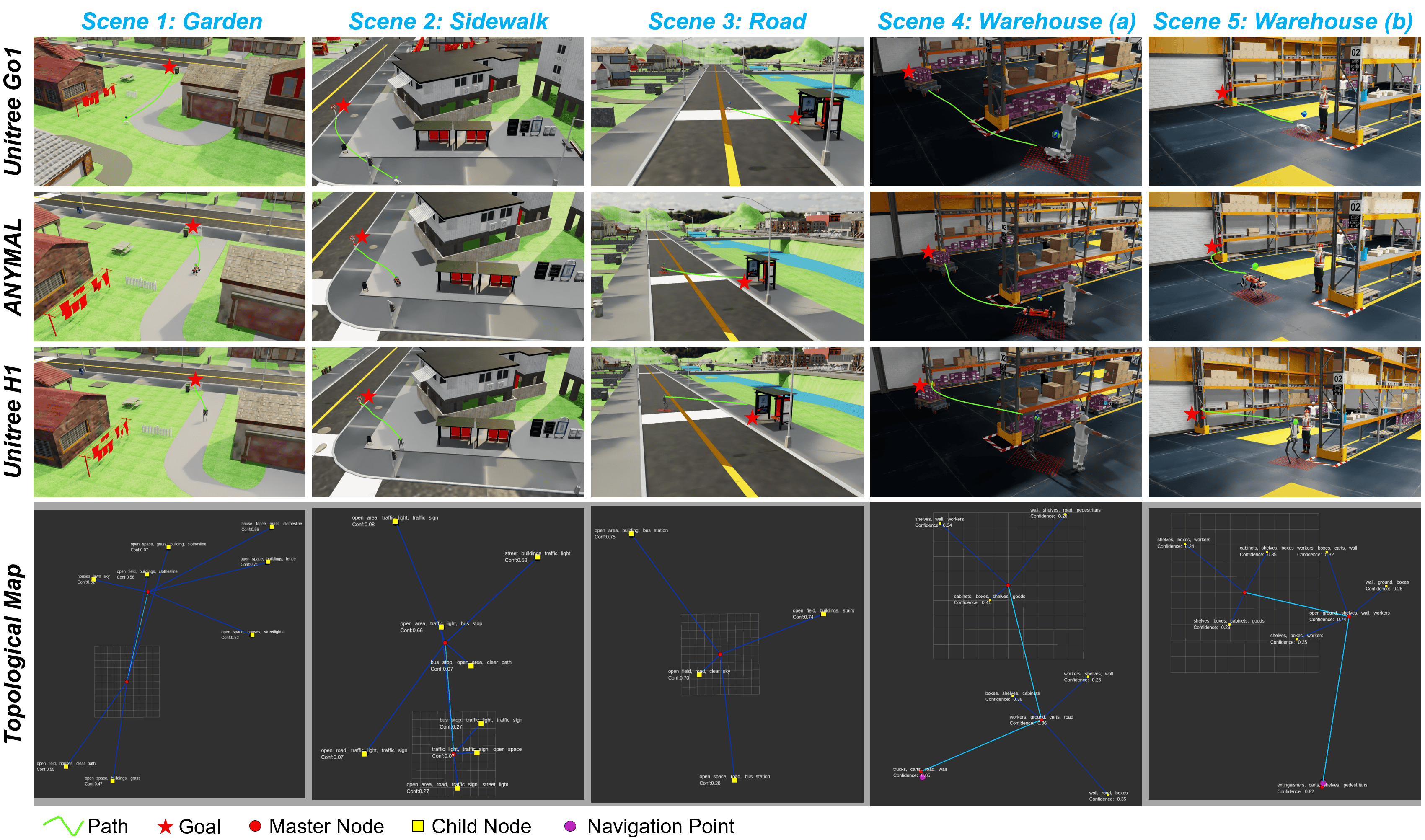
论文在仿真和真实环境中进行了实验,结果表明,该方法在语义准确性、规划质量和导航成功率方面均优于现有方法。消融实验证明了分层感知和精细局部规划的必要性。具体的性能数据未知,但摘要中明确指出有“consistent improvements”。
🎯 应用场景
该研究成果可应用于各种腿式机器人的自主导航任务,例如家庭服务机器人、巡检机器人、搜救机器人等。通过利用视觉-语言感知和语义拓扑地图,机器人可以更好地理解环境,并进行更智能的导航。该技术还可以应用于自动驾驶领域,提高车辆在复杂环境下的导航能力。
📄 摘要(原文)
Conventional SLAM pipelines for legged robot navigation are fragile under rapid motion, calibration demands, and sensor drift, while offering limited semantic reasoning for task-driven exploration. To deal with these issues, we propose a vision-only, SLAM-free navigation framework that replaces dense geometry with semantic reasoning and lightweight topological representations. A hierarchical vision-language perception module fuses scene-level context with object-level cues for robust semantic inference. And a semantic-probabilistic topological map supports coarse-to-fine planning: LLM-based global reasoning for subgoal selection and vision-based local planning for obstacle avoidance. Integrated with reinforcement-learning locomotion controllers, the framework is deployable across diverse legged robot platforms. Experiments in simulation and real-world settings demonstrate consistent improvements in semantic accuracy, planning quality, and navigation success, while ablation studies further showcase the necessity of both hierarchical perception and fine local planning. This work introduces a new paradigm for SLAM-free, vision-language-driven navigation, shifting robotic exploration from geometry-centric mapping to semantics-driven decision making.