RobotDancing: Residual-Action Reinforcement Learning Enables Robust Long-Horizon Humanoid Motion Tracking
作者: Zhenguo Sun, Yibo Peng, Yuan Meng, Xukun Li, Bo-Sheng Huang, Zhenshan Bing, Xinlong Wang, Alois Knoll
分类: cs.RO, cs.AI
发布日期: 2025-09-25
💡 一句话要点
提出基于残差动作强化学习的RobotDancing框架,实现鲁棒的人形机器人长时程运动跟踪。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 人形机器人 强化学习 运动跟踪 残差控制 零样本迁移
📋 核心要点
- 现有方法难以补偿模型与真实环境的差异,导致人形机器人长时程运动跟踪中误差累积。
- RobotDancing通过预测残差关节目标,显式纠正动力学差异,提升运动跟踪的鲁棒性。
- 该框架采用端到端强化学习,在模拟环境中训练,并能零样本迁移到真实机器人上,实现高质量运动跟踪。
📝 摘要(中文)
人形机器人上的长时程、高动态运动跟踪仍然脆弱,因为绝对关节指令无法补偿模型与实际环境的不匹配,导致误差累积。我们提出了RobotDancing,一个简单、可扩展的框架,它预测残差关节目标以显式地纠正动力学差异。该流程是端到端的——训练、sim-to-sim验证和零样本sim-to-real——并使用具有统一观察、奖励和超参数配置的单阶段强化学习(RL)设置。我们主要在Unitree G1上使用重新定位的LAFAN1舞蹈序列进行评估,并在H1/H1-2上验证迁移。RobotDancing可以跟踪多分钟、高能量的行为(跳跃、旋转、车轮),并以高运动跟踪质量零样本部署到硬件。
🔬 方法详解
问题定义:论文旨在解决人形机器人在长时程、高动态运动跟踪中,由于模型与真实环境动力学差异导致的误差累积问题。现有方法直接控制关节角度,无法有效补偿这种差异,导致运动精度下降,甚至任务失败。
核心思路:论文的核心思路是预测残差关节目标,而不是直接预测绝对关节角度。通过学习一个策略来显式地纠正模型与真实环境之间的动力学差异,从而提高运动跟踪的鲁棒性。这种残差控制的思想允许系统在已有控制的基础上进行微调,更有效地适应真实世界的复杂性。
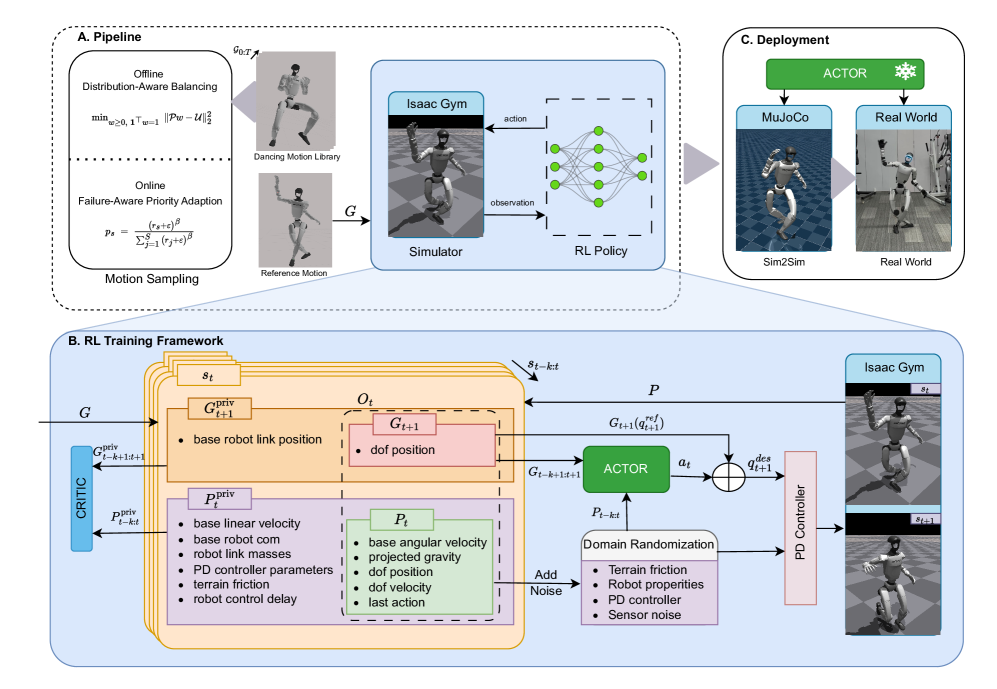
技术框架:RobotDancing采用端到端的强化学习框架。整个流程包括:1) 在模拟环境中训练强化学习策略;2) 在模拟环境中进行验证;3) 将训练好的策略零样本迁移到真实机器人上。该框架使用统一的观察空间、奖励函数和超参数配置,简化了训练过程。
关键创新:最重要的技术创新点在于使用残差动作进行控制。与传统的直接控制关节角度的方法相比,残差动作能够更好地适应模型与真实环境之间的差异,从而提高运动跟踪的鲁棒性。此外,该框架实现了端到端的训练和零样本迁移,简化了部署过程。
关键设计:论文采用单阶段强化学习设置,使用Actor-Critic算法进行训练。奖励函数的设计至关重要,需要平衡跟踪精度、运动平滑性和能量消耗。具体的网络结构和超参数设置在论文中进行了详细描述,并针对Unitree G1、H1/H1-2等不同机器人平台进行了优化。
🖼️ 关键图片


📊 实验亮点
RobotDancing在Unitree G1机器人上成功实现了多分钟、高能量的运动跟踪,包括跳跃、旋转、车轮等复杂动作。实验结果表明,该方法能够以高运动跟踪质量零样本部署到硬件。此外,该方法还在H1/H1-2机器人上进行了验证,证明了其具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于人形机器人的运动控制、舞蹈表演、体育训练等领域。通过提高人形机器人的运动跟踪精度和鲁棒性,可以使其在复杂环境中执行更复杂的任务,例如搜救、巡检等。此外,该方法还可以推广到其他类型的机器人,例如四足机器人、机械臂等。
📄 摘要(原文)
Long-horizon, high-dynamic motion tracking on humanoids remains brittle because absolute joint commands cannot compensate model-plant mismatch, leading to error accumulation. We propose RobotDancing, a simple, scalable framework that predicts residual joint targets to explicitly correct dynamics discrepancies. The pipeline is end-to-end--training, sim-to-sim validation, and zero-shot sim-to-real--and uses a single-stage reinforcement learning (RL) setup with a unified observation, reward, and hyperparameter configuration. We evaluate primarily on Unitree G1 with retargeted LAFAN1 dance sequences and validate transfer on H1/H1-2. RobotDancing can track multi-minute, high-energy behaviors (jumps, spins, cartwheels) and deploys zero-shot to hardware with high motion tracking quality.