Joint Flow Trajectory Optimization For Feasible Robot Motion Generation from Video Demonstrations
作者: Xiaoxiang Dong, Matthew Johnson-Roberson, Weiming Zhi
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-09-25
💡 一句话要点
提出Joint Flow Trajectory Optimization框架,解决视频示教中机器人运动规划问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 示教学习 运动规划 轨迹优化 流匹配
📋 核心要点
- 现有方法难以直接将人类视频演示迁移到机器人操作,主要挑战在于机器人具身差异和关节可行性约束。
- JFTO框架将视频示教视为物体中心引导,通过联合优化抓取姿态、物体轨迹和碰撞避免,实现可行机器人运动生成。
- 通过在模拟和真实世界实验中验证,JFTO框架在多种操作任务中表现出良好的性能。
📝 摘要(中文)
本文提出了一种名为Joint Flow Trajectory Optimization (JFTO) 的框架,用于在基于视频的示教学习 (LfD) 范式下生成抓取姿态和模仿物体轨迹,从而解决机器人操作中的具身差异和关节可行性约束问题。该方法不直接模仿人手运动,而是将演示视为以物体为中心的引导,平衡三个目标:(i) 选择可行的抓取姿态,(ii) 生成与演示运动一致的物体轨迹,以及 (iii) 确保在机器人运动学范围内无碰撞执行。为了捕捉演示的多模态特性,我们将流匹配扩展到 $\SE(3)$,用于物体轨迹的概率建模,从而实现避免模式崩溃的密度感知模仿。最终的优化将抓取相似性、轨迹似然性和碰撞惩罚整合到一个统一的可微目标中。我们在模拟和真实世界的实验中验证了该方法在各种真实操作任务中的有效性。
🔬 方法详解
问题定义:现有基于视频的示教学习方法在机器人操作中面临挑战,因为人类和机器人的具身差异以及机器人关节运动的物理限制。直接模仿人类手部动作通常不可行,且难以保证机器人运动的安全性和可行性。因此,需要一种方法能够从人类演示视频中提取关键信息,并将其转化为机器人可执行的运动轨迹,同时满足机器人的运动学约束和避免碰撞。
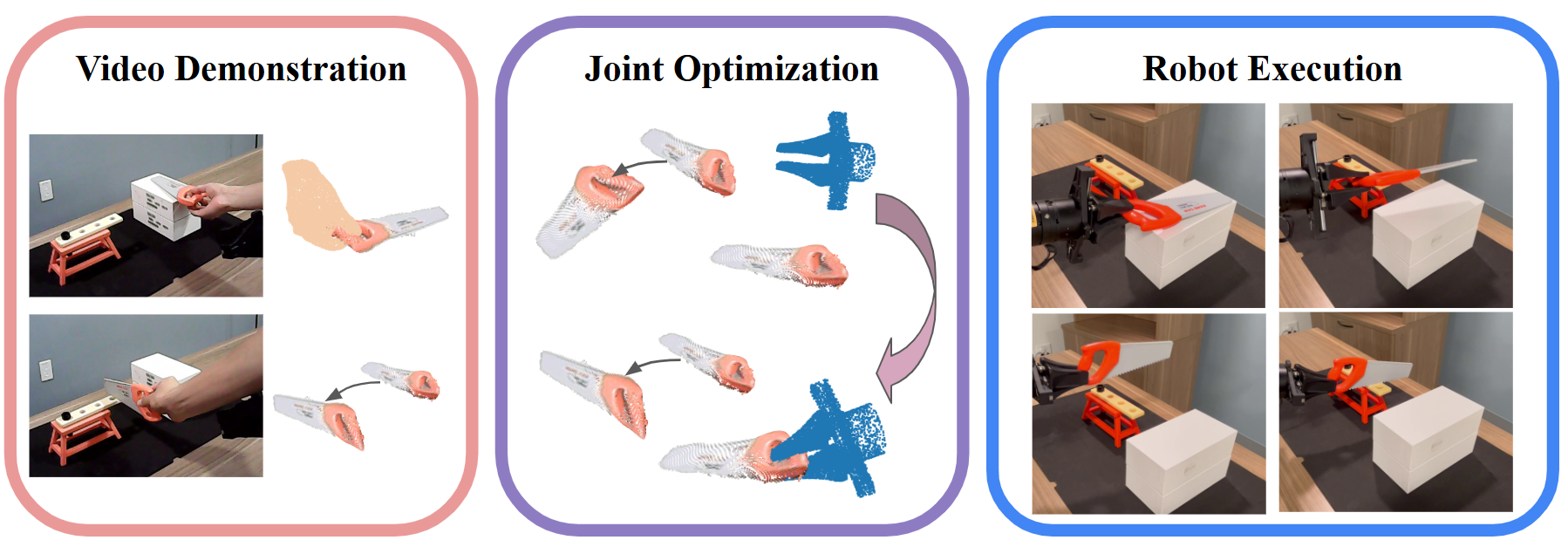
核心思路:JFTO框架的核心思想是将人类演示视频视为物体运动的引导,而不是直接模仿人类的手部动作。通过优化抓取姿态、物体轨迹和碰撞避免,生成机器人可执行的运动轨迹。这种以物体为中心的策略能够更好地适应机器人和人类之间的具身差异,并确保生成的轨迹满足机器人的运动学约束。
技术框架:JFTO框架包含以下主要模块:1) 抓取姿态生成:从视频中提取物体信息,并生成一系列候选抓取姿态。2) 物体轨迹模仿:使用流匹配方法对视频中的物体运动轨迹进行建模,并生成与演示运动一致的物体轨迹。3) 碰撞避免:考虑机器人的运动学约束和环境中的障碍物,对生成的轨迹进行优化,以避免碰撞。4) 联合优化:将抓取相似性、轨迹似然性和碰撞惩罚整合到一个统一的可微目标中,通过优化该目标函数,生成最终的机器人运动轨迹。
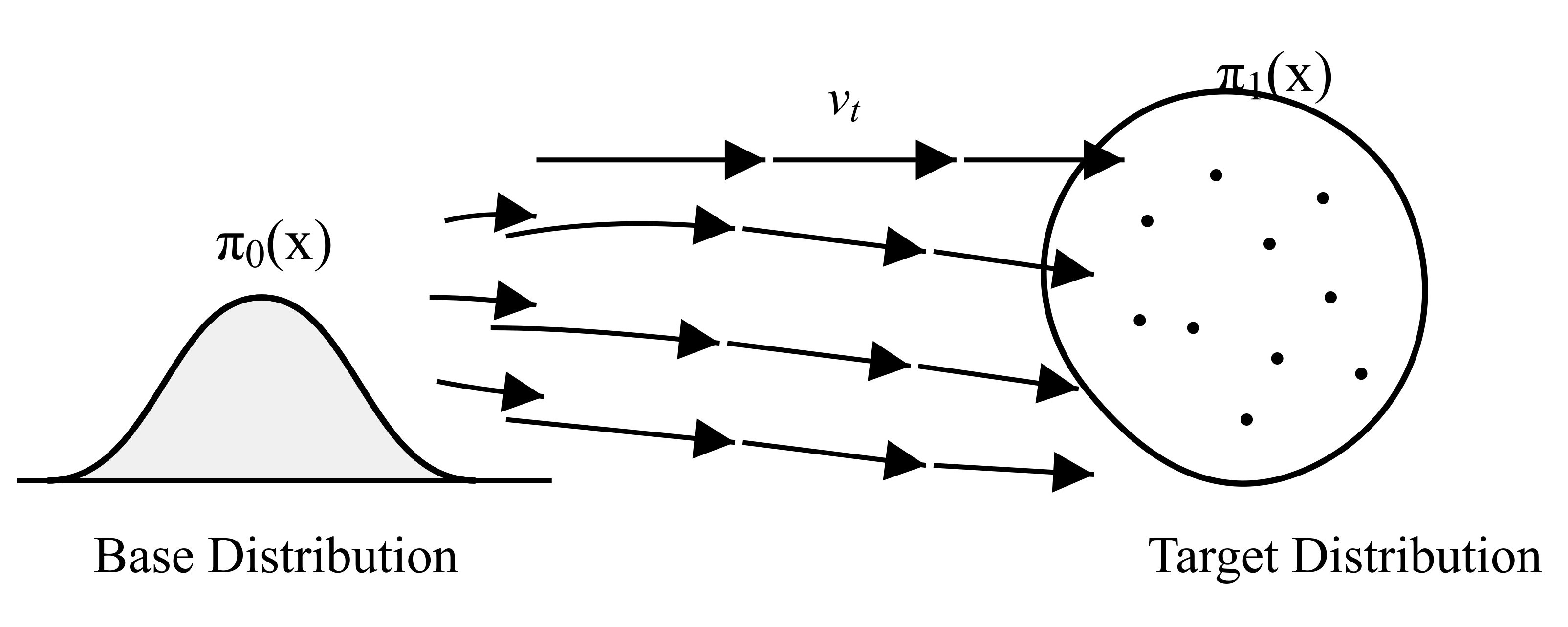
关键创新:JFTO框架的关键创新在于:1) 将流匹配扩展到$\SE(3)$,用于物体轨迹的概率建模,从而能够捕捉演示的多模态特性,并避免模式崩溃。2) 将抓取姿态生成、物体轨迹模仿和碰撞避免整合到一个统一的优化框架中,从而能够同时考虑多个目标,并生成满足所有约束的机器人运动轨迹。3) 采用以物体为中心的策略,能够更好地适应机器人和人类之间的具身差异。
关键设计:JFTO框架的关键设计包括:1) 使用高斯混合模型对抓取姿态进行建模,并使用抓取相似性度量来评估候选抓取姿态的质量。2) 使用流匹配方法对物体运动轨迹进行建模,并使用轨迹似然函数来评估生成的轨迹与演示运动的一致性。3) 使用碰撞惩罚函数来避免机器人与环境中的障碍物发生碰撞。4) 使用可微优化器来优化联合目标函数,并生成最终的机器人运动轨迹。
🖼️ 关键图片

📊 实验亮点
实验结果表明,JFTO框架能够在模拟和真实世界环境中成功生成机器人运动轨迹,完成各种操作任务。与直接模仿人类手部动作的方法相比,JFTO框架能够更好地适应机器人和人类之间的具身差异,并生成满足机器人运动学约束和避免碰撞的轨迹。具体性能数据未知,但论文强调了其在多种真实操作任务中的有效性。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如装配、抓取、放置等。通过学习人类演示视频,机器人可以快速掌握新的操作技能,从而提高生产效率和降低成本。此外,该方法还可以应用于人机协作场景,例如辅助残疾人完成日常任务。
📄 摘要(原文)
Learning from human video demonstrations offers a scalable alternative to teleoperation or kinesthetic teaching, but poses challenges for robot manipulators due to embodiment differences and joint feasibility constraints. We address this problem by proposing the Joint Flow Trajectory Optimization (JFTO) framework for grasp pose generation and object trajectory imitation under the video-based Learning-from-Demonstration (LfD) paradigm. Rather than directly imitating human hand motions, our method treats demonstrations as object-centric guides, balancing three objectives: (i) selecting a feasible grasp pose, (ii) generating object trajectories consistent with demonstrated motions, and (iii) ensuring collision-free execution within robot kinematics. To capture the multimodal nature of demonstrations, we extend flow matching to $\SE(3)$ for probabilistic modeling of object trajectories, enabling density-aware imitation that avoids mode collapse. The resulting optimization integrates grasp similarity, trajectory likelihood, and collision penalties into a unified differentiable objective. We validate our approach in both simulation and real-world experiments across diverse real-world manipulation tasks.