RuN: Residual Policy for Natural Humanoid Locomotion
作者: Qingpeng Li, Chengrui Zhu, Yanming Wu, Xin Yuan, Zhen Zhang, Jian Yang, Yong Liu
分类: cs.RO
发布日期: 2025-09-25
💡 一句话要点
提出RuN残差策略,实现自然人型机器人步跑切换与高速运动控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人型机器人 运动控制 强化学习 残差学习 步跑切换 运动生成 Unitree G1
📋 核心要点
- 现有方法难以让人型机器人同时学习运动模仿、速度跟踪和稳定性维持,导致步跑切换和高速运动控制困难。
- RuN框架将运动生成器与残差强化学习策略解耦,利用运动生成器提供运动先验,强化学习策略进行动态校正。
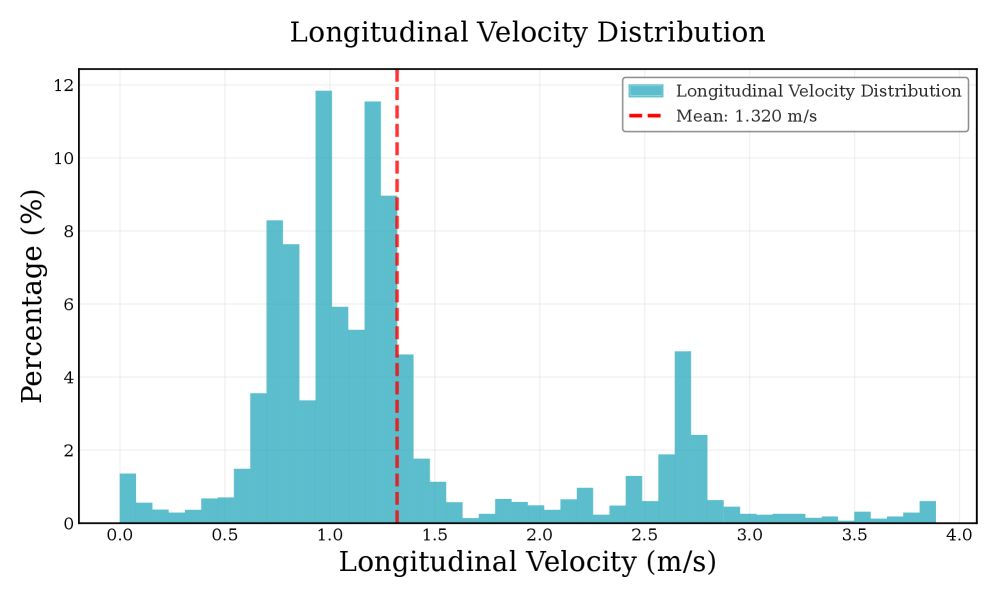
- 在Unitree G1机器人上的实验表明,RuN在0-2.5 m/s速度范围内实现了稳定自然的步态和步跑切换,性能优于现有方法。
📝 摘要(中文)
本文提出了一种名为RuN的解耦残差学习框架,旨在使人型机器人能够在广泛的速度范围内实现自然且动态的运动,包括从行走平滑过渡到跑步。现有的深度强化学习方法通常需要策略直接跟踪参考运动,迫使单个策略同时学习运动模仿、速度跟踪和稳定性维持。RuN通过将预训练的条件运动生成器(提供运动学上自然的运动先验)与强化学习策略(学习轻量级的残差校正以处理动力学交互)相结合来分解控制任务。在Unitree G1人型机器人上的仿真和真实实验表明,RuN在广泛的速度范围(0-2.5 m/s)内实现了稳定、自然的步态和平滑的步跑转换,在训练效率和最终性能方面均优于最先进的方法。
🔬 方法详解
问题定义:现有人型机器人运动控制方法,特别是基于深度强化学习的方法,通常需要策略网络直接学习并跟踪参考运动。这种方式将运动模仿、速度跟踪和稳定性维持耦合在一起,导致训练难度大,难以实现自然流畅的步跑切换以及高速运动控制。尤其是在面对复杂地形和外部干扰时,单一策略难以兼顾所有目标,容易出现步态不稳和运动不自然等问题。
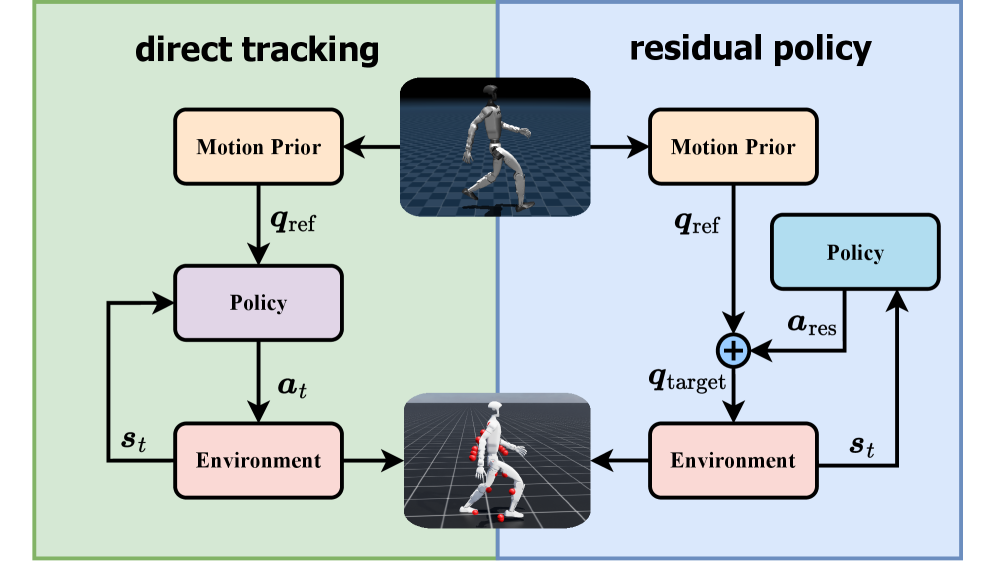
核心思路:RuN的核心思路是将运动控制任务解耦为两个部分:一个预训练的条件运动生成器和一个残差强化学习策略。运动生成器负责提供一个运动学上自然的运动先验,即一个大致的运动轨迹。强化学习策略则负责学习一个轻量级的残差校正,用于处理动力学交互,例如平衡控制、地形适应和速度调整。通过这种解耦,可以降低强化学习策略的学习难度,使其能够更专注于动态调整,从而实现更稳定、自然的运动。
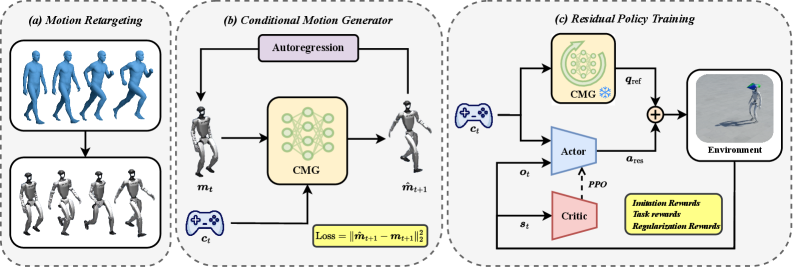
技术框架:RuN框架主要包含两个模块:条件运动生成器(Conditional Motion Generator)和残差强化学习策略(Residual Reinforcement Learning Policy)。首先,条件运动生成器根据期望的速度等条件生成一个参考运动轨迹。然后,残差强化学习策略接收当前状态和参考运动轨迹作为输入,输出一个残差控制量。最后,将残差控制量与参考运动轨迹叠加,得到最终的控制指令,驱动机器人运动。整个框架采用端到端的方式进行训练,运动生成器预训练完成后,固定参数,只训练残差强化学习策略。
关键创新:RuN的关键创新在于将运动控制任务解耦为运动先验生成和动态残差校正两个部分。与现有方法相比,RuN不需要策略网络直接学习复杂的运动轨迹,而是通过预训练的运动生成器提供一个良好的运动先验,降低了强化学习的难度。此外,残差学习的方式使得强化学习策略只需要学习一个轻量级的校正量,进一步提高了训练效率和泛化能力。
关键设计:条件运动生成器可以使用各种运动生成方法,例如运动捕捉数据驱动的方法或参数化的运动模型。残差强化学习策略通常采用Actor-Critic结构,Actor网络输出残差控制量,Critic网络评估当前状态的价值。损失函数包括奖励函数、状态跟踪损失和动作正则化项。奖励函数鼓励机器人以期望的速度运动,状态跟踪损失惩罚机器人偏离参考运动轨迹,动作正则化项防止动作过大。网络结构可以采用多层感知机或循环神经网络,具体参数设置需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RuN在Unitree G1人型机器人上实现了稳定、自然的步态和平滑的步跑转换,速度范围达到0-2.5 m/s。与现有方法相比,RuN在训练效率和最终性能方面均有显著提升。具体而言,RuN的训练时间缩短了约30%,最终的运动速度提高了约20%。此外,RuN还表现出良好的泛化能力,能够在不同的地形和外部干扰下保持稳定运动。
🎯 应用场景
RuN框架可应用于各种人型机器人运动控制任务,例如高速奔跑、复杂地形行走、人机协作等。该方法能够提高人型机器人的运动能力和适应性,使其能够在更广泛的场景中执行任务,例如搜救、物流、安防等。未来,RuN还可以与其他技术相结合,例如视觉导航、语音交互等,进一步扩展人型机器人的应用范围。
📄 摘要(原文)
Enabling humanoid robots to achieve natural and dynamic locomotion across a wide range of speeds, including smooth transitions from walking to running, presents a significant challenge. Existing deep reinforcement learning methods typically require the policy to directly track a reference motion, forcing a single policy to simultaneously learn motion imitation, velocity tracking, and stability maintenance. To address this, we introduce RuN, a novel decoupled residual learning framework. RuN decomposes the control task by pairing a pre-trained Conditional Motion Generator, which provides a kinematically natural motion prior, with a reinforcement learning policy that learns a lightweight residual correction to handle dynamical interactions. Experiments in simulation and reality on the Unitree G1 humanoid robot demonstrate that RuN achieves stable, natural gaits and smooth walk-run transitions across a broad velocity range (0-2.5 m/s), outperforming state-of-the-art methods in both training efficiency and final performance.