Latent Activation Editing: Inference-Time Refinement of Learned Policies for Safer Multirobot Navigation
作者: Satyajeet Das, Darren Chiu, Zhehui Huang, Lars Lindemann, Gaurav S. Sukhatme
分类: cs.RO
发布日期: 2025-09-24
💡 一句话要点
提出基于隐空间激活编辑的框架,用于提升多无人机导航的安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多机器人导航 强化学习 安全性 隐空间编辑 激活引导 碰撞避免
📋 核心要点
- 现有强化学习策略在复杂环境中仍易发生碰撞,而重新训练或微调成本高昂,且可能降低已学习的技能。
- 受大语言模型激活引导和计算机视觉隐空间编辑的启发,提出隐空间激活编辑框架,在推理时优化策略,无需修改模型。
- 实验表明,该方法能显著减少多无人机导航中的碰撞,同时保持任务完成,且适用于资源受限的硬件。
📝 摘要(中文)
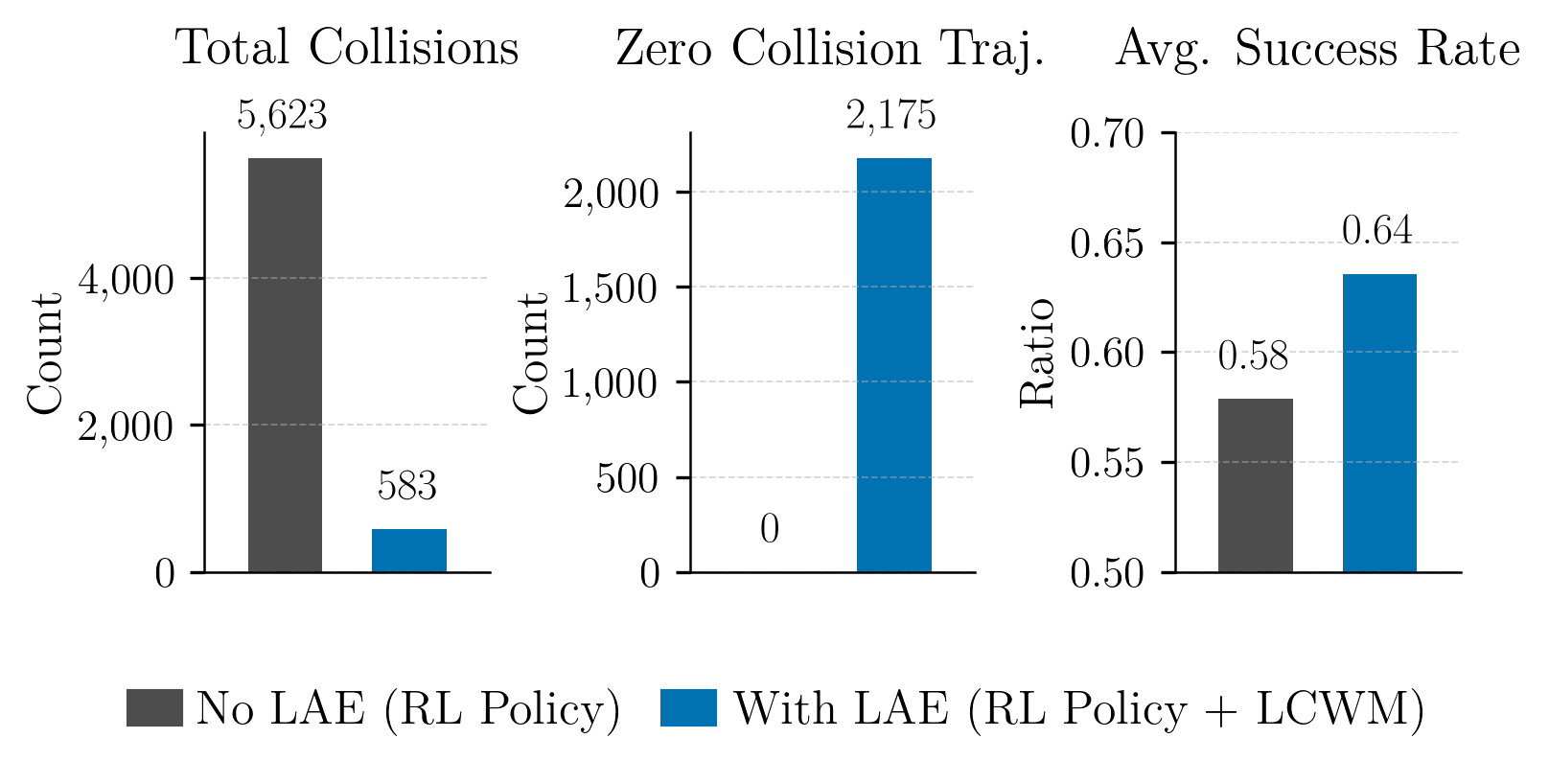
本文提出了一种用于推理时隐空间激活编辑(LAE)的框架,该框架能够在不修改预训练策略的权重或架构的情况下,优化策略行为,从而提升多无人机导航的安全性。该框架包含两个阶段:(i)在线分类器监测中间激活,以检测与不良行为相关的状态;(ii)激活编辑模块选择性地修改被标记的激活,使策略转向更安全的行为。通过训练一个隐空间碰撞世界模型来预测未来的碰撞前激活,从而促使更早、更谨慎的避障反应。大量的仿真和真实世界的Crazyflie实验表明,LAE在显著减少碰撞方面表现出色(与未编辑的基线相比,累积碰撞次数减少了近90%),并大幅增加了无碰撞轨迹的比例,同时保持了任务完成度。LAE为部署后优化机器人策略提供了一种轻量级范例,适用于资源受限的硬件。
🔬 方法详解
问题定义:论文旨在解决多无人机导航中,即使经过良好训练的强化学习策略仍然容易发生碰撞的问题。现有方法,如重新训练或微调,成本高昂,并且可能损害已经学习到的技能。因此,需要一种轻量级的方法,能够在不修改模型权重的情况下,提升策略的安全性。
核心思路:论文的核心思路是通过在推理时修改策略的中间激活值,来引导策略朝着更安全的方向发展。具体来说,通过放大策略对风险的内部感知,可以促使策略更早、更谨慎地采取避障措施。这种方法类似于大语言模型中的激活引导和计算机视觉中的隐空间编辑,能够在不改变模型本身的情况下,改变模型的行为。
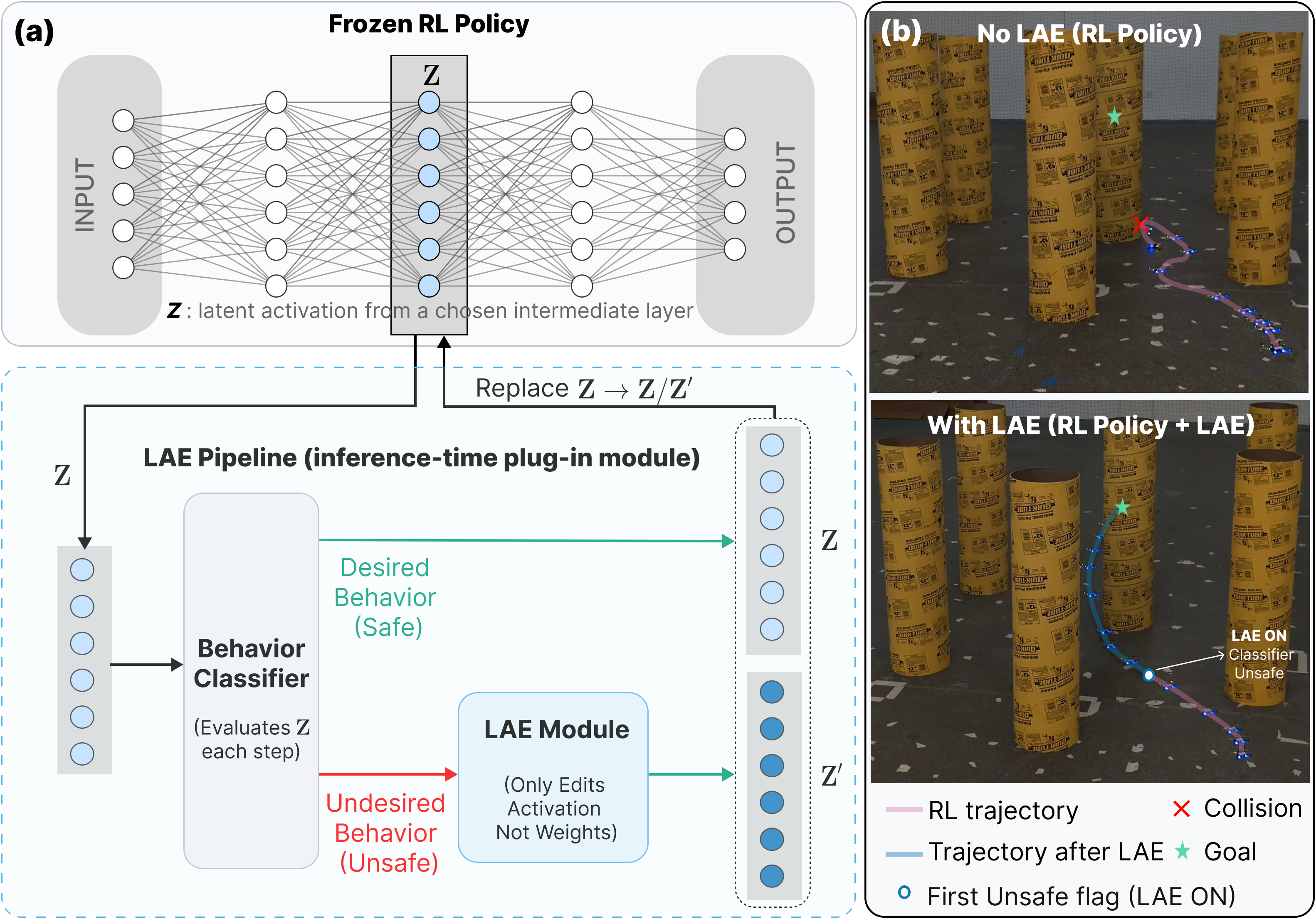
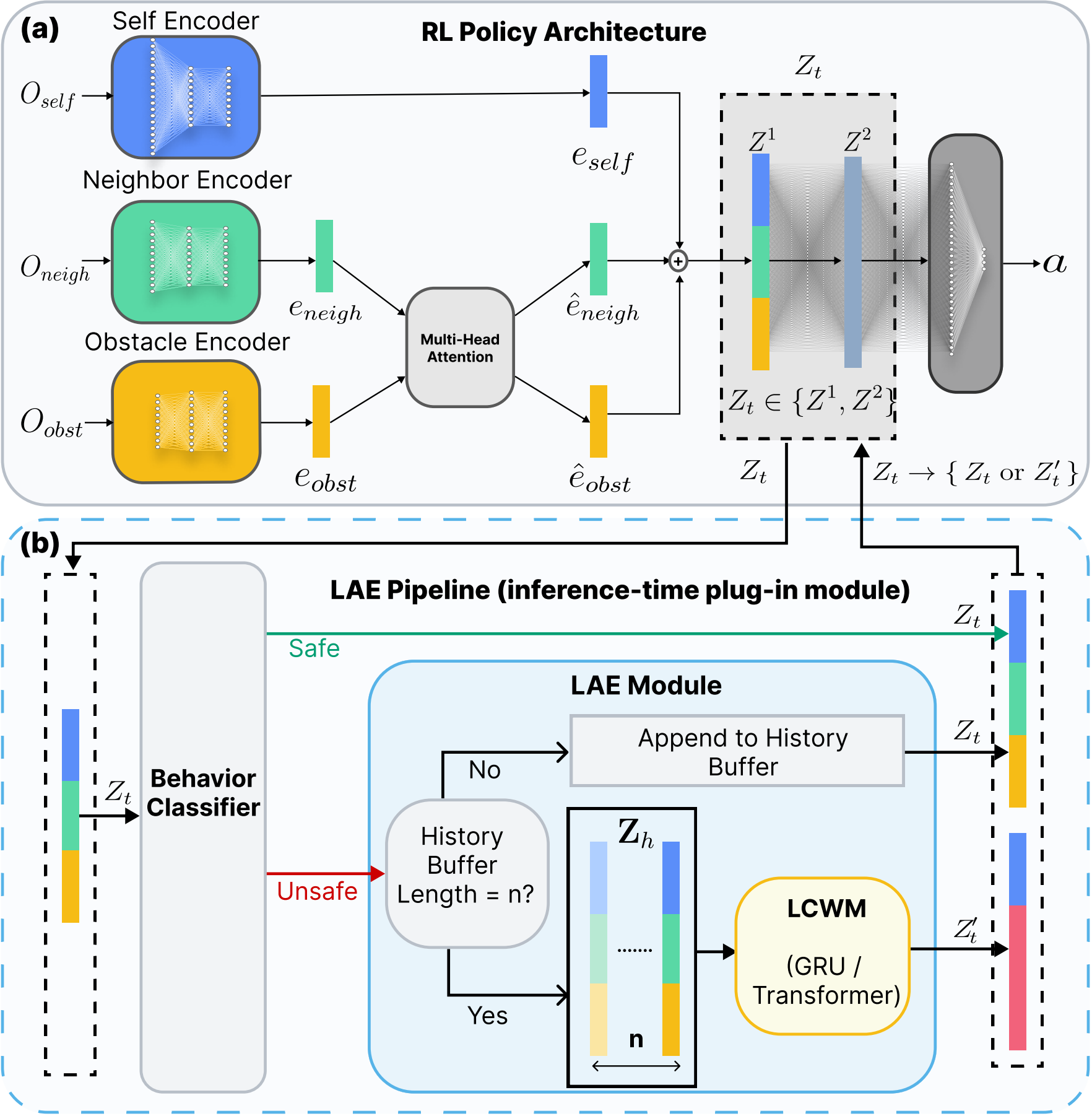
技术框架:LAE框架包含两个主要模块:(1) 在线分类器:该模块负责监测策略的中间激活值,并检测与不良行为(如即将发生碰撞)相关的状态。可以使用任何合适的分类器,例如神经网络或支持向量机。(2) 激活编辑模块:该模块接收来自在线分类器的输出,并选择性地修改被标记为与不良行为相关的激活值。修改的方式可以是简单的加权求和,也可以是更复杂的非线性变换。整个流程是在推理时进行的,因此不需要重新训练模型。
关键创新:该论文的关键创新在于提出了隐空间激活编辑的概念,并将其应用于多无人机导航的安全提升。与传统的重新训练或微调方法相比,LAE是一种更轻量级、更高效的方法,能够在不修改模型权重的情况下,显著提升策略的安全性。此外,论文还提出了使用隐空间碰撞世界模型来预测未来碰撞前激活的方法,从而能够更早地采取避障措施。
关键设计:论文的关键设计包括:(1) 隐空间碰撞世界模型:该模型用于预测未来的碰撞前激活,从而能够更早地检测到潜在的碰撞风险。模型的具体结构和训练方法未知。(2) 激活编辑策略:论文采用了一种简单的加权求和方法来修改激活值,但也可以使用更复杂的非线性变换。具体参数设置未知。(3) 在线分类器:论文中使用的在线分类器的具体类型和训练方法未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LAE能够显著减少多无人机导航中的碰撞。在仿真环境中,与未编辑的基线相比,LAE能够减少近90%的累积碰撞次数,并大幅增加无碰撞轨迹的比例。在真实世界的Crazyflie实验中,也观察到了类似的性能提升。这些结果表明,LAE是一种有效的安全提升方法。
🎯 应用场景
该研究成果可应用于各种多机器人协作导航场景,尤其是在安全性要求高的环境中,例如仓库物流、灾难救援、以及自动驾驶等。通过在推理时对策略进行微调,可以有效降低碰撞风险,提高系统的可靠性和安全性,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
Reinforcement learning has enabled significant progress in complex domains such as coordinating and navigating multiple quadrotors. However, even well-trained policies remain vulnerable to collisions in obstacle-rich environments. Addressing these infrequent but critical safety failures through retraining or fine-tuning is costly and risks degrading previously learned skills. Inspired by activation steering in large language models and latent editing in computer vision, we introduce a framework for inference-time Latent Activation Editing (LAE) that refines the behavior of pre-trained policies without modifying their weights or architecture. The framework operates in two stages: (i) an online classifier monitors intermediate activations to detect states associated with undesired behaviors, and (ii) an activation editing module that selectively modifies flagged activations to shift the policy towards safer regimes. In this work, we focus on improving safety in multi-quadrotor navigation. We hypothesize that amplifying a policy's internal perception of risk can induce safer behaviors. We instantiate this idea through a latent collision world model trained to predict future pre-collision activations, thereby prompting earlier and more cautious avoidance responses. Extensive simulations and real-world Crazyflie experiments demonstrate that LAE achieves statistically significant reduction in collisions (nearly 90% fewer cumulative collisions compared to the unedited baseline) and substantially increases the fraction of collision-free trajectories, while preserving task completion. More broadly, our results establish LAE as a lightweight paradigm, feasible on resource-constrained hardware, for post-deployment refinement of learned robot policies.