Parse-Augment-Distill: Learning Generalizable Bimanual Visuomotor Policies from Single Human Video
作者: Georgios Tziafas, Jiayun Zhang, Hamidreza Kasaei
分类: cs.RO
发布日期: 2025-09-24
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出PAD框架,从单个人类视频学习可泛化的双臂操作策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双臂操作 模仿学习 关键点表示 任务和运动规划 蒸馏学习 机器人学习 泛化能力
📋 核心要点
- 现有方法依赖大量遥操作数据,泛化性差,且基于模拟的增强引入了sim-to-real差距。
- PAD框架通过解析人类视频为关键点轨迹,利用任务和运动规划进行无模拟增强,再蒸馏成策略。
- 实验表明,PAD在成功率和效率上优于现有方法,并在真实世界的双臂任务中实现了良好的泛化。
📝 摘要(中文)
从专家演示中学习视觉运动策略是现代机器人研究的重要前沿,然而,大多数流行方法需要大量精力来收集遥操作数据,并且难以泛化到分布外。扩展数据收集已通过利用人类视频以及演示增强技术进行了探索。后一种方法通常需要昂贵的模拟rollout,并使用合成图像数据训练策略,因此引入了sim-to-real差距。同时,诸如关键点之类的替代状态表示已显示出在类别级别泛化的巨大希望。在这项工作中,我们将这些途径整合到一个统一的框架中:PAD(Parse-Augment-Distill),用于从单个人的视频中学习可泛化的双臂策略。我们的方法依赖于三个步骤:(a)将人的视频演示解析为机器人可执行的关键点-动作轨迹,(b)采用双臂任务和运动规划来大规模地增强演示,而无需模拟器,以及(c)将增强的轨迹提炼成关键点条件策略。在经验上,我们展示了PAD在成功率和样本/成本效率方面均优于依赖于具有模拟rollout的图像策略的最新双臂演示增强工作。我们在六个不同的现实世界双臂任务中部署了我们的框架,例如倒饮料,清理垃圾和打开容器,从而产生可以在看不见的空间排列,对象实例和背景干扰物中泛化的单样本策略。
🔬 方法详解
问题定义:现有双臂操作策略学习方法依赖于大量的遥操作数据,收集成本高昂。同时,基于模拟的增强方法存在sim-to-real的gap,限制了策略在真实世界的泛化能力。因此,如何从少量(甚至单个)人类视频中学习到具有良好泛化能力的双臂操作策略是一个关键问题。
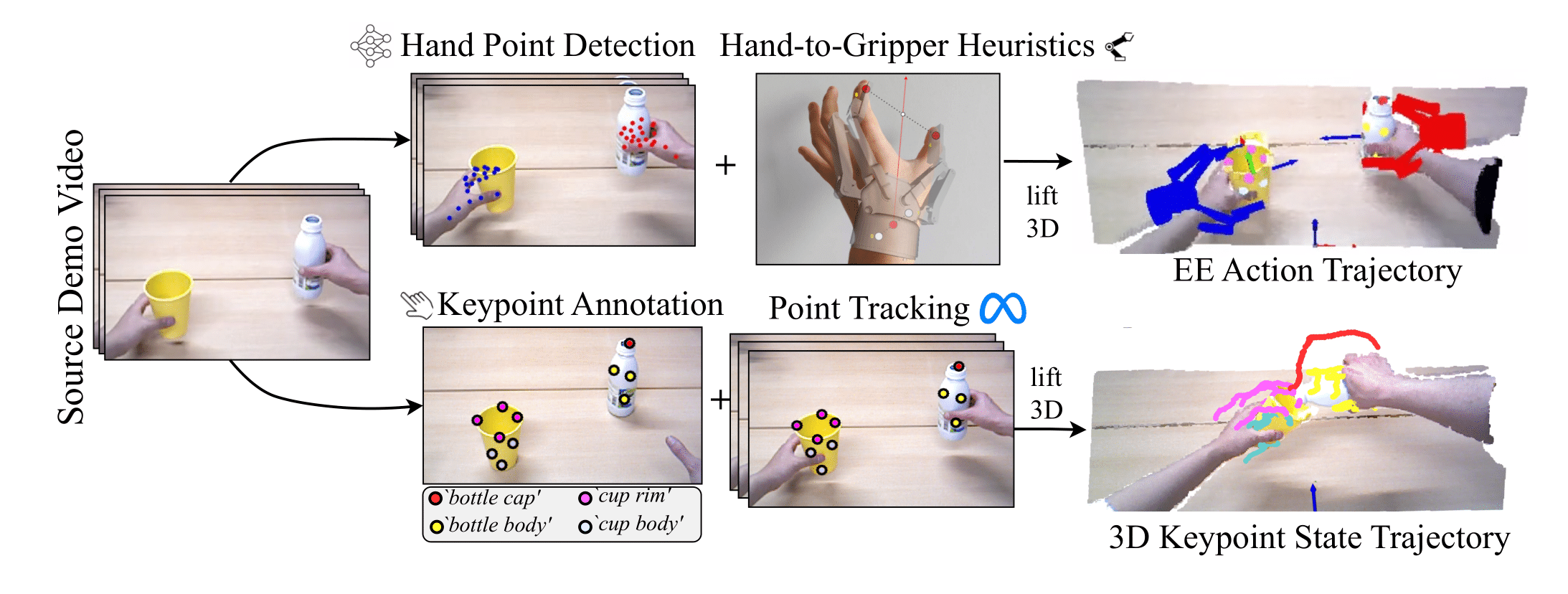
核心思路:PAD框架的核心思路是将人类视频解析为机器人可执行的关键点-动作轨迹,然后利用双臂任务和运动规划进行数据增强,最后通过蒸馏学习得到关键点条件策略。这种方法避免了昂贵的模拟rollout,并利用关键点作为中间表示,提高了策略的泛化能力。
技术框架:PAD框架包含三个主要阶段:1) 解析(Parse):将人类视频演示解析为机器人可执行的关键点-动作轨迹。这通常涉及使用姿态估计模型提取关键点,并使用运动捕捉技术估计动作。2) 增强(Augment):利用双臂任务和运动规划算法,在不同的场景和物体排列下生成新的轨迹。这一步的关键是不依赖于模拟器,而是直接在真实世界中进行规划。3) 蒸馏(Distill):将增强后的轨迹数据用于训练一个关键点条件策略。该策略以关键点作为输入,输出机器人的动作。
关键创新:PAD框架的关键创新在于将关键点表示、任务和运动规划以及蒸馏学习结合在一起,从而实现了从单个人类视频中学习可泛化的双臂操作策略。与现有方法相比,PAD不需要大量的遥操作数据,也不依赖于模拟器,因此具有更高的效率和更好的泛化能力。
关键设计:在解析阶段,可以使用现成的姿态估计模型(如OpenPose)提取关键点。在增强阶段,需要设计合适的任务和运动规划算法,以生成多样化的轨迹数据。在蒸馏阶段,可以使用各种机器学习模型(如神经网络)来学习关键点条件策略。损失函数的设计需要考虑动作的准确性和轨迹的平滑性。
🖼️ 关键图片
📊 实验亮点
PAD框架在六个不同的真实世界双臂任务(例如倒饮料,清理垃圾和打开容器)中进行了评估,结果表明,PAD在成功率和样本/成本效率方面均优于依赖于具有模拟rollout的图像策略的最新双臂演示增强工作。PAD能够生成可以在看不见的空间排列,对象实例和背景干扰物中泛化的单样本策略。
🎯 应用场景
该研究成果可应用于各种需要双臂操作的机器人任务,例如家庭服务机器人、工业自动化机器人和医疗辅助机器人。通过从少量人类演示中学习,机器人可以快速适应新的任务和环境,从而提高其灵活性和实用性。未来,该方法还可以扩展到更复杂的任务和更通用的机器人平台。
📄 摘要(原文)
Learning visuomotor policies from expert demonstrations is an important frontier in modern robotics research, however, most popular methods require copious efforts for collecting teleoperation data and struggle to generalize out-ofdistribution. Scaling data collection has been explored through leveraging human videos, as well as demonstration augmentation techniques. The latter approach typically requires expensive simulation rollouts and trains policies with synthetic image data, therefore introducing a sim-to-real gap. In parallel, alternative state representations such as keypoints have shown great promise for category-level generalization. In this work, we bring these avenues together in a unified framework: PAD (Parse-AugmentDistill), for learning generalizable bimanual policies from a single human video. Our method relies on three steps: (a) parsing a human video demo into a robot-executable keypoint-action trajectory, (b) employing bimanual task-and-motion-planning to augment the demonstration at scale without simulators, and (c) distilling the augmented trajectories into a keypoint-conditioned policy. Empirically, we showcase that PAD outperforms state-ofthe-art bimanual demonstration augmentation works relying on image policies with simulation rollouts, both in terms of success rate and sample/cost efficiency. We deploy our framework in six diverse real-world bimanual tasks such as pouring drinks, cleaning trash and opening containers, producing one-shot policies that generalize in unseen spatial arrangements, object instances and background distractors. Supplementary material can be found in the project webpage https://gtziafas.github.io/PAD_project/.