Queryable 3D Scene Representation: A Multi-Modal Framework for Semantic Reasoning and Robotic Task Planning
作者: Xun Li, Rodrigo Santa Cruz, Mingze Xi, Hu Zhang, Madhawa Perera, Ziwei Wang, Ahalya Ravendran, Brandon J. Matthews, Feng Xu, Matt Adcock, Dadong Wang, Jiajun Liu
分类: cs.RO, cs.CV, cs.HC
发布日期: 2025-09-24
期刊: MM '25: Proceedings of the 33rd ACM International Conference on Multimedia (2025) Pages 12492 - 12500
💡 一句话要点
提出3D可查询场景表示,用于语义推理和机器人任务规划
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景表示 语义推理 机器人任务规划 多模态融合 视觉-语言模型
📋 核心要点
- 现有方法难以将精确几何结构与丰富的语义信息有效融合,阻碍了机器人对复杂场景的理解。
- 提出3D可查询场景表示(3D QSR),融合多模态数据,实现场景的语义可查询性。
- 在模拟和真实环境中验证了QSR在机器人任务规划中的有效性,能够将高级指令转化为精确动作。
📝 摘要(中文)
为了使机器人能够理解高级人类指令并执行复杂任务,关键挑战在于实现全面的场景理解:以有意义的方式解释和与3D环境交互。为此,我们引入了3D可查询场景表示(3D QSR),这是一个建立在多媒体数据上的新框架,它统一了三个互补的3D表示:(1)来自全景重建的3D一致的新视角渲染和分割,(2)来自3D点云的精确几何结构,以及(3)通过3D场景图实现的结构化、可扩展的组织。该框架基于以对象为中心的设计,与大型视觉-语言模型集成,通过链接多模态对象嵌入来实现语义可查询性,并支持对象级别的几何、视觉和语义信息检索。检索到的数据随后被加载到机器人任务规划器中以供下游执行。我们通过Unity中模拟的机器人任务规划场景评估了我们的方法,这些场景由抽象的语言指令引导,并使用室内公共数据集Replica。此外,我们将其应用于真实湿实验室环境的数字副本中,以测试QSR支持的机器人任务规划在紧急响应中的应用。结果表明,该框架能够促进场景理解并整合空间和语义推理,从而有效地将高级人类指令转化为复杂3D环境中的精确机器人任务规划。
🔬 方法详解
问题定义:现有机器人场景理解方法难以将精确的几何结构与人类可理解的丰富语义信息有效融合,导致机器人难以理解高级指令并在复杂环境中执行任务。痛点在于缺乏一个能够同时表示几何、视觉和语义信息,并支持高效查询和推理的统一框架。
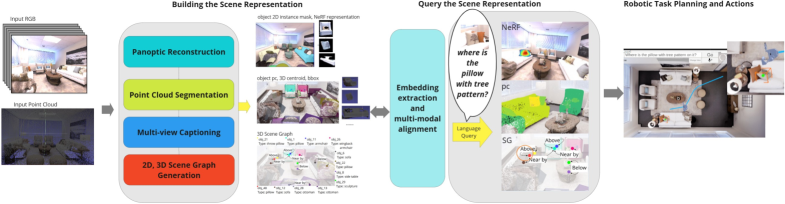
核心思路:论文的核心思路是构建一个多模态的3D场景表示,将几何信息(3D点云)、视觉信息(全景重建)和语义信息(3D场景图)融合在一起,并利用视觉-语言模型实现基于自然语言的语义查询。通过对象中心的设计,将不同模态的信息与对象关联,从而支持对象级别的检索和推理。
技术框架:3D QSR框架包含三个主要模块:1) 全景重建模块,用于生成3D一致的新视角渲染和分割;2) 3D点云模块,用于提供精确的几何结构;3) 3D场景图模块,用于实现结构化和可扩展的场景组织。这些模块通过对象中心的设计进行集成,并与视觉-语言模型连接,实现语义查询功能。整个流程包括场景重建、信息融合、语义查询和任务规划四个阶段。
关键创新:最重要的技术创新点在于将多模态的3D场景表示与视觉-语言模型相结合,实现了基于自然语言的语义查询功能。与现有方法相比,QSR能够更全面地表示场景信息,并支持更灵活的交互方式。此外,对象中心的设计也使得信息检索和推理更加高效。
关键设计:论文中关键的设计包括:1) 使用全景重建技术生成高质量的视觉信息;2) 利用3D场景图实现场景的结构化表示;3) 通过多模态对象嵌入将几何、视觉和语义信息关联起来;4) 使用视觉-语言模型实现自然语言查询接口。具体的参数设置、损失函数和网络结构等细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文在Unity模拟环境和真实湿实验室环境中进行了实验验证。结果表明,该框架能够有效地将高级人类指令转化为精确的机器人任务规划。虽然论文中没有给出具体的性能数据和对比基线,但实验结果定性地展示了QSR在复杂3D环境中的有效性。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、自动驾驶、虚拟现实等领域。例如,在紧急救援场景中,机器人可以通过理解人类的指令,快速定位目标物体并执行相应的操作。未来,该技术有望实现更智能、更自主的机器人系统,提升人机交互的效率和安全性。
📄 摘要(原文)
To enable robots to comprehend high-level human instructions and perform complex tasks, a key challenge lies in achieving comprehensive scene understanding: interpreting and interacting with the 3D environment in a meaningful way. This requires a smart map that fuses accurate geometric structure with rich, human-understandable semantics. To address this, we introduce the 3D Queryable Scene Representation (3D QSR), a novel framework built on multimedia data that unifies three complementary 3D representations: (1) 3D-consistent novel view rendering and segmentation from panoptic reconstruction, (2) precise geometry from 3D point clouds, and (3) structured, scalable organization via 3D scene graphs. Built on an object-centric design, the framework integrates with large vision-language models to enable semantic queryability by linking multimodal object embeddings, and supporting object-level retrieval of geometric, visual, and semantic information. The retrieved data are then loaded into a robotic task planner for downstream execution. We evaluate our approach through simulated robotic task planning scenarios in Unity, guided by abstract language instructions and using the indoor public dataset Replica. Furthermore, we apply it in a digital duplicate of a real wet lab environment to test QSR-supported robotic task planning for emergency response. The results demonstrate the framework's ability to facilitate scene understanding and integrate spatial and semantic reasoning, effectively translating high-level human instructions into precise robotic task planning in complex 3D environments.