D3Grasp: Diverse and Deformable Dexterous Grasping for General Objects
作者: Keyu Wang, Bingcong Lu, Zhengxue Cheng, Hengdi Zhang, Li Song
分类: cs.RO
发布日期: 2025-09-24
💡 一句话要点
D3Grasp:面向通用物体的多样化和可变形灵巧抓取
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灵巧抓取 强化学习 多模态感知 可变形物体 机器人操作
📋 核心要点
- 现有灵巧抓取方法在高维动作空间和感知不确定性下,难以实现通用和可变形物体的多样化和稳定抓取。
- D3Grasp通过多模态感知融合、非对称强化学习和接触感知的训练策略,提升了抓取的多样性、鲁棒性和对可变形物体的适应性。
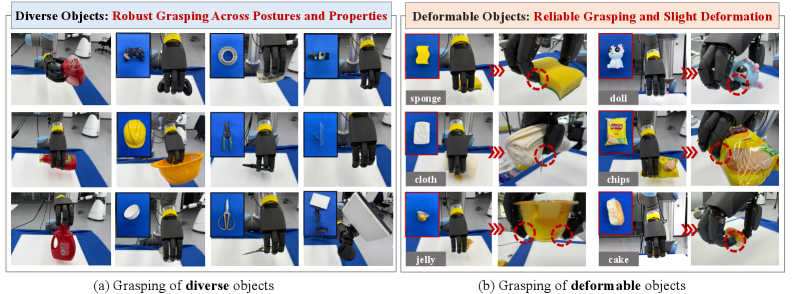
- 实验结果表明,D3Grasp在真实世界中对刚性和可变形物体的抓取成功率达到95.1%,显著优于现有方法。
📝 摘要(中文)
本文提出D3Grasp,一个多模态感知引导的强化学习框架,旨在实现多样化和可变形物体的灵巧抓取。首先,引入统一的多模态表示,整合视觉和触觉感知,以稳健地抓取具有不同属性的常见物体。其次,提出一种非对称强化学习架构,在训练期间利用特权信息,同时保持部署的真实性,从而提高泛化性和样本效率。第三,精心设计了一种训练策略,以合成富含接触、无穿透且运动学上可行的抓取,增强对可变形和接触敏感物体的适应性。大量评估表明,D3Grasp在大型和多样化的物体类别中提供了高度鲁棒的性能,并在可变形和顺应性物体的灵巧抓取方面显著推进了现有技术水平,即使在感知不确定性和真实世界的干扰下也是如此。D3Grasp在真实世界试验中实现了95.1%的平均成功率,优于先前在刚性和可变形物体基准上的方法。
🔬 方法详解
问题定义:论文旨在解决通用物体,特别是可变形物体的多样化和稳定灵巧抓取问题。现有方法在高维动作空间下难以探索有效的抓取策略,并且对感知噪声和物体形变的鲁棒性不足,导致抓取成功率较低。
核心思路:论文的核心思路是利用多模态感知信息(视觉和触觉)来增强对物体的理解,并采用非对称强化学习框架,在训练时利用特权信息(例如物体完整状态),在部署时仅依赖真实可用的信息,从而提高泛化能力和样本效率。此外,通过精心设计的训练策略,生成接触丰富、无穿透且运动学上可行的抓取,以适应可变形物体。
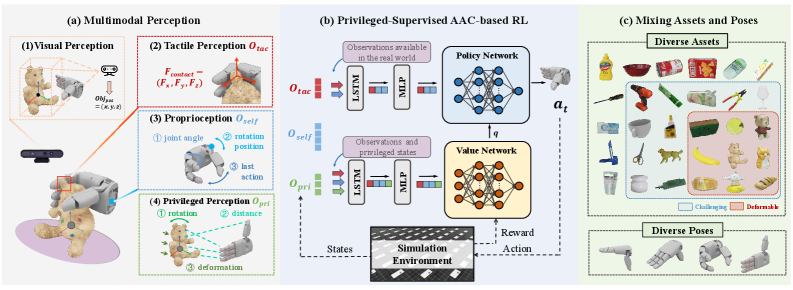
技术框架:D3Grasp的整体框架包含以下几个主要模块:1) 多模态感知模块,融合视觉和触觉信息,生成统一的物体表示;2) 非对称强化学习模块,使用Actor-Critic架构,其中Actor负责生成抓取动作,Critic负责评估抓取质量;3) 训练策略模块,用于生成高质量的训练数据,包括接触丰富、无穿透和运动学上可行的抓取。
关键创新:论文的关键创新在于:1) 提出了统一的多模态表示,有效融合了视觉和触觉信息,增强了对物体的理解;2) 采用了非对称强化学习框架,利用特权信息进行训练,提高了泛化能力和样本效率;3) 设计了接触感知的训练策略,生成高质量的训练数据,提高了对可变形物体的适应性。
关键设计:在多模态感知模块中,使用了卷积神经网络(CNN)提取视觉特征,并使用触觉传感器获取接触信息,然后将两者融合。在非对称强化学习模块中,Actor网络使用多层感知机(MLP)生成抓取动作,Critic网络使用CNN和MLP评估抓取质量。训练策略中,使用了惩罚函数来避免物体穿透和违反运动学约束,并使用奖励函数鼓励接触丰富的抓取。
🖼️ 关键图片

📊 实验亮点
D3Grasp在真实世界试验中取得了显著成果,平均抓取成功率达到95.1%,明显优于现有方法。尤其在可变形物体抓取方面,D3Grasp展现出更强的鲁棒性和适应性。实验结果验证了多模态感知融合、非对称强化学习和接触感知训练策略的有效性。
🎯 应用场景
D3Grasp技术可应用于各种需要灵巧操作的机器人应用场景,例如:家庭服务机器人抓取不同形状和材质的物品、工业机器人处理柔性或易损零件、医疗机器人进行精细手术操作等。该研究有助于提升机器人在复杂环境下的适应性和操作能力,实现更智能、更高效的自动化。
📄 摘要(原文)
Achieving diverse and stable dexterous grasping for general and deformable objects remains a fundamental challenge in robotics, due to high-dimensional action spaces and uncertainty in perception. In this paper, we present D3Grasp, a multimodal perception-guided reinforcement learning framework designed to enable Diverse and Deformable Dexterous Grasping. We firstly introduce a unified multimodal representation that integrates visual and tactile perception to robustly grasp common objects with diverse properties. Second, we propose an asymmetric reinforcement learning architecture that exploits privileged information during training while preserving deployment realism, enhancing both generalization and sample efficiency. Third, we meticulously design a training strategy to synthesize contact-rich, penetration-free, and kinematically feasible grasps with enhanced adaptability to deformable and contact-sensitive objects. Extensive evaluations confirm that D3Grasp delivers highly robust performance across large-scale and diverse object categories, and substantially advances the state of the art in dexterous grasping for deformable and compliant objects, even under perceptual uncertainty and real-world disturbances. D3Grasp achieves an average success rate of 95.1% in real-world trials,outperforming prior methods on both rigid and deformable objects benchmarks.