Beyond Human Demonstrations: Diffusion-Based Reinforcement Learning to Generate Data for VLA Training
作者: Rushuai Yang, Hangxing Wei, Ran Zhang, Zhiyuan Feng, Xiaoyu Chen, Tong Li, Chuheng Zhang, Li Zhao, Jiang Bian, Xiu Su, Yi Chen
分类: cs.RO
发布日期: 2025-09-24 (更新: 2025-09-29)
💡 一句话要点
提出基于扩散模型的强化学习算法,为VLA模型生成高质量训练数据。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 强化学习 视觉-语言-动作模型 机器人操作 轨迹生成
📋 核心要点
- VLA模型依赖大量人工标注数据,成本高昂且限制了模型扩展性,因此需要寻找自动生成高质量训练数据的方法。
- 论文提出一种改进的扩散策略优化算法,利用扩散模型探索复杂行为,并通过去噪过程实现轨迹的平滑和一致性。
- 实验表明,该方法生成的轨迹更优,使用其训练的VLA模型在LIBERO基准测试中超越了人工数据和其他RL方法。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在跨任务和跨具身方面表现出强大的泛化能力。然而,它们对大规模人工演示数据的依赖限制了其可扩展性,因为手动数据收集成本高昂。强化学习(RL)为自主生成演示数据提供了一种潜在的替代方案,但传统的RL算法通常难以应对具有稀疏奖励的长期操作任务。本文提出了一种改进的扩散策略优化算法,以生成高质量和低方差的轨迹,从而构建一个由扩散RL驱动的VLA训练流程。我们的算法不仅受益于扩散模型的高表达性,能够探索复杂多样的行为,还受益于迭代去噪过程的隐式正则化,从而产生平滑和一致的演示数据。我们在包含130个长期操作任务的LIBERO基准上评估了我们的方法,结果表明,生成的轨迹比人工演示数据和标准高斯RL策略生成的轨迹更平滑、更一致。此外,仅使用扩散RL生成的数据训练的VLA模型实现了81.9%的平均成功率,比使用人工数据训练的模型高出+5.3%,比使用高斯RL生成的数据训练的模型高出+12.6%。结果表明,我们的扩散RL是为VLA模型生成丰富、高质量和低方差演示数据的有效替代方案。
🔬 方法详解
问题定义:VLA模型依赖于大量人工标注的演示数据,而人工标注成本高昂且难以扩展。传统的强化学习方法在长时程操作任务中,由于奖励稀疏,难以生成高质量的训练数据。因此,如何自动生成高质量、低方差的VLA模型训练数据是一个关键问题。
核心思路:论文的核心思路是利用扩散模型生成高质量的轨迹数据,并将其用于训练VLA模型。扩散模型具有强大的生成能力和探索能力,能够生成多样化的行为。同时,扩散模型的去噪过程可以隐式地对轨迹进行正则化,使其更加平滑和一致。
技术框架:该方法主要包含两个阶段:首先,使用改进的扩散策略优化算法生成轨迹数据;然后,使用生成的轨迹数据训练VLA模型。扩散策略优化算法基于标准的扩散模型,并针对强化学习任务进行了改进,以提高生成轨迹的质量和效率。VLA模型可以是任何现有的视觉-语言-动作模型。
关键创新:该方法的关键创新在于将扩散模型应用于强化学习,以生成高质量的训练数据。与传统的强化学习方法相比,扩散模型能够更好地探索复杂环境,并生成更加平滑和一致的轨迹。此外,该方法还对扩散策略优化算法进行了改进,以提高其在强化学习任务中的性能。
关键设计:论文中对扩散模型进行了改进,使其更适合强化学习任务。例如,论文可能使用了特定的奖励函数来引导扩散模型的生成过程,或者使用了特定的网络结构来提高扩散模型的表达能力。此外,论文还可能对扩散模型的训练过程进行了优化,以提高其训练效率。
🖼️ 关键图片

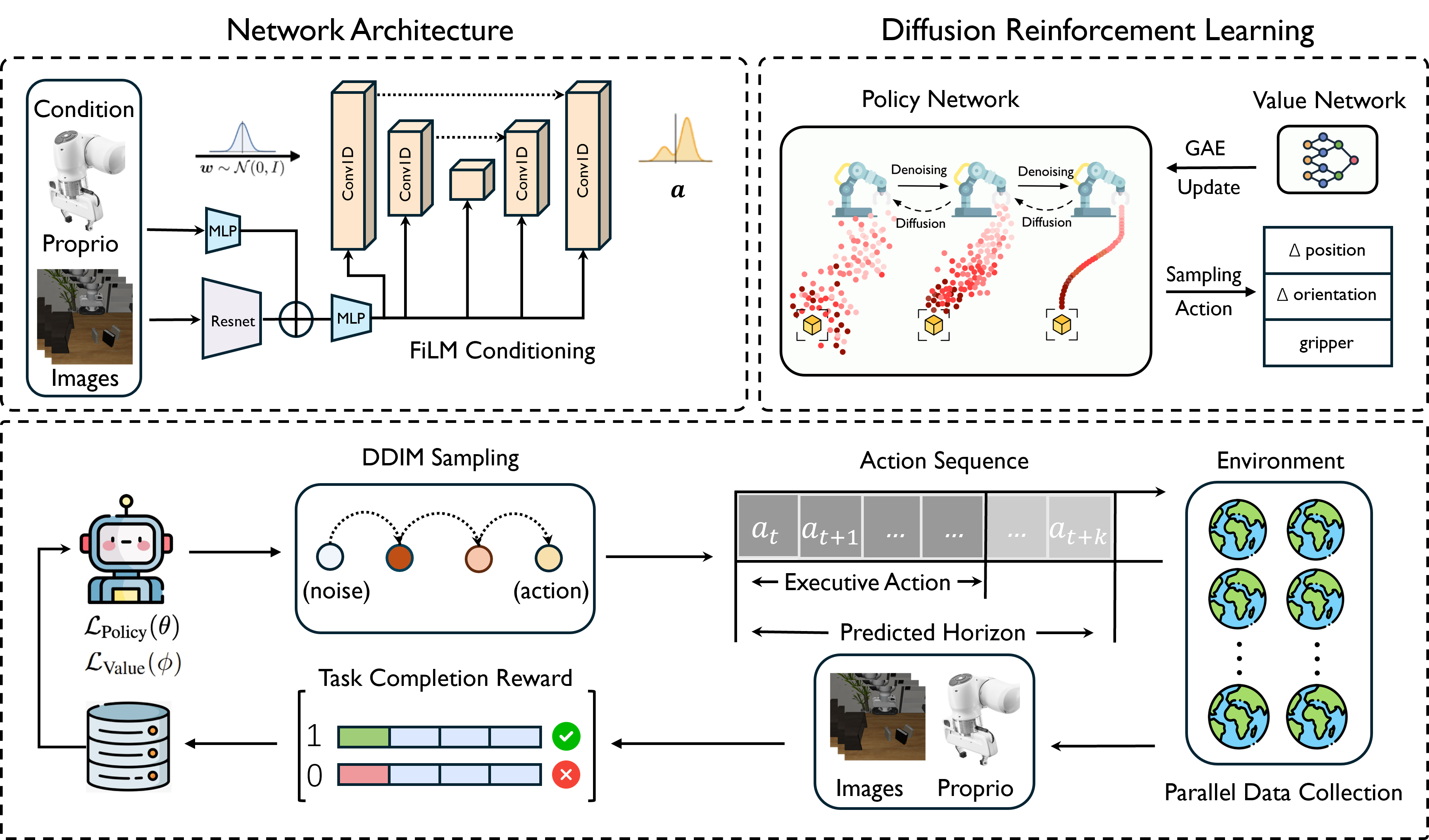

📊 实验亮点
实验结果表明,使用扩散RL生成的数据训练的VLA模型在LIBERO基准测试中取得了显著的性能提升。该模型实现了81.9%的平均成功率,比使用人工数据训练的模型高出+5.3%,比使用高斯RL生成的数据训练的模型高出+12.6%。这表明扩散RL是生成高质量VLA模型训练数据的有效方法。
🎯 应用场景
该研究成果可广泛应用于机器人操作、自动驾驶等领域。通过自动生成高质量的训练数据,可以降低对人工标注数据的依赖,加速VLA模型的开发和部署。此外,该方法还可以应用于其他需要大量训练数据的机器学习任务。
📄 摘要(原文)
Vision-language-action (VLA) models have shown strong generalization across tasks and embodiments; however, their reliance on large-scale human demonstrations limits their scalability owing to the cost and effort of manual data collection. Reinforcement learning (RL) offers a potential alternative to generate demonstrations autonomously, yet conventional RL algorithms often struggle on long-horizon manipulation tasks with sparse rewards. In this paper, we propose a modified diffusion policy optimization algorithm to generate high-quality and low-variance trajectories, which contributes to a diffusion RL-powered VLA training pipeline. Our algorithm benefits from not only the high expressiveness of diffusion models to explore complex and diverse behaviors but also the implicit regularization of the iterative denoising process to yield smooth and consistent demonstrations. We evaluate our approach on the LIBERO benchmark, which includes 130 long-horizon manipulation tasks, and show that the generated trajectories are smoother and more consistent than both human demonstrations and those from standard Gaussian RL policies. Further, training a VLA model exclusively on the diffusion RL-generated data achieves an average success rate of 81.9%, which outperforms the model trained on human data by +5.3% and that on Gaussian RL-generated data by +12.6%. The results highlight our diffusion RL as an effective alternative for generating abundant, high-quality, and low-variance demonstrations for VLA models.