Real-Time Reinforcement Learning for Dynamic Tasks with a Parallel Soft Robot
作者: James Avtges, Jake Ketchum, Millicent Schlafly, Helena Young, Taekyoung Kim, Allison Pinosky, Ryan L. Truby, Todd D. Murphey
分类: cs.RO
发布日期: 2025-09-23
备注: Published at IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2025
💡 一句话要点
提出基于最大扩散强化学习的软体机器人实时动态平衡控制方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 软体机器人 强化学习 动态平衡 课程学习 最大扩散强化学习
📋 核心要点
- 软体机器人控制面临非线性、滞后等问题,传统方法难以充分利用其构型空间。
- 提出基于课程学习的最大扩散强化学习方法,实现软体机器人的实时动态平衡控制。
- 实验表明,该方法可在单次部署中快速学习,即使部分驱动器失效也能保持平衡。
📝 摘要(中文)
闭环控制仍然是软体机器人领域的一个开放性挑战。软体驱动器在动态载荷条件下的非线性响应限制了软体机器人控制中解析模型的使用。传统方法通常为了避免非线性、滞后、大变形和驱动器损坏的风险,而未能充分利用软体机器人的构型空间。此外,诸如强化学习(RL)等基于 episodic 数据的控制方法通常受到样本效率和初始化不一致性的限制。本文展示了使用强化学习,在实时单次硬件部署中,可靠地学习动态平衡任务的控制策略。我们使用基于电动剪切膨胀(HSA)结构的并行3D打印软体驱动器构建了一个可变形的Stewart平台。通过引入基于已知平衡邻域扩展的课程学习方法,我们实现了在任意坐标下的可靠单次部署平衡。除了对基于模型和无模型方法的性能进行基准测试外,我们还证明了在单次部署中,最大扩散强化学习能够在部分驱动器失效后(通过屈曲和使用断线钳破坏驱动器)学习动态平衡。训练无需先验数据,最快可在15分钟内完成,性能与完整平台几乎相同。硬件上的单次学习有助于软体机器人系统在现实世界中可靠地学习,并将使更多样化和有能力的软体机器人成为可能。
🔬 方法详解
问题定义:论文旨在解决软体机器人在动态环境下的实时平衡控制问题。现有方法,如基于解析模型的方法,难以应对软体驱动器的非线性特性和动态载荷变化;传统的强化学习方法则面临样本效率低和初始化敏感的问题,难以在真实硬件上快速部署。
核心思路:论文的核心思路是利用最大扩散强化学习(Maximum Diffusion RL)算法,结合课程学习策略,使软体机器人能够在单次硬件部署中快速学习动态平衡控制策略。最大扩散强化学习能够探索更广泛的状态空间,提高样本效率;课程学习则通过逐步增加任务难度,引导智能体学习。
技术框架:整体框架包括一个可变形的Stewart平台,该平台由3D打印的软体驱动器构成。控制系统使用最大扩散强化学习算法,以平台的状态(位置、姿态等)作为输入,输出驱动器的控制信号。课程学习策略则根据平台的平衡状态,逐步扩展训练数据的范围。
关键创新:论文的关键创新在于将最大扩散强化学习与课程学习相结合,实现了软体机器人在真实硬件上的快速、鲁棒的动态平衡控制。与传统的强化学习方法相比,该方法具有更高的样本效率和更好的泛化能力,能够在部分驱动器失效的情况下仍然保持平衡。
关键设计:课程学习策略从一个已知的平衡点开始,逐步扩展训练数据的范围,避免了智能体在训练初期遇到过于困难的任务。最大扩散强化学习算法使用扩散模型来学习状态转移概率,并通过最大化状态的熵来鼓励探索。具体的参数设置和网络结构在论文中进行了详细描述(未知)。
🖼️ 关键图片


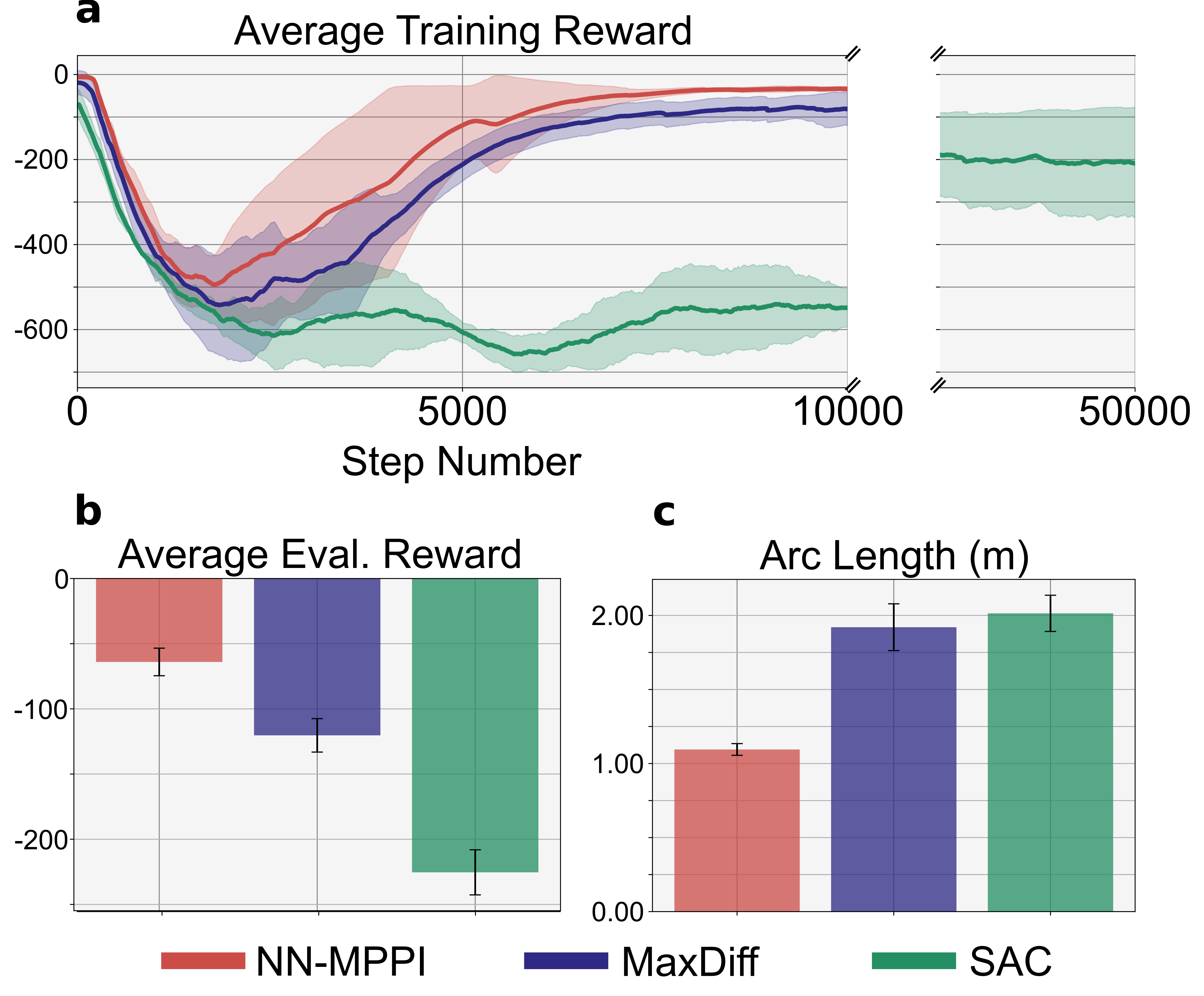
📊 实验亮点
实验结果表明,该方法能够在15分钟内完成训练,并且在部分驱动器失效的情况下,仍然能够保持与完整平台几乎相同的平衡性能。与传统的基于模型的方法和无模型的方法相比,该方法具有更高的鲁棒性和适应性。论文通过实际硬件实验验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要动态平衡控制的软体机器人系统,例如:医疗康复机器人、柔性抓取机器人、以及在复杂地形中移动的机器人。该方法能够提高软体机器人在实际应用中的可靠性和适应性,使其能够更好地完成各种任务。
📄 摘要(原文)
Closed-loop control remains an open challenge in soft robotics. The nonlinear responses of soft actuators under dynamic loading conditions limit the use of analytic models for soft robot control. Traditional methods of controlling soft robots underutilize their configuration spaces to avoid nonlinearity, hysteresis, large deformations, and the risk of actuator damage. Furthermore, episodic data-driven control approaches such as reinforcement learning (RL) are traditionally limited by sample efficiency and inconsistency across initializations. In this work, we demonstrate RL for reliably learning control policies for dynamic balancing tasks in real-time single-shot hardware deployments. We use a deformable Stewart platform constructed using parallel, 3D-printed soft actuators based on motorized handed shearing auxetic (HSA) structures. By introducing a curriculum learning approach based on expanding neighborhoods of a known equilibrium, we achieve reliable single-deployment balancing at arbitrary coordinates. In addition to benchmarking the performance of model-based and model-free methods, we demonstrate that in a single deployment, Maximum Diffusion RL is capable of learning dynamic balancing after half of the actuators are effectively disabled, by inducing buckling and by breaking actuators with bolt cutters. Training occurs with no prior data, in as fast as 15 minutes, with performance nearly identical to the fully-intact platform. Single-shot learning on hardware facilitates soft robotic systems reliably learning in the real world and will enable more diverse and capable soft robots.