Residual Off-Policy RL for Finetuning Behavior Cloning Policies
作者: Lars Ankile, Zhenyu Jiang, Rocky Duan, Guanya Shi, Pieter Abbeel, Anusha Nagabandi
分类: cs.RO, cs.LG
发布日期: 2025-09-23 (更新: 2025-09-25)
备注: Project website: https://residual-offpolicy-rl.github.io
💡 一句话要点
提出残差离线强化学习,微调行为克隆策略,提升高自由度机器人操作能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 残差学习 强化学习 行为克隆 机器人操作 离线强化学习
📋 核心要点
- 现有行为克隆方法依赖高质量人工数据,且数据收集成本高昂,离线数据利用存在收益递减问题。
- 该论文提出一种残差学习框架,利用行为克隆策略作为基础,通过离线强化学习学习残差校正。
- 实验表明,该方法仅需稀疏奖励信号,即可有效提升高自由度机器人在模拟和真实环境中的操作策略。
📝 摘要(中文)
行为克隆(BC)的最新进展已经实现了令人印象深刻的视觉运动控制策略。然而,这些方法受到人类演示数据质量、数据收集所需的人工以及离线数据收益递减的限制。相比之下,强化学习(RL)通过与环境的自主交互来训练智能体,并在各个领域取得了显著成功。然而,由于样本效率低、安全问题以及对于长时程任务从稀疏奖励中学习的难度,直接在真实机器人上训练RL策略仍然具有挑战性,特别是对于高自由度(DoF)系统。我们提出了一种通过残差学习框架结合BC和RL优势的方法。我们的方法利用BC策略作为黑盒基础,并通过样本高效的离线RL学习轻量级的每步残差校正。我们证明了我们的方法只需要稀疏的二元奖励信号,并且可以有效地改进模拟和真实世界中高自由度系统的操作策略。特别是,据我们所知,我们展示了第一个在具有灵巧手的人形机器人上成功进行真实世界RL训练的案例。我们的结果表明在各种基于视觉的任务中达到了最先进的性能,为在真实世界中部署RL提供了一条可行的途径。
🔬 方法详解
问题定义:论文旨在解决直接在真实机器人上训练强化学习策略的挑战,特别是对于高自由度系统,由于样本效率低、安全问题以及从稀疏奖励中学习的困难,导致训练难以进行。现有行为克隆方法虽然可以快速学习,但受限于人类演示数据的质量和数量,难以超越演示数据的性能。
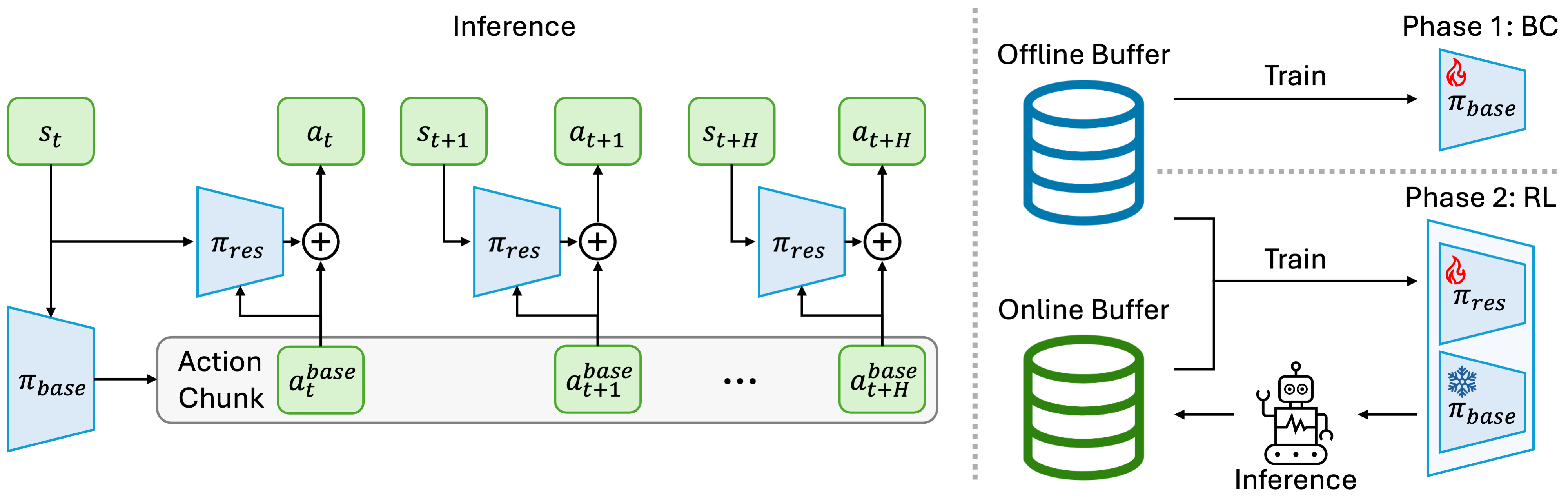
核心思路:论文的核心思路是将行为克隆策略作为预训练的基础策略,然后通过离线强化学习来学习一个残差策略,该残差策略对行为克隆策略的动作进行微调和校正。这种方法结合了行为克隆的快速学习能力和强化学习的自主探索能力,从而能够在真实机器人上实现高效的强化学习。
技术框架:整体框架包含两个主要部分:首先,使用行为克隆从人类演示数据中训练一个基础策略。然后,使用离线强化学习算法,例如Behavior Cloning with Advantage Weighted Regression (BC-AWWR)或Conservative Q-Learning (CQL),来学习一个残差策略。该残差策略的输出与基础策略的输出相加,得到最终的动作。整个训练过程只需要稀疏的二元奖励信号。
关键创新:该方法最重要的创新点在于将残差学习的思想引入到强化学习中,并结合行为克隆策略作为基础。这种方法能够有效地利用已有的演示数据,并在此基础上进行自主学习,从而提高样本效率和最终性能。此外,该方法还能够在真实机器人上进行训练,克服了传统强化学习方法在真实环境中训练的困难。
关键设计:关键设计包括:1) 使用行为克隆策略作为基础策略,提供一个良好的初始化;2) 使用离线强化学习算法来学习残差策略,避免了在线探索的风险;3) 使用稀疏的二元奖励信号,降低了奖励设计的难度;4) 针对高自由度机器人,设计合适的动作空间和状态空间表示。
🖼️ 关键图片

📊 实验亮点
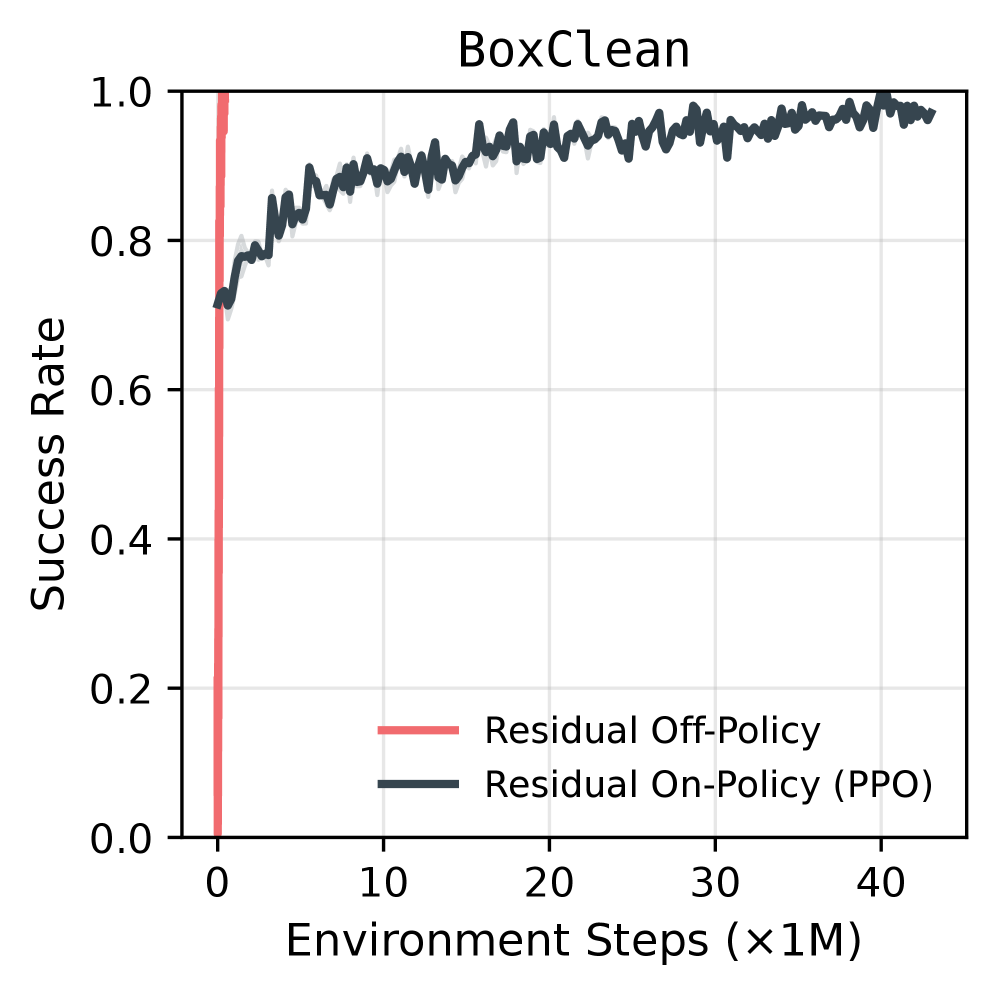
该论文在真实世界的人形机器人上成功进行了强化学习训练,这是之前的研究很少实现的。实验结果表明,该方法在各种基于视觉的任务中达到了最先进的性能,并且只需要稀疏的二元奖励信号。例如,在操作任务中,该方法能够显著提高机器人的成功率,并减少所需的训练时间。
🎯 应用场景
该研究成果可广泛应用于机器人操作领域,例如工业自动化、家庭服务机器人、医疗机器人等。通过结合行为克隆和强化学习,可以使机器人能够更高效、更安全地完成各种复杂任务,并降低对人工干预的依赖。该方法在人形机器人上的成功应用,也为未来开发更智能、更灵活的人形机器人奠定了基础。
📄 摘要(原文)
Recent advances in behavior cloning (BC) have enabled impressive visuomotor control policies. However, these approaches are limited by the quality of human demonstrations, the manual effort required for data collection, and the diminishing returns from offline data. In comparison, reinforcement learning (RL) trains an agent through autonomous interaction with the environment and has shown remarkable success in various domains. Still, training RL policies directly on real-world robots remains challenging due to sample inefficiency, safety concerns, and the difficulty of learning from sparse rewards for long-horizon tasks, especially for high-degree-of-freedom (DoF) systems. We present a recipe that combines the benefits of BC and RL through a residual learning framework. Our approach leverages BC policies as black-box bases and learns lightweight per-step residual corrections via sample-efficient off-policy RL. We demonstrate that our method requires only sparse binary reward signals and can effectively improve manipulation policies on high-degree-of-freedom (DoF) systems in both simulation and the real world. In particular, we demonstrate, to the best of our knowledge, the first successful real-world RL training on a humanoid robot with dexterous hands. Our results demonstrate state-of-the-art performance in various vision-based tasks, pointing towards a practical pathway for deploying RL in the real world.