FUNCanon: Learning Pose-Aware Action Primitives via Functional Object Canonicalization for Generalizable Robotic Manipulation
作者: Hongli Xu, Lei Zhang, Xiaoyue Hu, Boyang Zhong, Kaixin Bai, Zoltán-Csaba Márton, Zhenshan Bing, Zhaopeng Chen, Alois Christian Knoll, Jianwei Zhang
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-09-23
备注: project website: https://sites.google.com/view/funcanon, 11 pages
💡 一句话要点
FUNCanon:通过功能对象规范化学习姿态感知动作原语,实现通用机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 机器人操作 模仿学习 动作原语 功能对象规范化 扩散模型
📋 核心要点
- 端到端演示学习的通用机器人技能通常导致任务特定的策略,难以泛化到训练分布之外,这是核心问题。
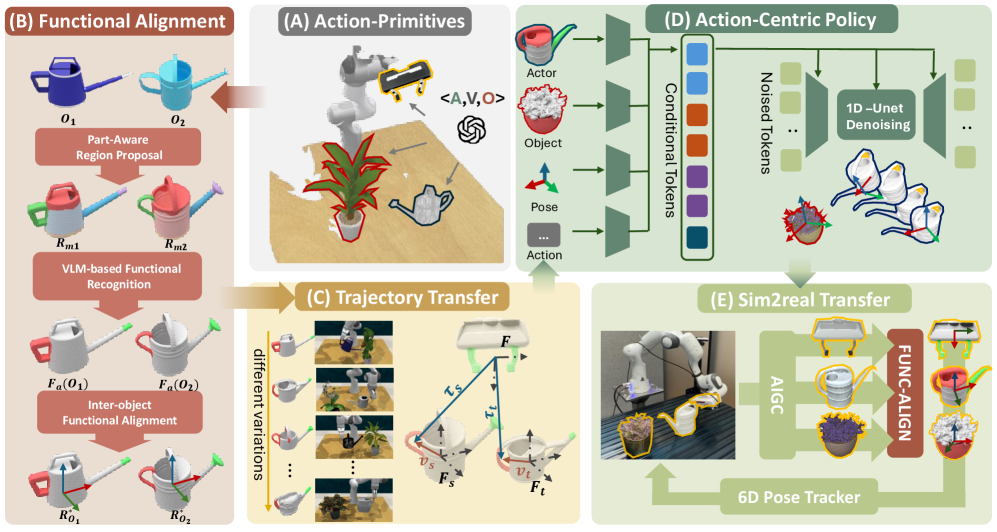
- FunCanon通过功能对象规范化,将长时程任务分解为动作块,并利用扩散策略学习姿态感知的动作原语,实现动作的组合和重用。
- 实验表明,FunCanon在模拟和真实环境中均表现出良好的类别泛化、跨任务行为重用以及sim2real迁移能力。
📝 摘要(中文)
本文提出了一种名为FunCanon的框架,旨在将长时程操作任务分解为一系列动作块,每个动作块由执行者、动词和对象定义。这种分解方式将策略学习聚焦于动作本身,而非孤立的任务,从而实现组合性和重用性。为了使策略具备姿态感知和类别泛化能力,我们执行功能对象规范化,利用大型视觉语言模型提供的可供性线索,将对象映射到共享的功能框架中,从而实现功能对齐和自动操作轨迹迁移。基于对齐数据训练的以对象为中心和以动作为中心的扩散策略FuncDiffuser,能够自然地尊重对象的可供性和姿态,简化学习并提高泛化能力。在模拟和真实世界基准测试上的实验表明,该方法具有类别级别的泛化能力、跨任务行为重用能力和鲁棒的sim2real部署能力,证明了功能规范化为复杂操作领域中的可扩展模仿学习提供了强大的归纳偏置。
🔬 方法详解
问题定义:现有端到端模仿学习方法在机器人操作任务中,通常学习到任务特定的策略,难以泛化到新的对象类别、姿态或任务场景。这些方法缺乏对对象功能和动作之间关系的显式建模,导致策略的泛化能力受限。
核心思路:本文的核心思路是将长时程操作任务分解为更小的、可重用的动作原语,并通过功能对象规范化,将不同对象映射到统一的功能空间中。这样,策略学习可以聚焦于动作本身,而不是特定的对象或任务,从而提高泛化能力。
技术框架:FunCanon框架包含以下几个主要模块:1) 动作块分解:将长时程任务分解为由执行者、动词和对象定义的动作块。2) 功能对象规范化:利用视觉语言模型提取对象的可供性信息,并将对象映射到共享的功能框架中。3) FuncDiffuser策略学习:基于对齐的数据训练以对象为中心和以动作为中心的扩散策略,学习姿态感知的动作原语。
关键创新:该方法最重要的创新点在于功能对象规范化,它利用视觉语言模型提供的可供性信息,将不同对象映射到统一的功能空间中,从而实现功能对齐和自动操作轨迹迁移。这使得策略能够更好地理解对象的功能和姿态,从而提高泛化能力。
关键设计:FuncDiffuser策略采用扩散模型,能够生成连续的动作轨迹。损失函数包括动作损失、状态损失和奖励损失,用于约束策略的学习。网络结构包括编码器和解码器,编码器用于提取对象和状态的特征,解码器用于生成动作轨迹。具体参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FunCanon在模拟和真实世界基准测试中均取得了显著的性能提升。例如,在类别级别的泛化测试中,FunCanon能够成功操作训练集中未见过的对象类别。此外,FunCanon还表现出良好的跨任务行为重用能力,能够将学习到的动作原语应用于新的任务场景。Sim2real实验表明,FunCanon具有较强的鲁棒性,能够成功地将模拟环境中学习到的策略迁移到真实机器人上。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如家庭服务机器人、工业自动化机器人和医疗机器人等。通过学习通用的动作原语,机器人可以更好地适应不同的环境和任务,提高工作效率和智能化水平。未来,该方法还可以扩展到更复杂的任务和场景,例如多机器人协作和人机协作。
📄 摘要(原文)
General-purpose robotic skills from end-to-end demonstrations often leads to task-specific policies that fail to generalize beyond the training distribution. Therefore, we introduce FunCanon, a framework that converts long-horizon manipulation tasks into sequences of action chunks, each defined by an actor, verb, and object. These chunks focus policy learning on the actions themselves, rather than isolated tasks, enabling compositionality and reuse. To make policies pose-aware and category-general, we perform functional object canonicalization for functional alignment and automatic manipulation trajectory transfer, mapping objects into shared functional frames using affordance cues from large vision language models. An object centric and action centric diffusion policy FuncDiffuser trained on this aligned data naturally respects object affordances and poses, simplifying learning and improving generalization ability. Experiments on simulated and real-world benchmarks demonstrate category-level generalization, cross-task behavior reuse, and robust sim2real deployment, showing that functional canonicalization provides a strong inductive bias for scalable imitation learning in complex manipulation domains. Details of the demo and supplemental material are available on our project website https://sites.google.com/view/funcanon.