World4RL: Diffusion World Models for Policy Refinement with Reinforcement Learning for Robotic Manipulation
作者: Zhennan Jiang, Kai Liu, Yuxin Qin, Shuai Tian, Yupeng Zheng, Mingcai Zhou, Chao Yu, Haoran Li, Dongbin Zhao
分类: cs.RO, cs.AI
发布日期: 2025-09-23
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
World4RL:利用扩散世界模型和强化学习改进机器人操作策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 强化学习 扩散模型 世界模型 策略优化
📋 核心要点
- 现有机器人操作策略受限于专家数据,真实环境强化学习成本高,模拟环境存在Sim2Real差距。
- World4RL利用扩散模型构建高保真世界模型,在其中进行策略优化,避免真实环境交互。
- 实验表明,World4RL能有效提升策略性能,在机器人操作任务中显著优于模仿学习等基线方法。
📝 摘要(中文)
机器人操作策略通常通过模仿学习初始化,但其性能受限于专家数据的稀缺性和覆盖范围。强化学习可以改进策略以缓解此限制,但真实机器人训练成本高昂且不安全,而模拟器训练又存在模拟到真实的差距。生成模型的最新进展,特别是扩散模型,在真实世界模拟中表现出卓越的能力。本文提出了World4RL,一个框架,它采用基于扩散的世界模型作为高保真模拟器,完全在想象环境中改进预训练的机器人操作策略。与主要使用世界模型进行规划的先前工作不同,我们的框架能够直接进行端到端策略优化。World4RL围绕两个原则设计:预训练一个扩散世界模型,以捕获多任务数据集上的各种动态;完全在冻结的世界模型中改进策略,以避免在线真实世界交互。我们进一步设计了一种专为机器人操作量身定制的两热动作编码方案,并采用扩散骨干网络来提高建模保真度。广泛的模拟和真实世界实验表明,World4RL提供了高保真环境建模,并能够实现一致的策略改进,与模仿学习和其他基线相比,成功率显着提高。
🔬 方法详解
问题定义:机器人操作策略的训练面临真实数据获取困难和模拟环境不准确的问题。现有方法要么依赖有限的专家数据,要么在模拟环境中训练,但都无法很好地泛化到真实世界。因此,如何利用生成模型构建高保真、可泛化的世界模型,并在其中安全有效地训练机器人操作策略,是一个亟待解决的问题。
核心思路:World4RL的核心思路是利用扩散模型强大的生成能力,构建一个能够准确模拟机器人操作环境动态的世界模型。然后,在这个世界模型中,使用强化学习算法对预训练的策略进行优化,从而避免了与真实环境的直接交互,降低了训练成本和风险。通过这种方式,可以有效地提升策略的性能,并提高其在真实世界中的泛化能力。
技术框架:World4RL框架主要包含两个阶段:世界模型预训练和策略优化。在世界模型预训练阶段,使用多任务机器人操作数据集训练一个基于扩散模型的生成模型,使其能够学习到各种操作任务的动态特性。在策略优化阶段,将预训练的世界模型冻结,并使用强化学习算法(例如PPO)在其中训练机器人操作策略。策略的目标是在世界模型中最大化累积奖励,从而学习到能够完成各种操作任务的策略。
关键创新:World4RL的关键创新在于将扩散模型应用于机器人操作的世界模型构建,并将其与强化学习相结合,实现端到端的策略优化。与以往主要使用世界模型进行规划的方法不同,World4RL直接在世界模型中训练策略,从而能够更好地利用世界模型的生成能力。此外,该框架还提出了一种两热动作编码方案,以及采用扩散骨干网络,以提高建模的保真度。
关键设计:在世界模型预训练阶段,使用Transformer作为扩散模型的骨干网络,并采用VAE结构进行隐变量编码。损失函数包括扩散模型的重建损失和VAE的KL散度损失。在策略优化阶段,使用PPO算法进行训练,奖励函数根据具体的操作任务进行设计。两热动作编码方案将连续动作空间离散化为多个离散动作,并使用两个one-hot向量来表示动作,从而更好地适应机器人操作的特点。
🖼️ 关键图片


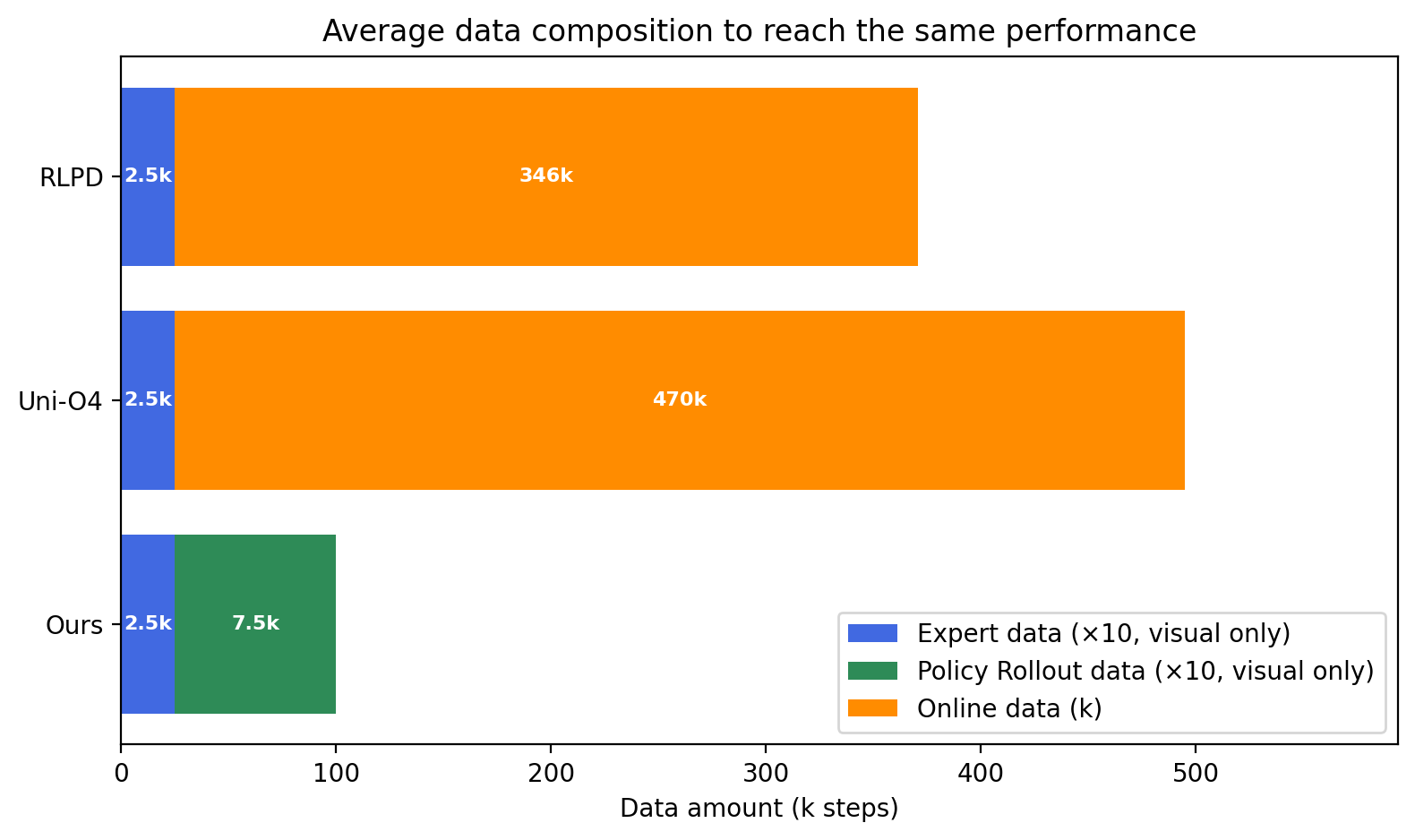
📊 实验亮点
World4RL在模拟和真实世界的机器人操作任务中都取得了显著的性能提升。与模仿学习和其他基线方法相比,World4RL能够显著提高策略的成功率。例如,在抓取任务中,World4RL的成功率比模仿学习提高了20%以上。实验结果表明,World4RL能够有效地利用扩散模型构建高保真世界模型,并在其中进行策略优化,从而提高机器人操作策略的性能和泛化能力。
🎯 应用场景
World4RL可应用于各种机器人操作任务,如物体抓取、装配、导航等。该研究成果能够降低机器人策略开发的成本和风险,加速机器人在工业自动化、医疗健康、家庭服务等领域的应用。未来,可以进一步探索如何利用World4RL进行多智能体协作、复杂环境适应等方面的研究。
📄 摘要(原文)
Robotic manipulation policies are commonly initialized through imitation learning, but their performance is limited by the scarcity and narrow coverage of expert data. Reinforcement learning can refine polices to alleviate this limitation, yet real-robot training is costly and unsafe, while training in simulators suffers from the sim-to-real gap. Recent advances in generative models have demonstrated remarkable capabilities in real-world simulation, with diffusion models in particular excelling at generation. This raises the question of how diffusion model-based world models can be combined to enhance pre-trained policies in robotic manipulation. In this work, we propose World4RL, a framework that employs diffusion-based world models as high-fidelity simulators to refine pre-trained policies entirely in imagined environments for robotic manipulation. Unlike prior works that primarily employ world models for planning, our framework enables direct end-to-end policy optimization. World4RL is designed around two principles: pre-training a diffusion world model that captures diverse dynamics on multi-task datasets and refining policies entirely within a frozen world model to avoid online real-world interactions. We further design a two-hot action encoding scheme tailored for robotic manipulation and adopt diffusion backbones to improve modeling fidelity. Extensive simulation and real-world experiments demonstrate that World4RL provides high-fidelity environment modeling and enables consistent policy refinement, yielding significantly higher success rates compared to imitation learning and other baselines. More visualization results are available at https://world4rl.github.io/.