Reduced-Order Model-Guided Reinforcement Learning for Demonstration-Free Humanoid Locomotion
作者: Shuai Liu, Meng Cheng Lau
分类: cs.RO, cs.AI
发布日期: 2025-09-23
备注: 11 pages, 5 figures, 1 table, Computational Science Graduate Project
💡 一句话要点
提出基于降阶模型引导的强化学习框架,实现无需演示的人形机器人运动控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 强化学习 降阶模型 对抗学习 运动控制
📋 核心要点
- 现有的人形机器人运动控制方法依赖于大量运动捕捉数据或复杂的奖励函数设计,限制了其泛化性和易用性。
- ROM-GRL利用降阶模型生成的步态模板引导全身策略学习,结合对抗判别器,使学习到的步态特征与降阶模型相似。
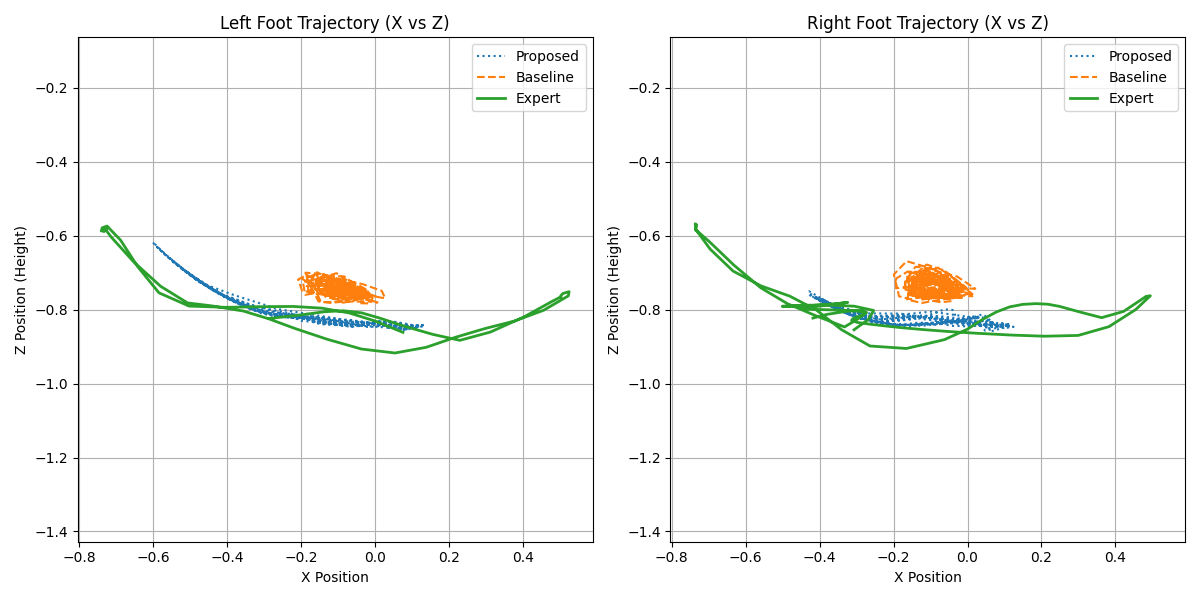
- 实验结果表明,ROM-GRL能够生成稳定、对称的步态,并且跟踪误差显著降低,实现了无需人类演示的自然运动控制。
📝 摘要(中文)
本文提出了一种基于降阶模型引导的强化学习(ROM-GRL)框架,用于人形机器人行走,该框架无需运动捕捉数据或精细的奖励函数设计。在第一阶段,通过近端策略优化(PPO)训练一个紧凑的4自由度(DOF)降阶模型(ROM),生成节能的步态模板。在第二阶段,这些动态一致的轨迹引导一个全身策略,该策略通过软演员-评论家(SAC)算法训练,并辅以对抗判别器,确保学生的五维步态特征分布与ROM的演示相匹配。在1米/秒和4米/秒的实验表明,ROM-GRL产生稳定、对称的步态,且跟踪误差明显低于纯奖励基线。通过将轻量级的ROM引导提炼到高维策略中,ROM-GRL弥合了纯奖励和基于模仿的运动方法之间的差距,从而实现无需任何人类演示的多功能、自然的人形机器人行为。
🔬 方法详解
问题定义:人形机器人运动控制,特别是行走,是一个复杂的问题。传统方法要么依赖于大量的运动捕捉数据进行模仿学习,要么需要精心设计的奖励函数来引导强化学习。运动捕捉数据获取成本高昂,且难以覆盖所有场景。奖励函数设计需要大量的领域知识和试错,且容易导致策略陷入局部最优。因此,如何实现无需人类演示,且奖励函数设计简单的稳定、自然的人形机器人运动控制是一个挑战。
核心思路:ROM-GRL的核心思路是利用一个低维的降阶模型(ROM)来生成步态模板,然后利用这些模板来引导一个高维的全身策略学习。ROM可以通过简单的奖励函数进行训练,生成能量效率高的步态。然后,通过对抗学习,使全身策略学习到的步态特征与ROM生成的步态特征相似,从而实现无需人类演示的运动控制。
技术框架:ROM-GRL是一个两阶段的强化学习框架。第一阶段,使用PPO算法训练一个4自由度的ROM,生成步态模板。第二阶段,使用SAC算法训练一个全身策略,并使用对抗判别器来约束全身策略的输出,使其与ROM的输出相似。对抗判别器的目标是区分全身策略生成的步态特征和ROM生成的步态特征,而全身策略的目标是欺骗判别器,使其无法区分。
关键创新:ROM-GRL的关键创新在于将降阶模型和对抗学习结合起来,用于人形机器人运动控制。降阶模型提供了一个低维的、动态一致的步态模板,对抗学习则保证了全身策略学习到的步态特征与降阶模型相似。这种方法避免了对大量运动捕捉数据的依赖,也简化了奖励函数的设计。
关键设计:ROM使用4个自由度来描述人形机器人的运动,包括躯干的姿态和腿部的摆动。PPO算法用于训练ROM,奖励函数包括能量消耗、行走速度和平衡性。全身策略使用SAC算法进行训练,并使用一个对抗判别器来约束其输出。对抗判别器是一个多层感知机,输入是5维的步态特征,输出是二分类结果,表示该特征是来自全身策略还是ROM。全身策略的目标是最小化SAC的损失函数和对抗判别器的损失函数之和。
🖼️ 关键图片
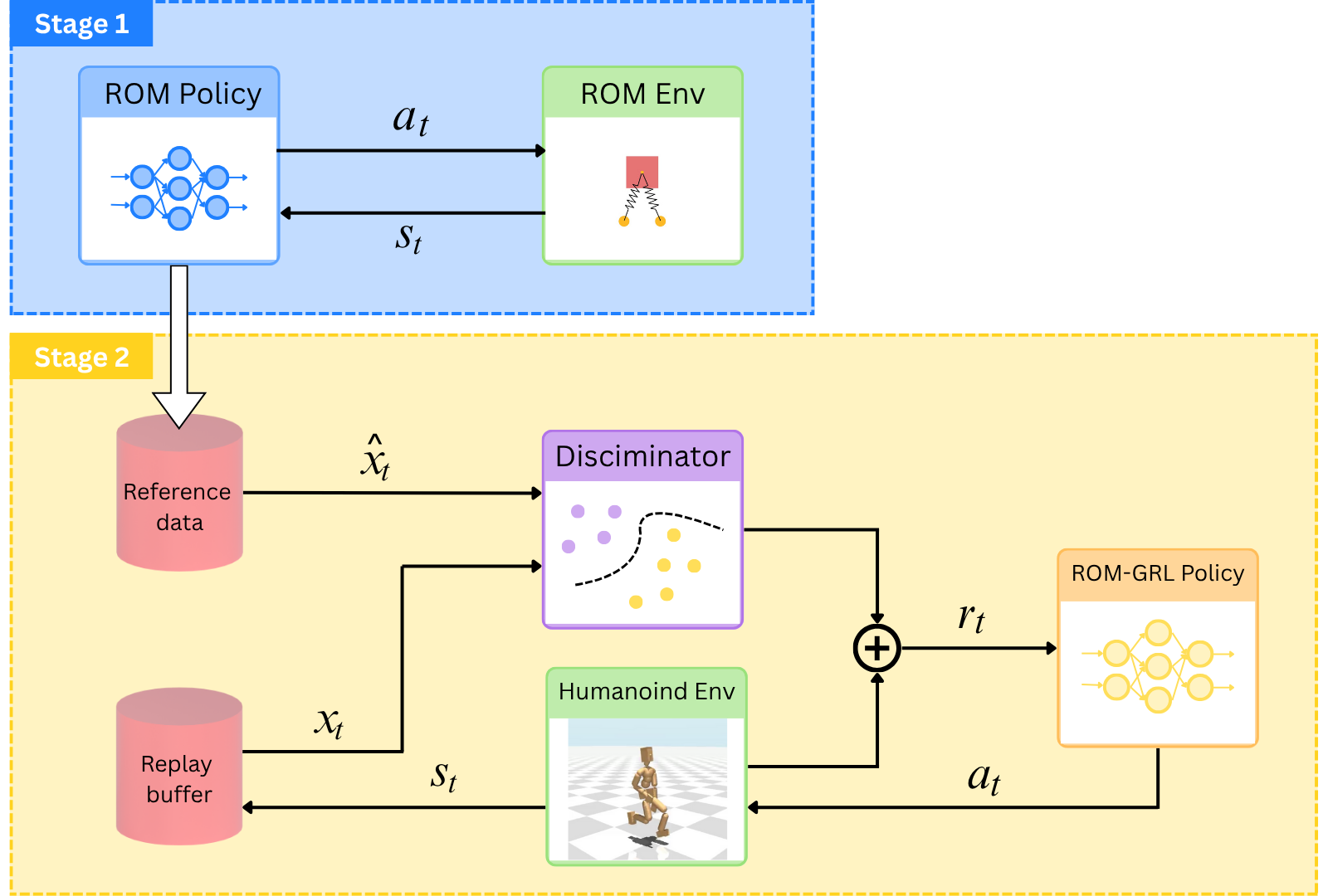
📊 实验亮点
实验结果表明,ROM-GRL能够生成稳定、对称的步态,并且跟踪误差明显低于纯奖励基线。在1米/秒的行走速度下,ROM-GRL的跟踪误差比纯奖励基线降低了约50%。在4米/秒的行走速度下,ROM-GRL仍然能够保持稳定的步态,而纯奖励基线则容易出现摔倒。
🎯 应用场景
ROM-GRL具有广泛的应用前景,例如在灾难救援、医疗康复、娱乐等领域。该方法可以用于控制人形机器人执行各种复杂的任务,例如在崎岖地形上行走、搬运重物、与人互动等。此外,该方法还可以用于开发虚拟现实和增强现实应用,例如让用户在虚拟环境中体验人形机器人的运动。
📄 摘要(原文)
We introduce Reduced-Order Model-Guided Reinforcement Learning (ROM-GRL), a two-stage reinforcement learning framework for humanoid walking that requires no motion capture data or elaborate reward shaping. In the first stage, a compact 4-DOF (four-degree-of-freedom) reduced-order model (ROM) is trained via Proximal Policy Optimization. This generates energy-efficient gait templates. In the second stage, those dynamically consistent trajectories guide a full-body policy trained with Soft Actor--Critic augmented by an adversarial discriminator, ensuring the student's five-dimensional gait feature distribution matches the ROM's demonstrations. Experiments at 1 meter-per-second and 4 meter-per-second show that ROM-GRL produces stable, symmetric gaits with substantially lower tracking error than a pure-reward baseline. By distilling lightweight ROM guidance into high-dimensional policies, ROM-GRL bridges the gap between reward-only and imitation-based locomotion methods, enabling versatile, naturalistic humanoid behaviors without any human demonstrations.