Pure Vision Language Action (VLA) Models: A Comprehensive Survey
作者: Dapeng Zhang, Jing Sun, Chenghui Hu, Xiaoyan Wu, Zhenlong Yuan, Rui Zhou, Fei Shen, Qingguo Zhou
分类: cs.RO, cs.AI
发布日期: 2025-09-23 (更新: 2025-11-10)
💡 一句话要点
VLA模型综述:将视觉语言模型从序列生成器转变为机器人智能体
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人控制 通用机器人 视觉语言模型 深度学习
📋 核心要点
- 现有机器人控制方法泛化性不足,难以适应复杂动态环境。
- VLA模型旨在将VLMs转变为主动智能体,直接进行操作和决策。
- 综述分析了VLA模型的不同范式,并探讨了其挑战与未来方向。
📝 摘要(中文)
视觉语言动作(VLA)模型的出现标志着从传统基于策略的控制到通用机器人技术的范式转变,将视觉语言模型(VLMs)从被动的序列生成器转变为在复杂、动态环境中进行操作和决策的主动智能体。本综述深入研究了先进的VLA方法,旨在提供清晰的分类和对现有研究的系统、全面的回顾。它全面分析了VLA在不同场景中的应用,并将VLA方法分为几种范式:基于自回归、基于扩散、基于强化、混合和专用方法;同时详细检查它们的动机、核心策略和实现。此外,还介绍了基础数据集、基准和模拟平台。在当前VLA格局的基础上,本综述进一步提出了关于关键挑战和未来方向的观点,以推进VLA模型和通用机器人技术的研究。通过综合三百多项最新研究的见解,本综述描绘了这个快速发展领域的轮廓,并强调了将塑造可扩展、通用VLA方法发展的机遇和挑战。
🔬 方法详解
问题定义:现有机器人控制方法依赖于人工设计的策略,泛化能力差,难以适应复杂和动态的环境。VLA模型旨在解决这一问题,通过赋予机器人理解视觉信息和自然语言指令的能力,使其能够自主地进行操作和决策。现有方法的痛点在于缺乏通用性和适应性,需要大量的人工干预和重新训练。
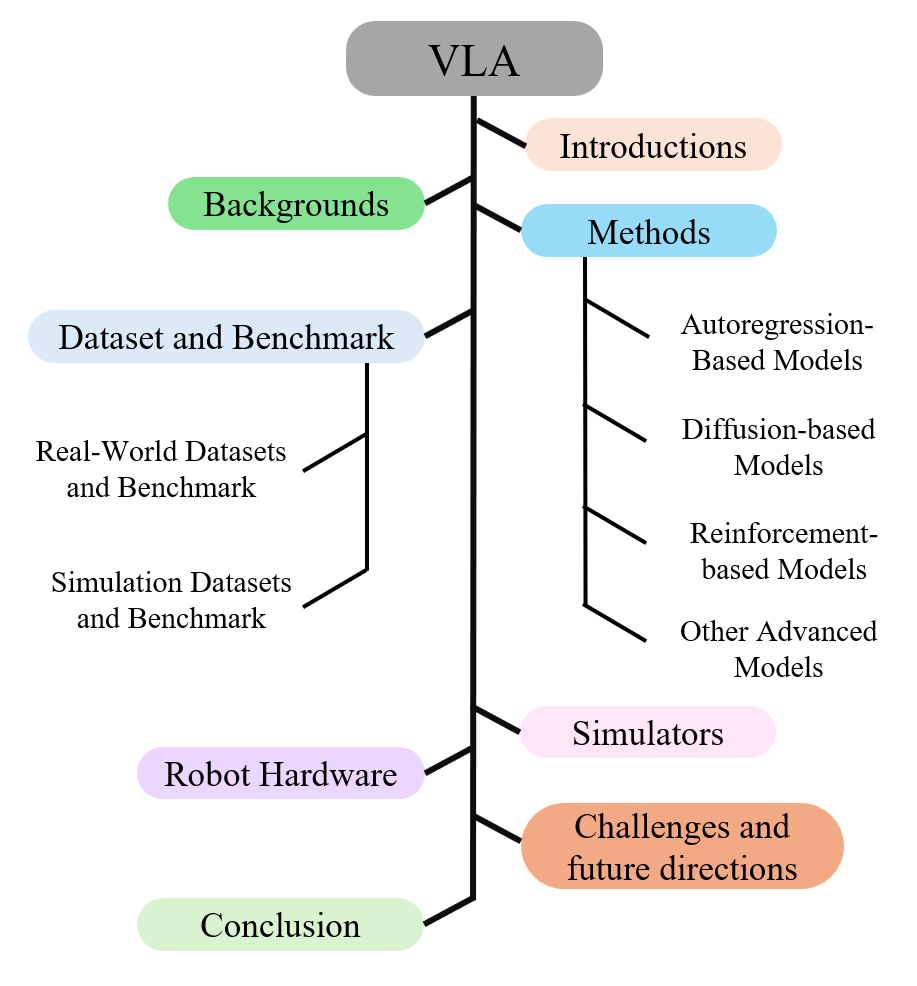
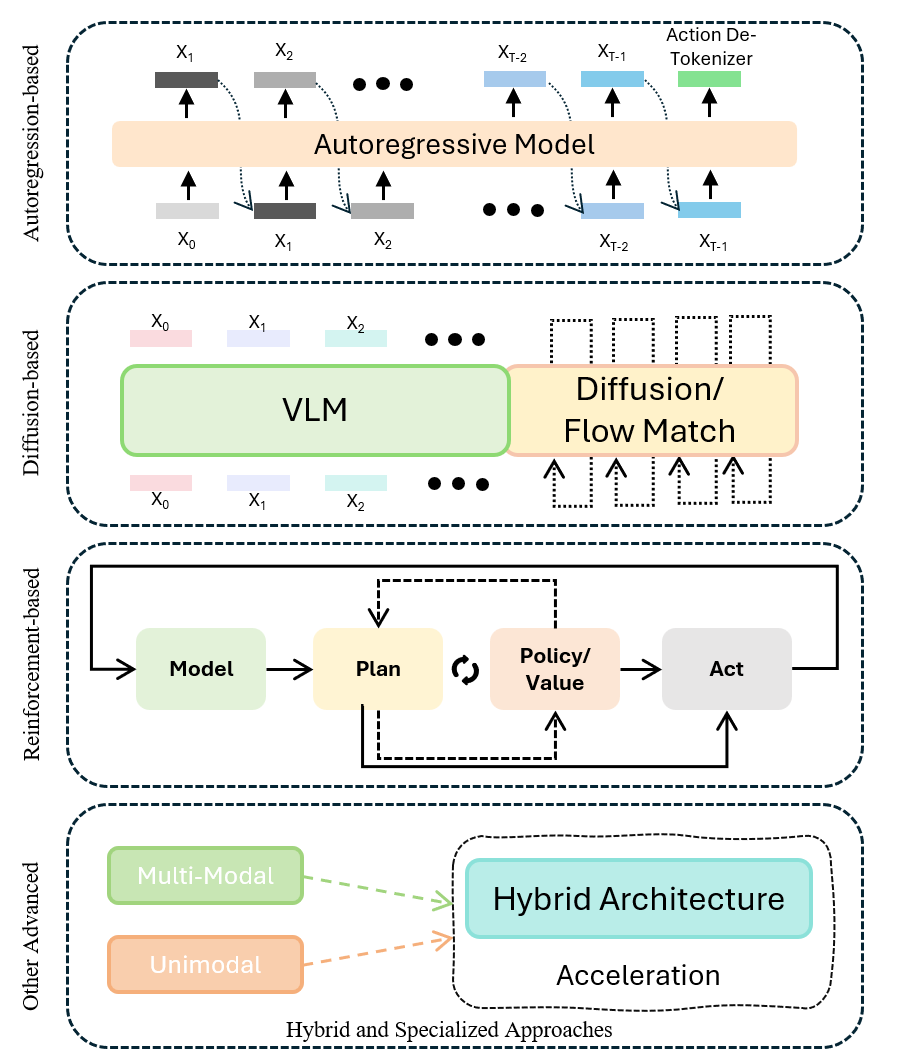
核心思路:论文的核心思路是对现有的VLA模型进行全面的梳理和分类,分析不同方法的优缺点,并探讨未来的发展方向。通过将VLA模型划分为不同的范式(自回归、扩散、强化、混合和专用方法),可以更清晰地理解各种方法的特点和适用场景。这种分类方法有助于研究人员更好地选择和改进VLA模型。
技术框架:该综述没有提出新的技术框架,而是对现有VLA模型的技术框架进行了总结和分析。这些框架通常包括视觉感知模块、语言理解模块和动作生成模块。视觉感知模块负责从图像或视频中提取视觉特征,语言理解模块负责解析自然语言指令,动作生成模块负责生成机器人的控制指令。不同的VLA模型在这些模块的具体实现上有所不同。
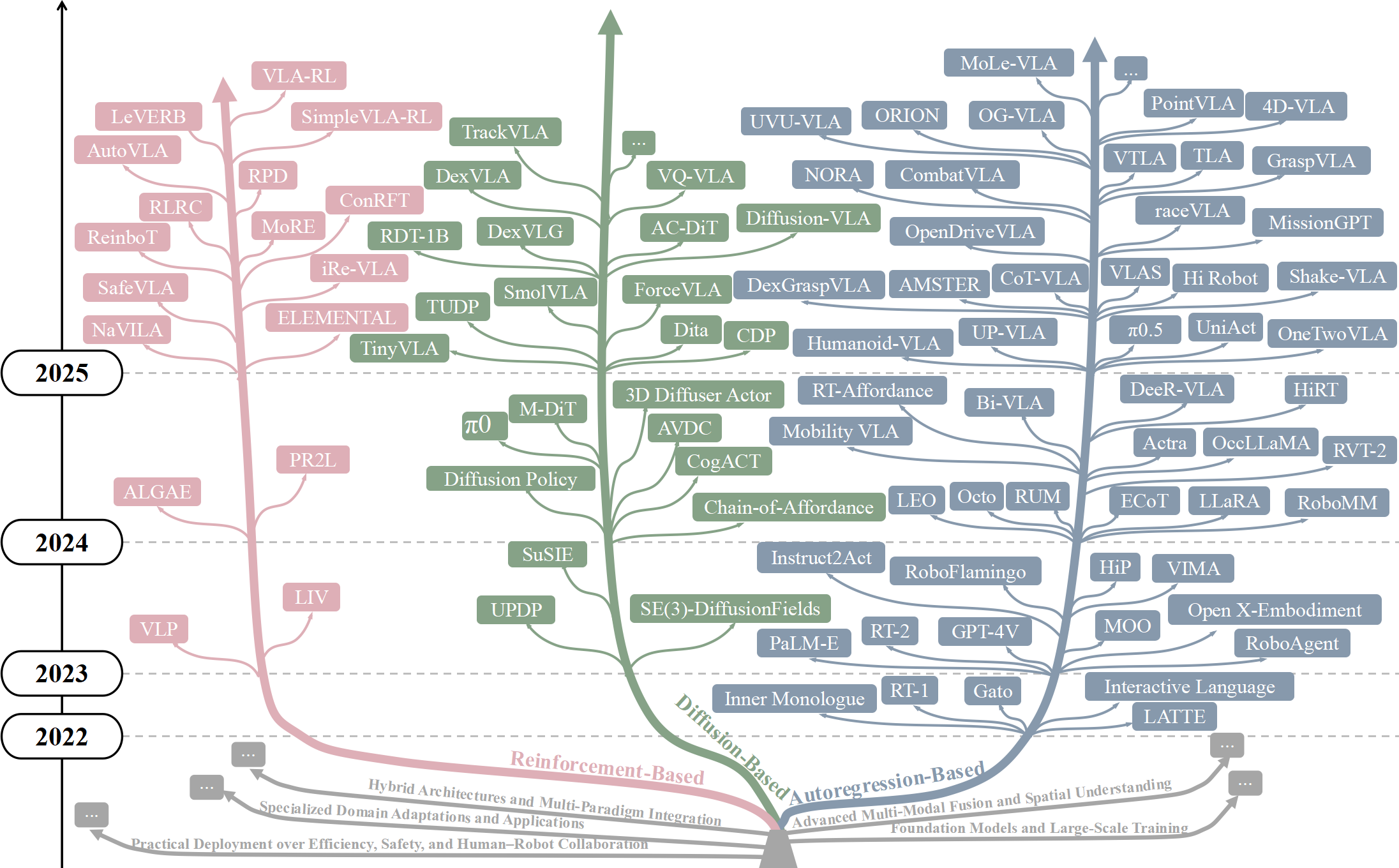
关键创新:该综述的创新之处在于对VLA模型进行了全面的分类和分析,并提出了对未来发展方向的展望。通过对三百多项最新研究的综合,该综述描绘了VLA领域的发展轮廓,并指出了该领域面临的机遇和挑战。这种系统性的分析有助于研究人员更好地理解VLA模型,并推动该领域的发展。
关键设计:该综述没有涉及具体的模型设计细节,而是对现有VLA模型的设计思路进行了总结。不同的VLA模型在参数设置、损失函数和网络结构等方面有所不同。例如,基于自回归的VLA模型通常使用Transformer结构,并采用交叉熵损失函数进行训练。基于强化学习的VLA模型则需要设计合适的奖励函数,以引导机器人学习最优策略。
🖼️ 关键图片
📊 实验亮点
该综述总结了超过三百篇相关论文,对VLA模型进行了全面的分类和分析,涵盖了自回归、扩散、强化学习等多种范式。它还讨论了VLA模型面临的挑战,例如数据效率、泛化能力和安全性,并提出了未来研究方向,为该领域的研究人员提供了宝贵的参考。
🎯 应用场景
VLA模型具有广泛的应用前景,包括家庭服务机器人、工业自动化、医疗辅助机器人等。通过理解人类的指令和感知周围环境,VLA模型可以使机器人更加智能和自主,从而提高生产效率和服务质量。未来,VLA模型有望成为通用机器人技术的核心组成部分,推动机器人技术的发展。
📄 摘要(原文)
The emergence of Vision Language Action (VLA) models marks a paradigm shift from traditional policy-based control to generalized robotics, reframing Vision Language Models (VLMs) from passive sequence generators into active agents for manipulation and decision-making in complex, dynamic environments. This survey delves into advanced VLA methods, aiming to provide a clear taxonomy and a systematic, comprehensive review of existing research. It presents a comprehensive analysis of VLA applications across different scenarios and classifies VLA approaches into several paradigms: autoregression-based, diffusion-based, reinforcement-based, hybrid, and specialized methods; while examining their motivations, core strategies, and implementations in detail. In addition, foundational datasets, benchmarks, and simulation platforms are introduced. Building on the current VLA landscape, the review further proposes perspectives on key challenges and future directions to advance research in VLA models and generalizable robotics. By synthesizing insights from over three hundred recent studies, this survey maps the contours of this rapidly evolving field and highlights the opportunities and challenges that will shape the development of scalable, general-purpose VLA methods.