VGGT-DP: Generalizable Robot Control via Vision Foundation Models
作者: Shijia Ge, Yinxin Zhang, Shuzhao Xie, Weixiang Zhang, Mingcai Zhou, Zhi Wang
分类: cs.RO, cs.AI
发布日期: 2025-09-23
备注: submitted to AAAI 2026
💡 一句话要点
提出VGGT-DP,利用视觉基础模型提升机器人操作技能的泛化性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉模仿学习 机器人控制 视觉基础模型 几何先验 本体感受反馈
📋 核心要点
- 现有视觉模仿学习方法忽略视觉编码器的结构和能力,导致空间理解和泛化能力受限。
- VGGT-DP框架融合了预训练3D感知模型的几何先验和本体感受反馈,提升空间定位和闭环控制。
- 实验表明,VGGT-DP在MetaWorld任务中显著优于现有基线,尤其在精度要求高和长时程场景中。
📝 摘要(中文)
本文提出了一种名为VGGT-DP的视觉运动策略框架,旨在提升机器人操作技能的泛化能力。现有方法主要关注策略设计,忽略了视觉编码器的结构和能力,限制了空间理解和泛化。受生物视觉系统的启发,VGGT-DP集成了预训练的3D感知模型提供的几何先验知识和本体感受反馈,以实现鲁棒控制。该框架采用视觉几何基础Transformer (VGGT) 作为视觉编码器,并引入了一种本体感受引导的视觉学习策略,使感知与内部机器人状态对齐,从而改善空间定位和闭环控制。为了降低推理延迟,设计了一种帧间token复用机制,将多视角token压缩为高效的空间表示。此外,应用随机token剪枝来增强策略的鲁棒性并减少过拟合。在具有挑战性的MetaWorld任务上的实验表明,VGGT-DP显著优于DP和DP3等强大的基线,尤其是在对精度要求高和长时程场景中。
🔬 方法详解
问题定义:现有视觉模仿学习方法在机器人操作技能学习中,主要关注策略设计,而忽略了视觉编码器的结构和能力,导致机器人对环境的空间理解不足,泛化能力较差。尤其是在复杂、长时程的任务中,这种局限性更加明显。
核心思路:借鉴生物视觉系统同时依赖视觉和本体感受信息进行控制的机制,论文的核心思路是将预训练的3D感知模型提供的几何先验知识与机器人的本体感受反馈相结合,从而提升机器人对环境的感知能力和控制精度。通过这种方式,可以使机器人更好地理解自身状态与环境之间的关系,从而实现更鲁棒和泛化的控制。
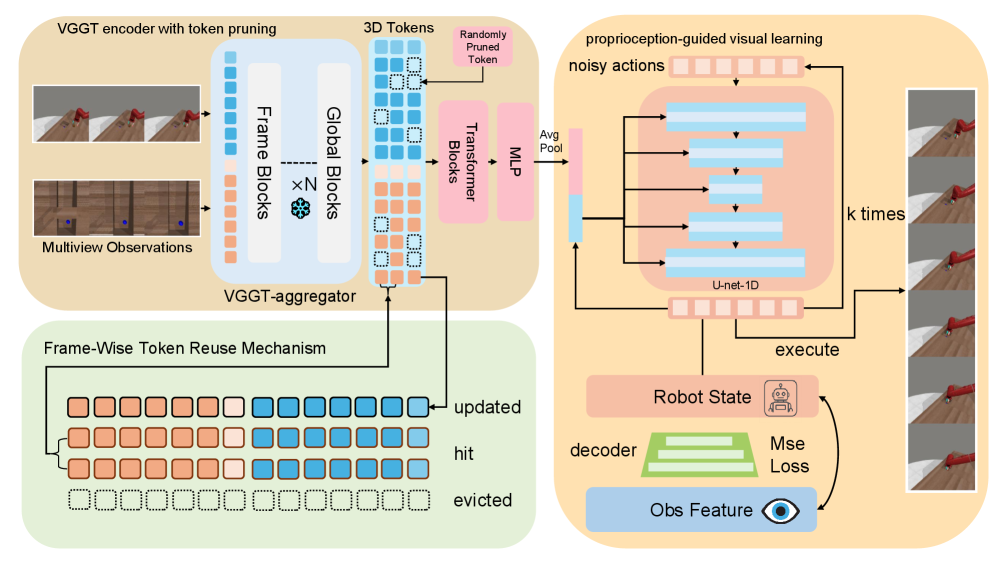
技术框架:VGGT-DP框架主要包含以下几个模块:1) 视觉编码器:采用Visual Geometry Grounded Transformer (VGGT) 作为视觉编码器,提取图像中的几何特征。2) 本体感受引导的视觉学习模块:利用本体感受信息引导视觉特征的学习,使视觉感知与机器人内部状态对齐。3) Token复用机制:为了降低推理延迟,设计了一种帧间token复用机制,将多视角token压缩为高效的空间表示。4) 随机Token剪枝:通过随机剪枝token,增强策略的鲁棒性并减少过拟合。
关键创新:该论文的关键创新在于将预训练的3D感知模型与本体感受反馈相结合,用于机器人控制。与现有方法相比,VGGT-DP不仅利用了视觉信息,还充分利用了机器人的自身状态信息,从而实现了更精确和鲁棒的控制。此外,帧间token复用机制和随机token剪枝也进一步提升了模型的效率和泛化能力。
关键设计:VGGT采用Transformer架构,输入为多视角图像,输出为包含几何信息的视觉特征。本体感受引导的视觉学习模块通过一个损失函数来约束视觉特征与本体感受信息的一致性。Token复用机制通过缓存前一帧的token,并在当前帧中进行选择性更新,从而减少计算量。随机token剪枝则通过随机移除一部分token,来增强模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
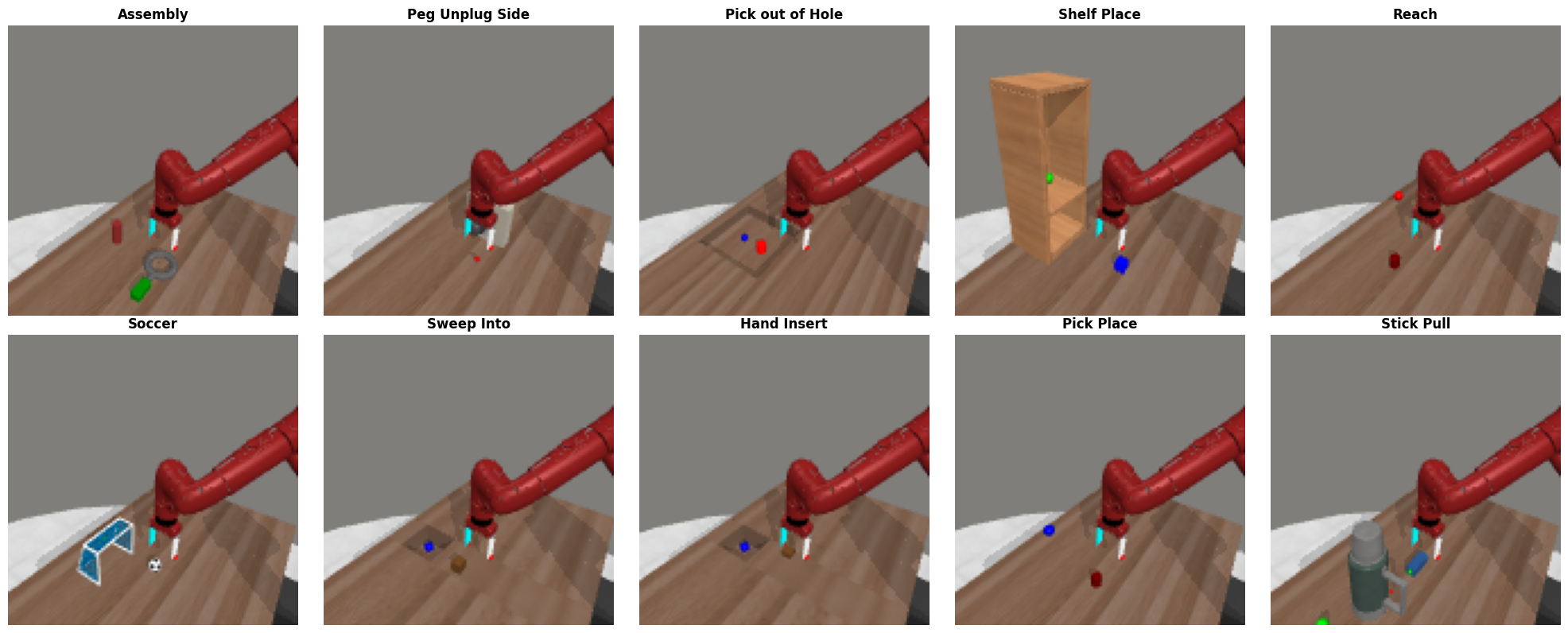
实验结果表明,VGGT-DP在MetaWorld任务中显著优于DP和DP3等基线。例如,在某些精度要求高的任务中,VGGT-DP的成功率比DP提高了20%以上。此外,VGGT-DP在长时程任务中也表现出更强的鲁棒性,证明了其在复杂环境下的泛化能力。
🎯 应用场景
VGGT-DP框架具有广泛的应用前景,可应用于工业自动化、家庭服务机器人、医疗机器人等领域。例如,在工业自动化中,机器人可以利用该框架完成复杂的装配任务;在家庭服务机器人中,可以帮助机器人更好地理解环境并完成各种家务;在医疗机器人中,可以辅助医生进行精准的手术操作。该研究有望推动机器人技术的发展,使其能够更好地服务于人类。
📄 摘要(原文)
Visual imitation learning frameworks allow robots to learn manipulation skills from expert demonstrations. While existing approaches mainly focus on policy design, they often neglect the structure and capacity of visual encoders, limiting spatial understanding and generalization. Inspired by biological vision systems, which rely on both visual and proprioceptive cues for robust control, we propose VGGT-DP, a visuomotor policy framework that integrates geometric priors from a pretrained 3D perception model with proprioceptive feedback. We adopt the Visual Geometry Grounded Transformer (VGGT) as the visual encoder and introduce a proprioception-guided visual learning strategy to align perception with internal robot states, improving spatial grounding and closed-loop control. To reduce inference latency, we design a frame-wise token reuse mechanism that compacts multi-view tokens into an efficient spatial representation. We further apply random token pruning to enhance policy robustness and reduce overfitting. Experiments on challenging MetaWorld tasks show that VGGT-DP significantly outperforms strong baselines such as DP and DP3, particularly in precision-critical and long-horizon scenarios.