MV-UMI: A Scalable Multi-View Interface for Cross-Embodiment Learning
作者: Omar Rayyan, John Abanes, Mahmoud Hafez, Anthony Tzes, Fares Abu-Dakka
分类: cs.RO, cs.AI
发布日期: 2025-09-23
备注: For project website and videos, see https https://mv-umi.github.io
💡 一句话要点
MV-UMI:一种可扩展的多视角界面,用于跨具身学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting)
关键词: 模仿学习 机器人操作 多视角学习 跨具身学习 手持抓取器 领域自适应
📋 核心要点
- 模仿学习依赖高质量数据集,但数据收集成本高且受限于特定机器人形态。
- MV-UMI框架融合第三人称视角,弥补第一人称视角的场景上下文不足。
- 实验表明,MV-UMI在需要场景理解的任务中性能提升约47%。
📝 摘要(中文)
本文提出了一种名为MV-UMI(多视角通用操作界面)的框架,旨在解决模仿学习中因数据集多样性和质量不足,以及数据收集受限于特定机器人形态的问题。MV-UMI集成了第三人称视角和以自我为中心的相机视角,克服了仅依赖第一人称视角腕部相机捕捉场景上下文的局限性。这种集成减轻了人类演示和机器人部署之间的领域差异,同时保留了手持数据收集设备在跨具身方面的优势。实验结果表明,MV-UMI框架在需要广泛场景理解的子任务中,性能提升约47%,验证了该方法在扩展手持抓取器系统可学习的操作任务范围方面的有效性,且不影响此类系统固有的跨具身优势。
🔬 方法详解
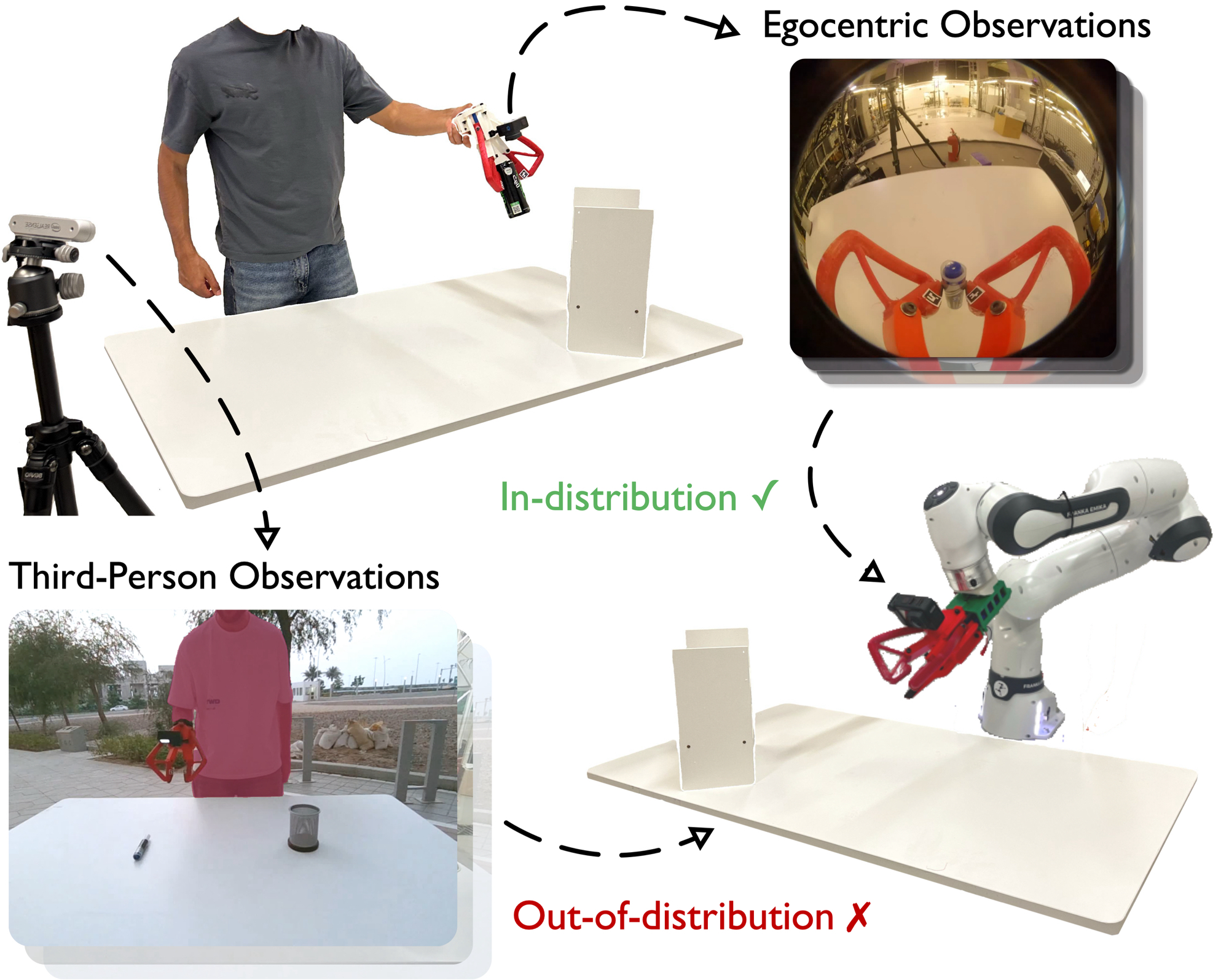
问题定义:现有模仿学习方法依赖于大量高质量的数据集,而这些数据集的收集往往成本高昂,并且通常局限于特定的机器人形态。手持式抓取器虽然提供了一种直观且可扩展的数据收集方式,但它们主要依赖于第一人称视角的腕部相机,这限制了对足够场景上下文的捕捉,导致人类演示和机器人部署之间存在领域差异。
核心思路:MV-UMI的核心思路是通过集成第三人称视角来增强第一人称视角的场景理解能力。通过结合两种视角的信息,可以更全面地捕捉操作任务的上下文,从而减轻人类演示和机器人部署之间的领域差异,并保留手持数据收集设备在跨具身方面的优势。
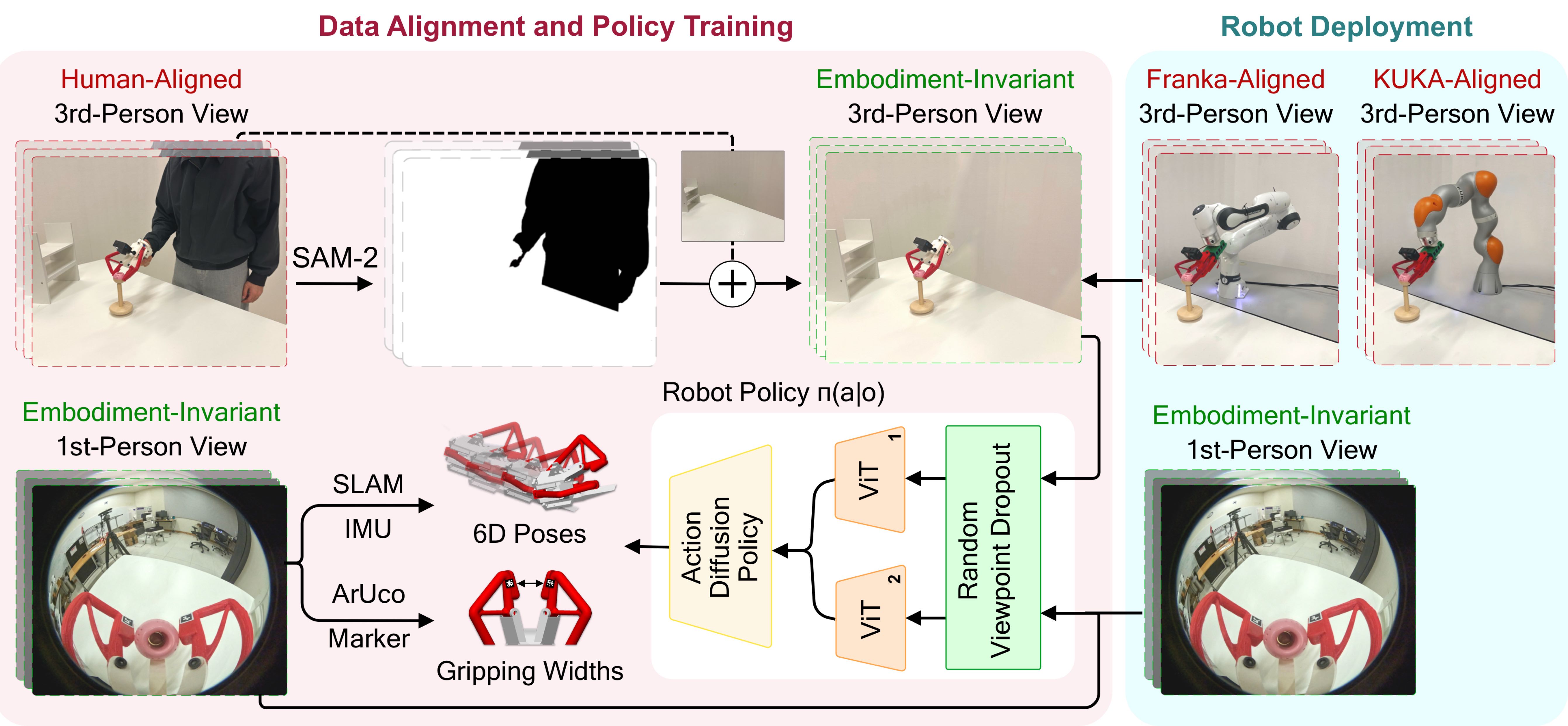
技术框架:MV-UMI框架主要包含两个视角的数据采集模块:第一人称视角的腕部相机和第三人称视角的外部相机。这两个模块的数据被同步并用于训练机器人操作策略。该框架允许用户通过手持抓取器进行演示,同时记录下两个视角的视频数据。这些数据随后被用于训练模仿学习模型,从而使机器人能够学习执行相同的操作。
关键创新:MV-UMI的关键创新在于多视角融合。它通过结合第一人称和第三人称视角的信息,克服了单一视角在场景理解方面的局限性。这种多视角融合的方法能够更全面地捕捉操作任务的上下文,从而提高模仿学习的性能和泛化能力。
关键设计:论文中没有明确给出关键参数设置、损失函数或网络结构的具体细节。但是,可以推断,该框架需要解决的关键设计问题包括:如何有效地融合来自不同视角的视觉信息,如何处理不同视角之间的坐标系转换,以及如何设计合适的损失函数来训练模仿学习模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MV-UMI框架在需要广泛场景理解的子任务中,性能提升约47%。该提升是在三个不同的任务上进行的,并通过消融实验验证了第三人称视角对性能提升的贡献。这些结果表明,MV-UMI框架能够有效地扩展手持抓取器系统可学习的操作任务范围,且不影响此类系统固有的跨具身优势。
🎯 应用场景
MV-UMI框架具有广泛的应用前景,可用于各种机器人操作任务,例如装配、抓取、放置等。该框架可以降低数据收集的成本和难度,并提高机器人操作策略的鲁棒性和泛化能力。未来,该技术可应用于工业自动化、家庭服务机器人等领域,实现更智能、更灵活的机器人操作。
📄 摘要(原文)
Recent advances in imitation learning have shown great promise for developing robust robot manipulation policies from demonstrations. However, this promise is contingent on the availability of diverse, high-quality datasets, which are not only challenging and costly to collect but are often constrained to a specific robot embodiment. Portable handheld grippers have recently emerged as intuitive and scalable alternatives to traditional robotic teleoperation methods for data collection. However, their reliance solely on first-person view wrist-mounted cameras often creates limitations in capturing sufficient scene contexts. In this paper, we present MV-UMI (Multi-View Universal Manipulation Interface), a framework that integrates a third-person perspective with the egocentric camera to overcome this limitation. This integration mitigates domain shifts between human demonstration and robot deployment, preserving the cross-embodiment advantages of handheld data-collection devices. Our experimental results, including an ablation study, demonstrate that our MV-UMI framework improves performance in sub-tasks requiring broad scene understanding by approximately 47% across 3 tasks, confirming the effectiveness of our approach in expanding the range of feasible manipulation tasks that can be learned using handheld gripper systems, without compromising the cross-embodiment advantages inherent to such systems.