3D Flow Diffusion Policy: Visuomotor Policy Learning via Generating Flow in 3D Space
作者: Sangjun Noh, Dongwoo Nam, Kangmin Kim, Geonhyup Lee, Yeonguk Yu, Raeyoung Kang, Kyoobin Lee
分类: cs.RO, eess.SY
发布日期: 2025-09-23
备注: 7 main scripts + 2 reference pages
💡 一句话要点
提出3D FDP,通过生成3D空间中的Flow学习通用机器人操作策略。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 视觉运动策略 3D Flow 扩散模型 强化学习 局部运动 MetaWorld 真实机器人
📋 核心要点
- 现有机器人操作方法难以捕捉局部运动信息,限制了在复杂交互场景中的泛化能力。
- 3D FDP通过预测场景级3D flow,显式地建模局部运动,从而指导动作生成。
- 实验表明,3D FDP在MetaWorld和真实机器人任务中均优于现有方法,尤其擅长接触类任务。
📝 摘要(中文)
在机器人操作中,学习能够泛化到不同物体和交互动态的鲁棒的视觉运动策略仍然是一个核心挑战。现有方法通常依赖于直接的观察到动作的映射,或将感知输入压缩成全局或以物体为中心的特征,这往往忽略了对于精确和富含接触的操作至关重要的局部运动线索。我们提出了3D Flow Diffusion Policy (3D FDP),这是一个新颖的框架,它利用场景级的3D flow作为结构化的中间表示来捕获细粒度的局部运动线索。我们的方法预测采样查询点的时间轨迹,并基于这些交互感知的flow来调节动作生成,这些都在统一的扩散架构中共同实现。这种设计将操作建立在局部动态的基础上,同时使策略能够推理动作的更广泛的场景级后果。在MetaWorld基准测试上的大量实验表明,3D FDP在50个任务中实现了最先进的性能,尤其是在中等和困难设置下表现出色。除了模拟之外,我们在八个真实机器人任务上验证了我们的方法,在富含接触和非抓取场景中,它始终优于先前的基线。这些结果突出了3D flow作为学习通用视觉运动策略的强大结构先验,支持开发更鲁棒和通用的机器人操作。
🔬 方法详解
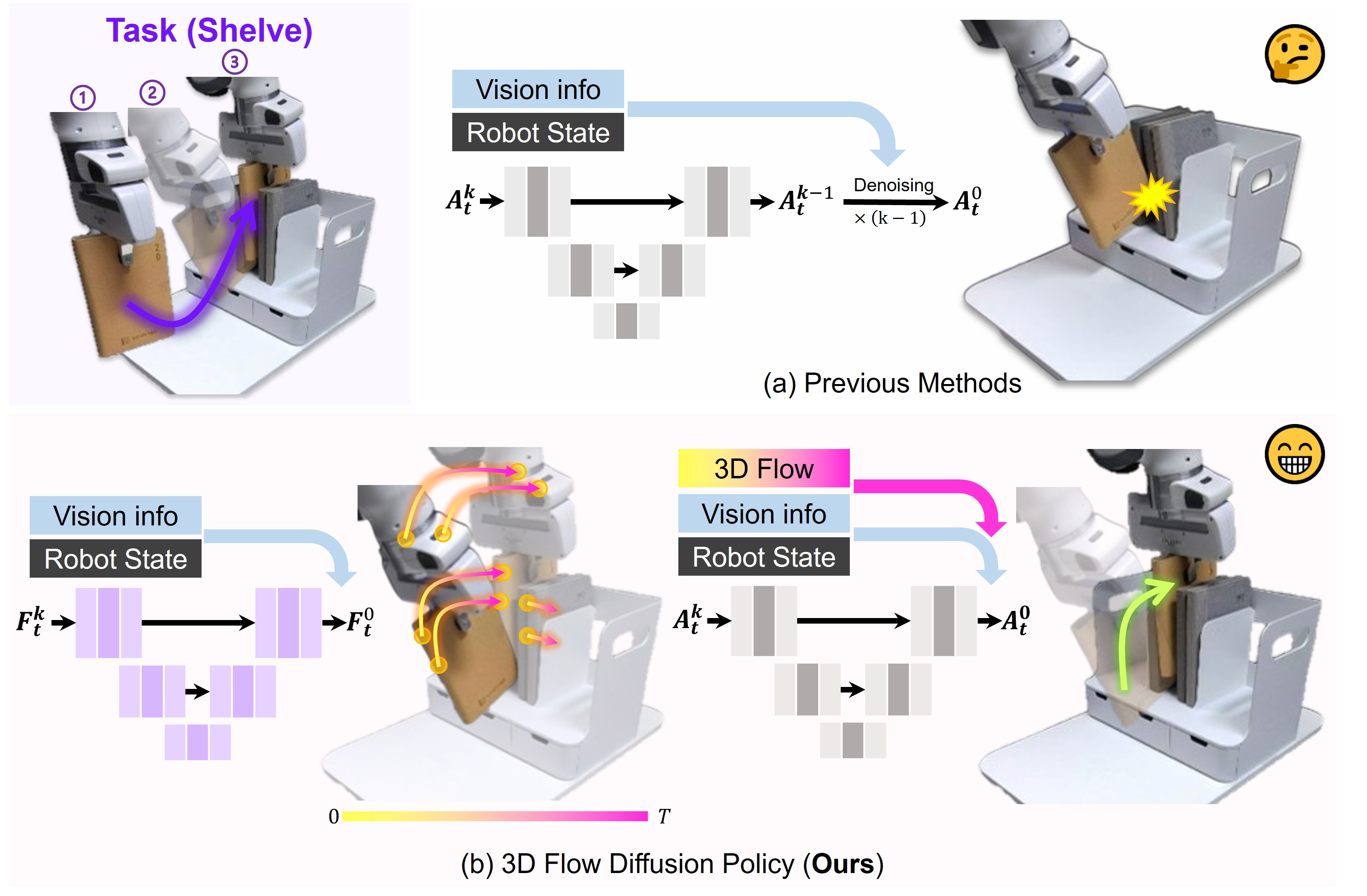
问题定义:现有基于视觉的机器人操作策略,要么直接将视觉输入映射到动作,要么提取全局或物体中心的特征。这些方法忽略了局部运动信息,导致在需要精细控制和复杂接触的场景中表现不佳。因此,需要一种能够有效捕捉和利用局部运动信息的策略学习方法。
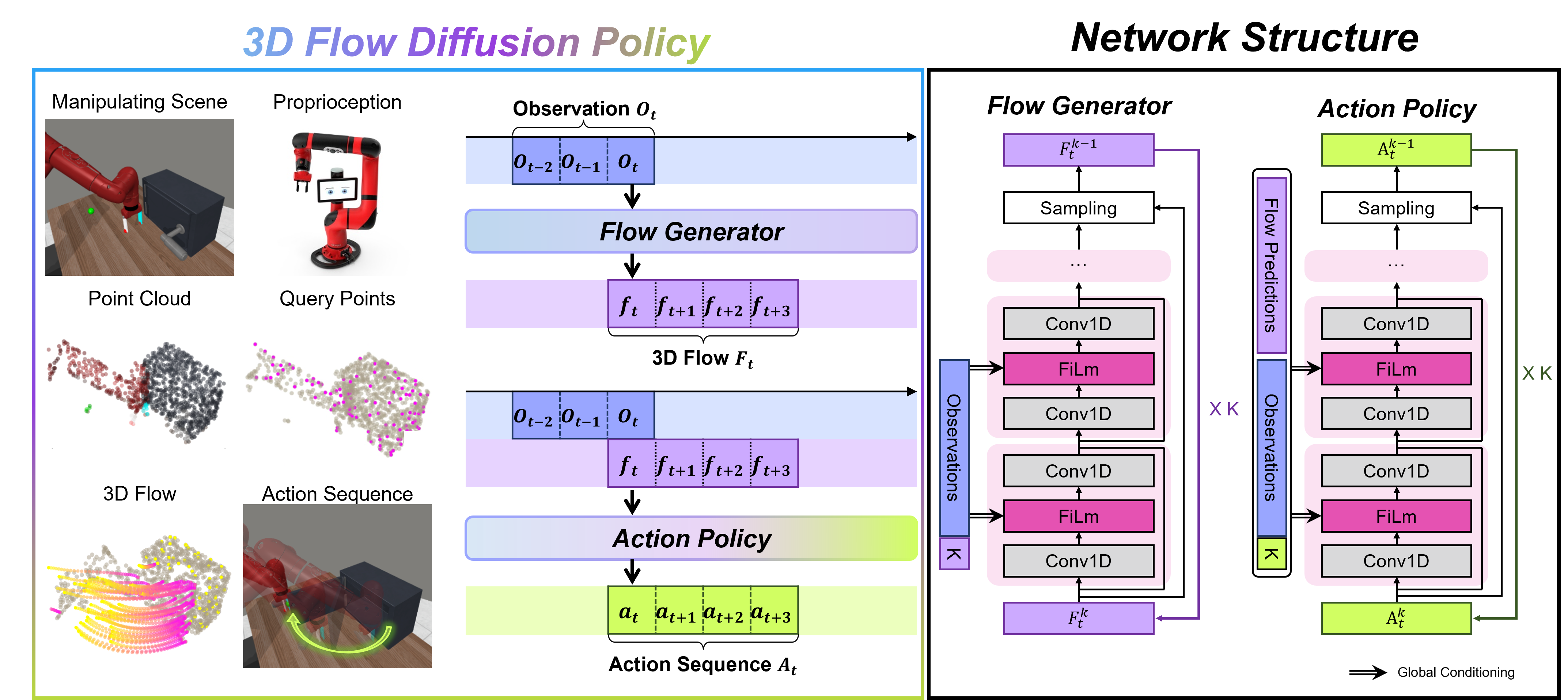
核心思路:论文的核心思路是利用3D flow作为中间表示,显式地建模场景中的局部运动。3D flow描述了场景中每个点在时间上的运动轨迹,能够提供比全局特征更丰富的局部信息。通过预测3D flow,策略可以更好地理解场景动态,从而生成更精确的动作。
技术框架:3D FDP采用扩散模型作为其核心架构。整体流程如下:1) 从视觉输入中提取特征;2) 使用扩散模型预测场景中采样点的3D flow;3) 基于预测的3D flow,生成机器人动作。扩散模型用于学习3D flow的分布,并通过逆扩散过程生成符合场景动态的flow。动作生成模块则根据预测的flow,计算出能够实现预期运动的机器人动作。
关键创新:该论文的关键创新在于将3D flow作为结构化的中间表示,用于学习机器人操作策略。与直接映射或使用全局特征的方法相比,3D flow能够提供更丰富的局部运动信息,从而提高策略的泛化能力和精度。此外,使用扩散模型学习3D flow的分布,能够生成更自然和符合物理规律的运动。
关键设计:3D FDP的关键设计包括:1) 使用PointNet++提取视觉特征;2) 使用条件变分自编码器(CVAE)学习3D flow的先验分布;3) 使用扩散模型进行3D flow的预测和生成;4) 使用Actor-Critic算法训练策略。损失函数包括3D flow预测损失、动作损失和正则化项。网络结构采用U-Net结构,用于捕捉不同尺度的特征。
🖼️ 关键图片
📊 实验亮点
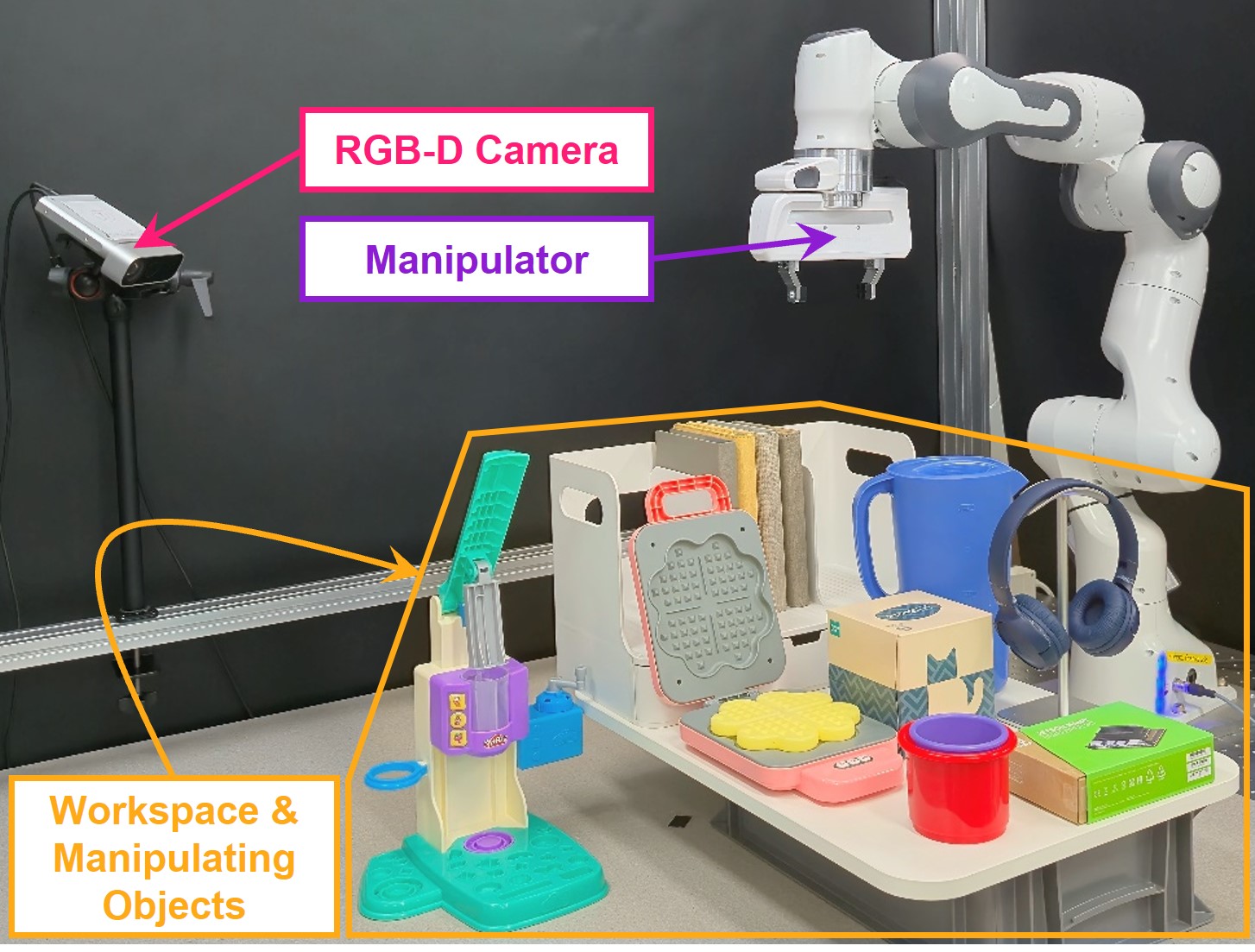
3D FDP在MetaWorld基准测试的50个任务中取得了SOTA性能,尤其是在中等和困难任务上。在真实机器人实验中,3D FDP在接触类和非抓取任务中均优于现有基线。例如,在开抽屉任务中,3D FDP的成功率比之前的最佳方法提高了15%。这些结果表明,3D flow是一种有效的结构化先验,可以提高机器人操作策略的泛化能力和鲁棒性。
🎯 应用场景
该研究成果可应用于各种需要精细操作和复杂交互的机器人任务,例如装配、抓取、操作工具、医疗手术等。通过学习通用的视觉运动策略,机器人可以更好地适应不同的环境和任务,提高自动化水平和工作效率。未来,该方法有望扩展到更复杂的场景,例如多机器人协作和人机交互。
📄 摘要(原文)
Learning robust visuomotor policies that generalize across diverse objects and interaction dynamics remains a central challenge in robotic manipulation. Most existing approaches rely on direct observation-to-action mappings or compress perceptual inputs into global or object-centric features, which often overlook localized motion cues critical for precise and contact-rich manipulation. We present 3D Flow Diffusion Policy (3D FDP), a novel framework that leverages scene-level 3D flow as a structured intermediate representation to capture fine-grained local motion cues. Our approach predicts the temporal trajectories of sampled query points and conditions action generation on these interaction-aware flows, implemented jointly within a unified diffusion architecture. This design grounds manipulation in localized dynamics while enabling the policy to reason about broader scene-level consequences of actions. Extensive experiments on the MetaWorld benchmark show that 3D FDP achieves state-of-the-art performance across 50 tasks, particularly excelling on medium and hard settings. Beyond simulation, we validate our method on eight real-robot tasks, where it consistently outperforms prior baselines in contact-rich and non-prehensile scenarios. These results highlight 3D flow as a powerful structural prior for learning generalizable visuomotor policies, supporting the development of more robust and versatile robotic manipulation. Robot demonstrations, additional results, and code can be found at https://sites.google.com/view/3dfdp/home.