SINGER: An Onboard Generalist Vision-Language Navigation Policy for Drones
作者: Maximilian Adang, JunEn Low, Ola Shorinwa, Mac Schwager
分类: cs.RO
发布日期: 2025-09-23
💡 一句话要点
SINGER:一种用于无人机的通用视觉-语言导航策略,仅使用机载传感器和计算。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无人机导航 视觉语言导航 模拟到真实迁移 高斯溅射 端到端学习
📋 核心要点
- 开放词汇无人机自主导航面临缺乏大规模数据、实时控制需求高和缺乏可靠外部姿态估计等挑战。
- SINGER利用逼真的模拟器生成数据,结合RRT启发的多轨迹专家,训练轻量级端到端视觉运动策略。
- 硬件实验表明,SINGER在零样本模拟到真实迁移中表现出色,显著优于语义引导基线,并减少了碰撞。
📝 摘要(中文)
大型视觉-语言模型在开放词汇机器人策略方面取得了显著进展,例如,通用机器人操作策略,使机器人能够完成以自然语言指定的复杂任务。尽管取得了这些成功,但由于缺乏大规模演示、无人机稳定性的实时控制需求以及缺乏可靠的外部姿态估计模块,开放词汇自主无人机导航仍然是一个未解决的挑战。本文提出了SINGER,用于在开放世界中使用仅机载传感和计算的语言引导自主无人机导航。为了训练鲁棒的开放词汇导航策略,SINGER利用了三个核心组件:(i)一个逼真的语言嵌入飞行模拟器,使用高斯溅射实现最小的模拟到真实差距,以实现高效的数据生成;(ii)一个受RRT启发的用于无碰撞导航演示的多轨迹生成专家;这些被用于训练(iii)一个用于实时闭环控制的轻量级端到端视觉运动策略。通过广泛的硬件飞行实验,我们证明了我们的策略在未见环境和未见语言条件目标对象上的卓越零样本模拟到真实迁移能力。当在约70万-100万个语言条件视觉运动数据的观察-动作对上进行训练并部署在硬件上时,SINGER的平均到达查询目标的概率比速度控制的语义引导基线高23.33%,并且平均保持查询目标在视野中的概率高16.67%,碰撞次数减少10%。
🔬 方法详解
问题定义:论文旨在解决开放世界中,仅使用无人机自身携带的传感器和计算资源,实现基于自然语言指令的自主导航问题。现有方法通常依赖于大规模数据集、外部定位系统或复杂的环境建模,难以满足无人机在资源受限和未知环境下的实时导航需求。
核心思路:论文的核心思路是利用逼真的模拟环境生成大量训练数据,并结合专家系统提供高质量的导航演示,从而训练出一个能够泛化到真实世界的轻量级端到端视觉运动策略。通过最小化模拟到真实的差距,以及优化策略的网络结构,实现无人机在真实环境中的稳定和高效导航。
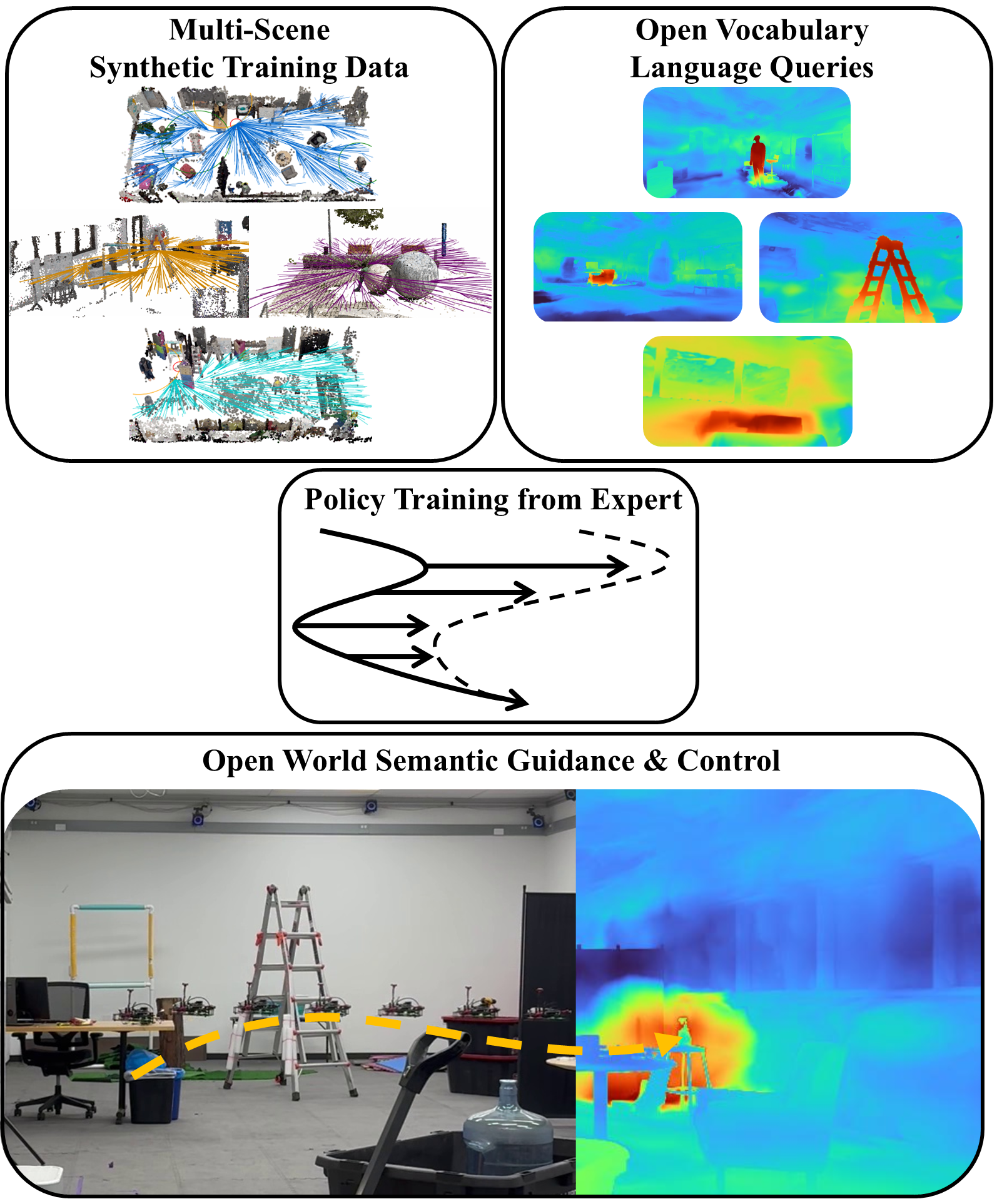
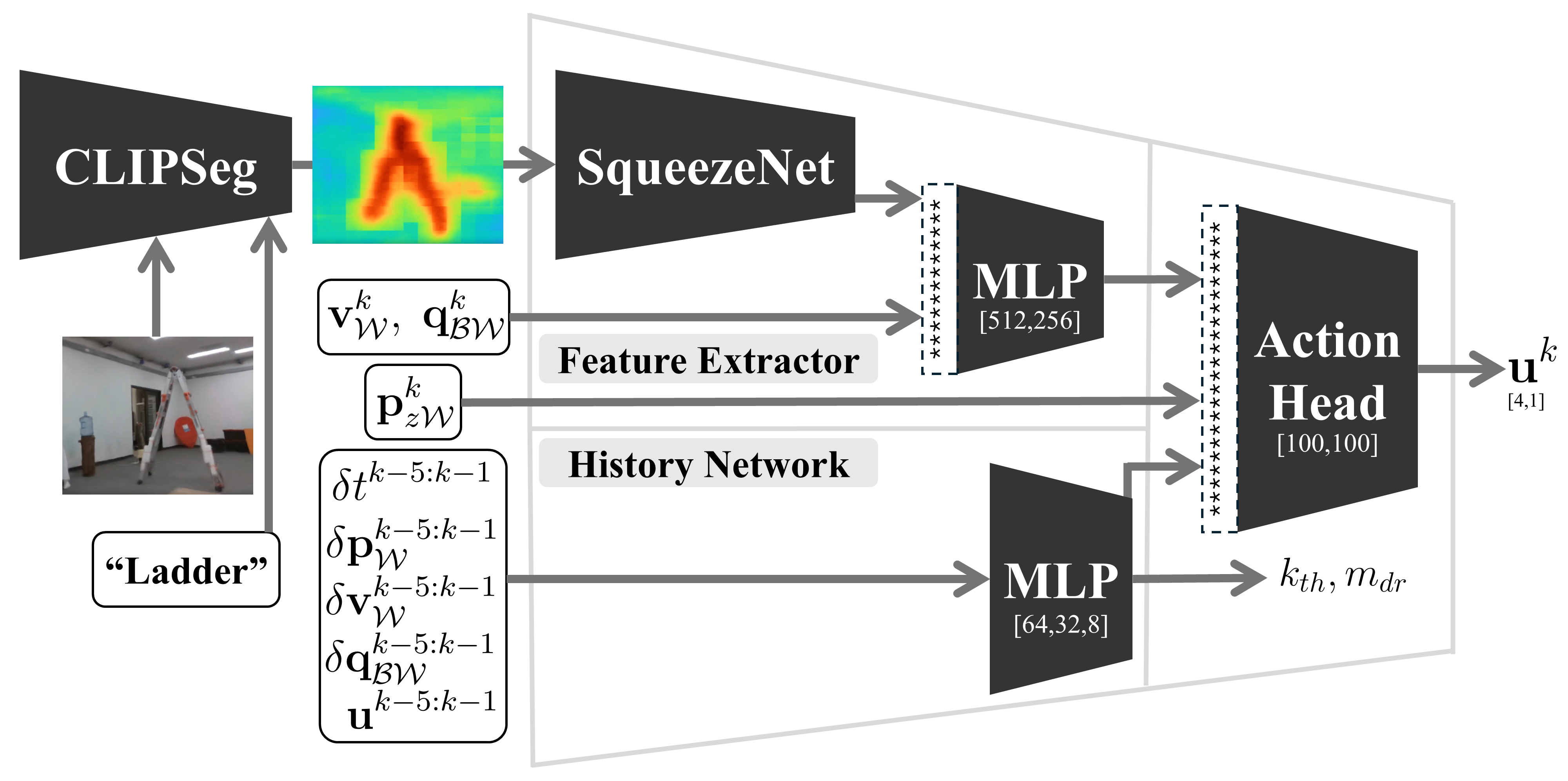
技术框架:SINGER的整体框架包含三个主要模块:1) 基于高斯溅射的逼真语言嵌入飞行模拟器,用于高效生成训练数据;2) 受RRT启发的轨迹生成专家,用于提供无碰撞导航演示;3) 轻量级端到端视觉运动策略,用于实时闭环控制。训练过程包括在模拟器中生成数据,使用专家系统进行轨迹规划,然后利用这些数据训练视觉运动策略。
关键创新:SINGER的关键创新在于其数据生成和策略学习方法。首先,使用高斯溅射技术构建逼真的模拟环境,显著减少了模拟到真实的差距。其次,利用RRT启发的轨迹生成专家,提供了高质量的导航演示,加速了策略学习过程。最后,设计了一个轻量级的端到端视觉运动策略,使其能够在无人机的计算资源上实时运行。
关键设计:SINGER的关键设计包括:1) 使用高斯溅射渲染的逼真模拟环境,确保视觉信息的真实性;2) RRT轨迹生成专家的参数设置,例如搜索步长、碰撞检测阈值等,影响轨迹的质量和效率;3) 轻量级视觉运动策略的网络结构,例如卷积层、循环层和全连接层的配置,以及损失函数的设计,例如模仿学习损失和正则化项。
🖼️ 关键图片

📊 实验亮点
SINGER在硬件飞行实验中表现出色,在未见环境和未见语言条件目标对象上实现了卓越的零样本模拟到真实迁移。与速度控制的语义引导基线相比,SINGER平均到达查询目标的概率提高了23.33%,平均保持查询目标在视野中的概率提高了16.67%,同时碰撞次数减少了10%。这些结果表明SINGER具有很强的泛化能力和鲁棒性。
🎯 应用场景
SINGER技术可应用于物流配送、环境监测、灾害救援、安防巡检等领域。它使无人机能够在复杂和未知的环境中,根据自然语言指令自主执行任务,降低了对专业飞手和外部基础设施的依赖,提高了无人机应用的灵活性和效率。未来,该技术有望进一步扩展到其他机器人平台,实现更广泛的自主导航应用。
📄 摘要(原文)
Large vision-language models have driven remarkable progress in open-vocabulary robot policies, e.g., generalist robot manipulation policies, that enable robots to complete complex tasks specified in natural language. Despite these successes, open-vocabulary autonomous drone navigation remains an unsolved challenge due to the scarcity of large-scale demonstrations, real-time control demands of drones for stabilization, and lack of reliable external pose estimation modules. In this work, we present SINGER for language-guided autonomous drone navigation in the open world using only onboard sensing and compute. To train robust, open-vocabulary navigation policies, SINGER leverages three central components: (i) a photorealistic language-embedded flight simulator with minimal sim-to-real gap using Gaussian Splatting for efficient data generation, (ii) an RRT-inspired multi-trajectory generation expert for collision-free navigation demonstrations, and these are used to train (iii) a lightweight end-to-end visuomotor policy for real-time closed-loop control. Through extensive hardware flight experiments, we demonstrate superior zero-shot sim-to-real transfer of our policy to unseen environments and unseen language-conditioned goal objects. When trained on ~700k-1M observation action pairs of language conditioned visuomotor data and deployed on hardware, SINGER outperforms a velocity-controlled semantic guidance baseline by reaching the query 23.33% more on average, and maintains the query in the field of view 16.67% more on average, with 10% fewer collisions.