LCMF: Lightweight Cross-Modality Mambaformer for Embodied Robotics VQA
作者: Zeyi Kang, Liang He, Yanxin Zhang, Zuheng Ming, Kaixing Zhao
分类: cs.RO, cs.AI
发布日期: 2025-09-23
💡 一句话要点
提出轻量级跨模态Mambaformer(LCMF),用于具身机器人VQA任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身机器人 视觉问答 多模态融合 Mamba 状态空间模型 轻量化模型 人机交互
📋 核心要点
- 现有方法难以有效融合异构数据,且在资源受限的机器人应用中计算效率不足。
- 提出LCMF框架,将跨模态参数共享机制引入Mamba模块,实现高效的模态融合。
- 实验表明,LCMF在VQA任务中取得了74.29%的准确率,并显著降低了计算复杂度。
📝 摘要(中文)
本研究针对具身智能中多模态语义学习面临的异构数据融合和资源受限环境下的计算效率问题,提出了轻量级LCMF级联注意力框架。该框架将多级跨模态参数共享机制引入Mamba模块,结合Cross-Attention和选择性参数共享状态空间模型(SSMs)的优势,实现了异构模态的高效融合和语义互补对齐。实验结果表明,LCMF在VQA任务中超越了现有的多模态基线,准确率达到74.29%,并在EQA视频任务中达到了大型语言模型代理(LLM Agents)分布集群中具有竞争力的中等水平性能。其轻量化设计实现了相对于可比基线平均水平4.35倍的FLOPs减少,同时仅使用166.51M(图像-文本)和219M(视频-文本)参数,为资源受限场景下的人机交互(HRI)应用提供了高效的解决方案,并具有强大的多模态决策泛化能力。
🔬 方法详解
问题定义:论文旨在解决具身机器人视觉问答(VQA)任务中,如何高效融合来自不同模态(例如图像、文本、视频)的信息,并在计算资源有限的机器人平台上实现高性能的问题。现有方法通常计算量大,难以部署在资源受限的机器人上,并且在异构数据融合方面存在效率瓶颈。
核心思路:论文的核心思路是将Mamba架构与跨模态注意力机制相结合,并引入多级参数共享策略,从而在保证模型性能的同时,显著降低计算复杂度。Mamba架构擅长序列建模,而跨模态注意力则能够有效融合不同模态的信息。参数共享进一步减少了模型参数量。
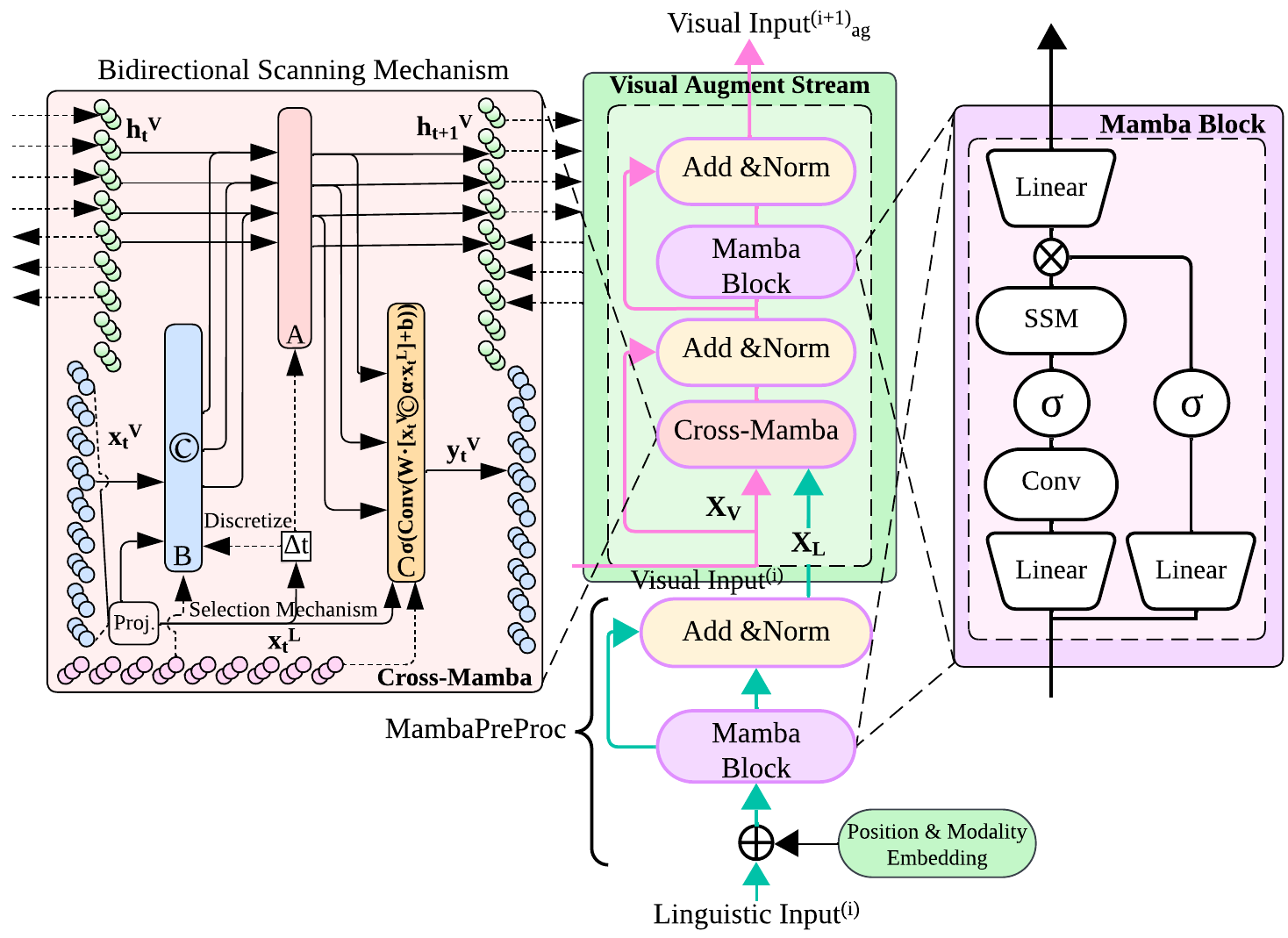
技术框架:LCMF框架主要包含以下几个模块:首先,使用预训练的特征提取器(例如视觉Transformer或文本编码器)提取不同模态的特征。然后,将这些特征输入到LCMF模块中进行融合。LCMF模块的核心是Mamba模块,其中集成了跨模态注意力机制和多级参数共享策略。最后,将融合后的特征输入到预测头中,得到最终的答案。
关键创新:论文最重要的技术创新点在于将Mamba架构与跨模态注意力机制相结合,并提出了多级参数共享策略。Mamba架构相比于传统的Transformer架构,具有更高的计算效率。跨模态注意力机制能够有效融合不同模态的信息。多级参数共享策略则进一步减少了模型参数量,使其更适合部署在资源受限的机器人平台上。
关键设计:LCMF框架的关键设计包括:1) 选择性参数共享SSM,通过选择性地共享SSM的参数,平衡了模型容量和计算效率。2) Cross-Attention机制,用于在不同模态之间进行信息交互。3) 多级参数共享策略,在不同层级上共享参数,进一步减少模型参数量。具体的参数设置和损失函数细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
LCMF在VQA任务中取得了74.29%的准确率,超越了现有的多模态基线。更重要的是,LCMF实现了显著的计算效率提升,FLOPs相对于可比基线平均水平降低了4.35倍,同时参数量仅为166.51M(图像-文本)和219M(视频-文本)。这表明LCMF在保证性能的同时,具有很高的计算效率,更适合部署在资源受限的机器人平台上。
🎯 应用场景
该研究成果可应用于各种具身机器人应用场景,例如家庭服务机器人、工业机器人、医疗机器人等。通过高效的多模态信息融合,机器人能够更好地理解人类指令,感知周围环境,并做出智能决策。该研究有助于提升人机交互的自然性和智能化水平,推动机器人技术在实际场景中的广泛应用。
📄 摘要(原文)
Multimodal semantic learning plays a critical role in embodied intelligence, especially when robots perceive their surroundings, understand human instructions, and make intelligent decisions. However, the field faces technical challenges such as effective fusion of heterogeneous data and computational efficiency in resource-constrained environments. To address these challenges, this study proposes the lightweight LCMF cascaded attention framework, introducing a multi-level cross-modal parameter sharing mechanism into the Mamba module. By integrating the advantages of Cross-Attention and Selective parameter-sharing State Space Models (SSMs), the framework achieves efficient fusion of heterogeneous modalities and semantic complementary alignment. Experimental results show that LCMF surpasses existing multimodal baselines with an accuracy of 74.29% in VQA tasks and achieves competitive mid-tier performance within the distribution cluster of Large Language Model Agents (LLM Agents) in EQA video tasks. Its lightweight design achieves a 4.35-fold reduction in FLOPs relative to the average of comparable baselines while using only 166.51M parameters (image-text) and 219M parameters (video-text), providing an efficient solution for Human-Robot Interaction (HRI) applications in resource-constrained scenarios with strong multimodal decision generalization capabilities.