Language-in-the-Loop Culvert Inspection on the Erie Canal
作者: Yashom Dighe, Yash Turkar, Karthik Dantu
分类: cs.RO, cs.CV
发布日期: 2025-09-22
备注: First two authors contributed equally
💡 一句话要点
提出VISION系统,利用语言引导的视觉模型实现伊利运河涵洞的自主检测。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉-语言模型 机器人自主导航 涵洞检测 基础设施检测 视点规划
📋 核心要点
- 人工检测运河涵洞面临诸多挑战,如环境恶劣、通道受限等,效率低且成本高。
- VISION系统利用语言引导的视觉模型,结合视点规划,实现涵洞的自主检测与评估。
- 实验结果表明,该系统能有效识别感兴趣区域,并生成与专家评估高度一致的检测报告。
📝 摘要(中文)
本研究提出了一种端到端的、语言在环的自主系统VISION,用于伊利运河等运河涵洞的自主检测。由于涵洞年代久远、几何结构复杂、光照不足、天气影响以及缺乏便捷通道,人工检测极具挑战。VISION系统将网络规模的视觉-语言模型(VLM)与约束视点规划相结合,实现自主检测。系统通过简短的提示词,利用VLM生成带有理由和置信度的开放词汇感兴趣区域(ROI)提议,并融合立体深度信息以恢复尺度。规划器感知涵洞约束,指挥四足机器人进行重新定位,以捕获目标特写图像。VISION系统部署在伊利运河下的四足机器人上,在板载设备上闭环执行“看、决定、移动、重新成像”流程,生成高分辨率图像,无需特定领域的微调即可进行详细报告。纽约运河公司人员的外部评估表明,初始ROI提议与领域专家达成61.4%的一致,重新成像后的最终评估达到80%,表明VISION系统将初步假设转化为基于事实的、与专家对齐的发现。
🔬 方法详解
问题定义:论文旨在解决运河涵洞人工检测效率低、成本高的问题。现有方法依赖人工目视检查,容易受到环境因素影响,且难以覆盖所有区域。因此,需要一种自动化、智能化的检测方案,以提高检测效率和准确性。
核心思路:论文的核心思路是利用语言引导的视觉-语言模型(VLM),结合机器人自主导航和视点规划,实现涵洞的自主检测。通过语言提示,VLM能够识别感兴趣区域,并指导机器人调整姿态,获取高质量图像,最终生成检测报告。
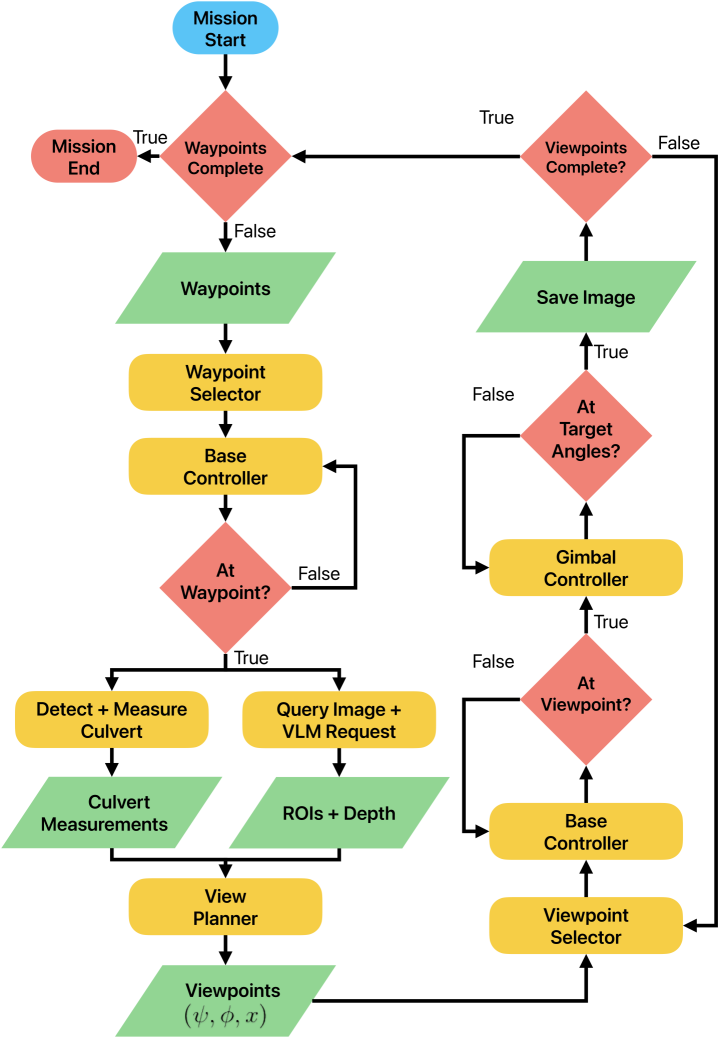
技术框架:VISION系统的整体架构包含以下几个主要模块:1) 视觉-语言模型(VLM):负责根据语言提示生成ROI提议,并提供置信度评估;2) 立体视觉模块:用于恢复场景的深度信息,实现尺度估计;3) 规划器:根据涵洞的几何约束和ROI信息,规划机器人的运动轨迹,调整视点;4) 四足机器人:作为执行机构,根据规划器的指令进行移动和图像采集;5) 后处理模块:对采集到的图像进行处理和分析,生成最终的检测报告。
关键创新:该论文的关键创新在于将语言引导的视觉模型与机器人自主导航相结合,实现了一种端到端的涵洞检测系统。与传统的基于图像处理的检测方法相比,该方法能够利用语言信息,更准确地识别感兴趣区域,并提高检测的鲁棒性。此外,该系统无需特定领域的微调,具有较强的泛化能力。
关键设计:VLM使用预训练的Web规模视觉-语言模型,通过简短的文本提示来引导模型关注特定的结构或缺陷。立体视觉模块使用双目相机获取深度信息,并采用鲁棒的算法进行尺度估计。规划器采用基于约束的优化方法,确保机器人的运动轨迹满足涵洞的几何约束,并最大化ROI的覆盖率。四足机器人采用模块化设计,方便集成各种传感器和执行器。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VISION系统生成的初始ROI提议与领域专家达成61.4%的一致性,经过重新成像后,最终评估的一致性提高到80%。这表明该系统能够有效地将初步假设转化为基于事实的、与专家对齐的发现,验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种基础设施的自动化检测,例如桥梁、隧道、管道等。通过部署类似的自主检测系统,可以降低人工检测的成本和风险,提高检测效率和准确性,为基础设施的安全运行提供保障。此外,该技术还可以扩展到其他领域,如灾后救援、环境监测等。
📄 摘要(原文)
Culverts on canals such as the Erie Canal, built originally in 1825, require frequent inspections to ensure safe operation. Human inspection of culverts is challenging due to age, geometry, poor illumination, weather, and lack of easy access. We introduce VISION, an end-to-end, language-in-the-loop autonomy system that couples a web-scale vision-language model (VLM) with constrained viewpoint planning for autonomous inspection of culverts. Brief prompts to the VLM solicit open-vocabulary ROI proposals with rationales and confidences, stereo depth is fused to recover scale, and a planner -- aware of culvert constraints -- commands repositioning moves to capture targeted close-ups. Deployed on a quadruped in a culvert under the Erie Canal, VISION closes the see, decide, move, re-image loop on-board and produces high-resolution images for detailed reporting without domain-specific fine-tuning. In an external evaluation by New York Canal Corporation personnel, initial ROI proposals achieved 61.4\% agreement with subject-matter experts, and final post-re-imaging assessments reached 80\%, indicating that VISION converts tentative hypotheses into grounded, expert-aligned findings.