HuMam: Humanoid Motion Control via End-to-End Deep Reinforcement Learning with Mamba
作者: Yinuo Wang, Yuanyang Qi, Jinzhao Zhou, Gavin Tao
分类: cs.RO, cs.AI, cs.ET, eess.SP, eess.SY
发布日期: 2025-09-22
备注: 10 pages
💡 一句话要点
HuMam:基于Mamba的端到端深度强化学习人形机器人运动控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 强化学习 Mamba 运动控制 端到端学习
📋 核心要点
- 人形机器人运动控制的端到端强化学习方法具有紧凑的感知-动作映射优势,但现有策略常面临训练不稳定、特征融合效率低和驱动成本高等问题。
- HuMam框架的核心在于使用单层Mamba编码器融合机器人状态、足迹目标和相位时钟,并结合精心设计的奖励函数,实现高效稳定的运动控制。
- 实验表明,HuMam在学习效率、训练稳定性和任务性能上优于传统前馈网络,同时降低了功耗和扭矩峰值,验证了Mamba在人形机器人控制中的潜力。
📝 摘要(中文)
本文提出HuMam,一个以状态为中心的端到端强化学习框架,用于人形机器人运动控制。该框架采用单层Mamba编码器融合机器人中心状态、面向的足迹目标和连续相位时钟。策略输出由低级PD环跟踪的关节位置目标,并使用PPO进行优化。一个简洁的六项奖励平衡了接触质量、摆动平滑度、足部放置、姿势和身体稳定性,同时隐式地促进节能。在mc-mujoco的JVRC-1人形机器人上,HuMam在学习效率、训练稳定性和整体任务性能方面始终优于强大的前馈基线,同时降低了功耗和扭矩峰值。据我们所知,这是第一个采用Mamba作为融合骨干的端到端人形机器人强化学习控制器,在效率、稳定性和控制经济性方面表现出明显的优势。
🔬 方法详解
问题定义:现有的人形机器人运动控制方法,特别是基于端到端强化学习的方法,虽然具有感知-动作映射紧凑的优点,但往往面临训练不稳定、特征融合效率低以及驱动成本高等问题。这些问题限制了其在实际机器人系统中的应用。
核心思路:HuMam的核心思路是利用Mamba架构强大的序列建模能力,更有效地融合机器人状态、足迹目标和相位时钟等信息,从而学习到更稳定、更高效的运动控制策略。同时,通过精心设计的奖励函数,引导策略学习到符合物理规律和节能原则的运动方式。
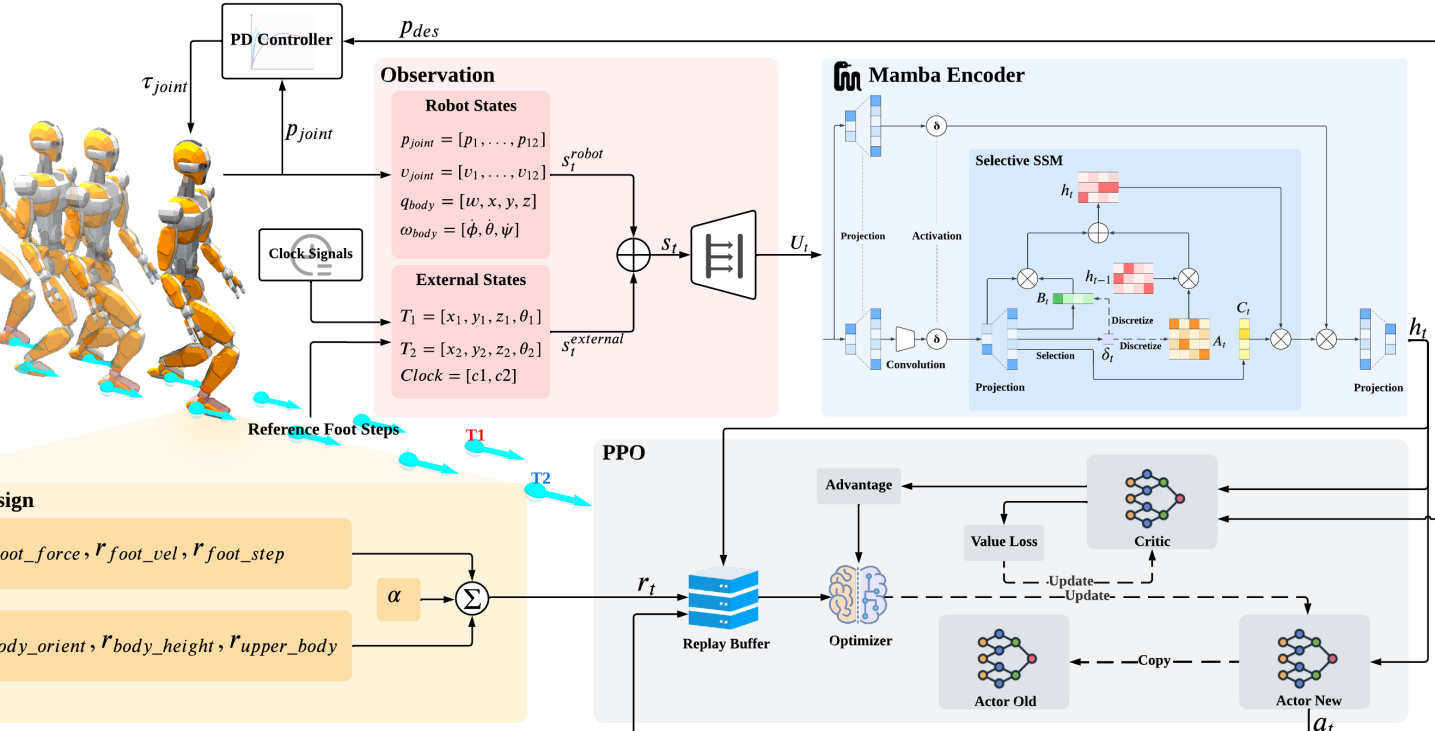
技术框架:HuMam框架主要包含以下几个模块:1) 状态表示:将机器人状态(如关节角度、速度)、足迹目标(位置、方向)和相位时钟进行编码;2) Mamba编码器:使用单层Mamba编码器融合上述状态表示,提取关键特征;3) 策略网络:基于Mamba编码器的输出,预测关节位置目标;4) PD控制器:使用低级PD控制器跟踪策略网络输出的关节位置目标,实现机器人运动;5) 奖励函数:设计包含接触质量、摆动平滑度、足部放置、姿势和身体稳定性等多项的奖励函数,引导策略学习。
关键创新:HuMam最重要的创新点在于首次将Mamba架构引入到端到端人形机器人强化学习控制中。与传统的循环神经网络(RNN)或Transformer相比,Mamba具有更强的序列建模能力和更高的计算效率,能够更好地处理机器人运动控制中的时序依赖关系。此外,HuMam还提出了一种简洁有效的奖励函数设计,能够平衡多个目标,并隐式地促进节能。
关键设计:HuMam的关键设计包括:1) 单层Mamba编码器的参数设置,例如隐藏层维度、状态空间维度等;2) 奖励函数中各项的权重设置,需要根据具体任务进行调整;3) PD控制器的参数设置,例如比例增益和微分增益,需要根据机器人动力学特性进行调整;4) PPO算法的超参数设置,例如学习率、裁剪率等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,HuMam在JVRC-1人形机器人上取得了显著的性能提升。与强前馈基线相比,HuMam在学习效率、训练稳定性和整体任务性能方面均有提高,同时降低了功耗和扭矩峰值。这些结果验证了Mamba架构在人形机器人运动控制中的有效性,并为未来的研究提供了有价值的参考。
🎯 应用场景
HuMam具有广泛的应用前景,可用于开发更智能、更高效的人形机器人,应用于灾难救援、医疗辅助、工业生产等领域。该研究为人形机器人运动控制提供了一种新的思路,有望推动人形机器人技术的进一步发展,并最终实现通用人形机器人的目标。
📄 摘要(原文)
End-to-end reinforcement learning (RL) for humanoid locomotion is appealing for its compact perception-action mapping, yet practical policies often suffer from training instability, inefficient feature fusion, and high actuation cost. We present HuMam, a state-centric end-to-end RL framework that employs a single-layer Mamba encoder to fuse robot-centric states with oriented footstep targets and a continuous phase clock. The policy outputs joint position targets tracked by a low-level PD loop and is optimized with PPO. A concise six-term reward balances contact quality, swing smoothness, foot placement, posture, and body stability while implicitly promoting energy saving. On the JVRC-1 humanoid in mc-mujoco, HuMam consistently improves learning efficiency, training stability, and overall task performance over a strong feedforward baseline, while reducing power consumption and torque peaks. To our knowledge, this is the first end-to-end humanoid RL controller that adopts Mamba as the fusion backbone, demonstrating tangible gains in efficiency, stability, and control economy.