M3ET: Efficient Vision-Language Learning for Robotics based on Multimodal Mamba-Enhanced Transformer
作者: Yanxin Zhang, Liang He, Zeyi Kang, Zuheng Ming, Kaixing Zhao
分类: cs.RO
发布日期: 2025-09-22
备注: 8 pages
💡 一句话要点
提出M3ET:一种高效的基于多模态Mamba增强Transformer的机器人视觉-语言学习方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 机器人视觉 Transformer Mamba 自适应注意力 轻量级模型 视觉问答 信息融合
📋 核心要点
- 现有方法在机器人视觉-语言学习中,难以有效利用文本模态,且依赖有监督预训练,限制了无监督环境下的语义提取。
- M3ET通过结合Mamba模块和语义自适应注意力机制,优化特征融合、对齐和模态重建,实现高效的多模态学习。
- 实验表明,M3ET在跨任务性能上有所提升,预训练推理速度提升2.3倍,同时显著减少了模型参数量。
📝 摘要(中文)
近年来,多模态学习在机器人视觉和信息融合中变得至关重要,尤其是在理解复杂环境中人类行为方面。然而,当前方法难以充分利用文本模态,依赖于有监督的预训练模型,这限制了在无监督机器人环境中,特别是在存在显著模态损失情况下的语义提取。这些方法也往往计算密集,导致实际应用中资源消耗高。为了应对这些挑战,我们提出了多模态Mamba增强Transformer(M3ET),这是一种轻量级模型,专为高效多模态学习而设计,尤其是在移动平台上。通过结合Mamba模块和基于语义的自适应注意力机制,M3ET优化了特征融合、对齐和模态重建。实验表明,M3ET提高了跨任务性能,预训练推理速度提高了2.3倍。特别是,M3ET的核心VQA任务准确率保持在0.74,而模型参数量减少了0.67。尽管在EQA任务上的性能有限,但M3ET的轻量级设计使其非常适合部署在资源受限的机器人平台上。
🔬 方法详解
问题定义:论文旨在解决机器人视觉-语言学习中,现有方法无法有效利用文本模态,且计算资源消耗过高的问题。现有方法依赖有监督预训练模型,限制了在无监督机器人环境中,尤其是在存在显著模态损失情况下的语义提取。此外,这些方法计算密集,难以部署在资源受限的机器人平台上。
核心思路:论文的核心思路是设计一个轻量级且高效的多模态学习模型,即M3ET。该模型通过引入Mamba模块和语义自适应注意力机制,优化特征融合、对齐和模态重建,从而在保证性能的同时,降低计算复杂度,使其更适合在移动机器人平台上部署。
技术框架:M3ET模型主要包含以下几个关键模块:首先,使用视觉和语言编码器分别提取图像和文本特征。然后,通过Mamba模块增强特征表示,提高模型对序列数据的处理能力。接着,利用语义自适应注意力机制,动态地调整不同模态特征的权重,实现更有效的特征融合。最后,通过多模态解码器进行任务预测,例如视觉问答(VQA)和实体问答(EQA)。
关键创新:M3ET的关键创新在于将Mamba模块引入到多模态Transformer架构中,并结合了语义自适应注意力机制。Mamba模块能够高效地处理序列数据,降低计算复杂度,而语义自适应注意力机制则能够根据不同模态特征的语义信息,动态地调整特征权重,从而提高特征融合的效率。与传统的Transformer模型相比,M3ET在保证性能的同时,显著降低了参数量和计算复杂度。
关键设计:Mamba模块的具体实现细节,包括状态空间模型的参数设置和选择机制。语义自适应注意力机制的设计,如何根据语义信息计算注意力权重。损失函数的设计,如何平衡不同任务之间的性能。模型训练的超参数设置,例如学习率、batch size等。
🖼️ 关键图片


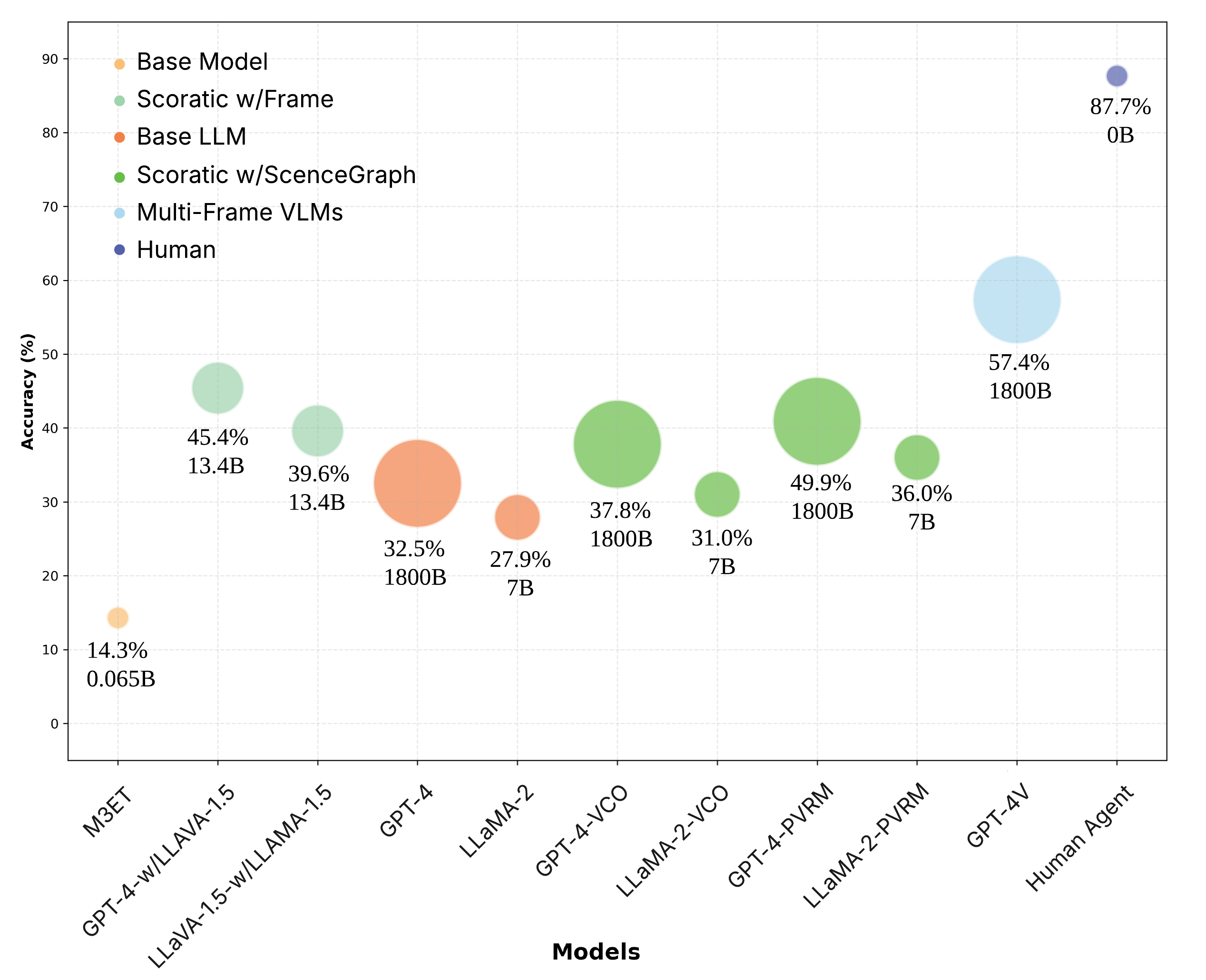
📊 实验亮点
实验结果表明,M3ET在跨任务性能上有所提升,预训练推理速度提高了2.3倍。在核心VQA任务中,M3ET的准确率保持在0.74,同时模型参数量减少了0.67。虽然在EQA任务上的性能有限,但M3ET的轻量级设计使其更适合部署在资源受限的机器人平台上。这些结果验证了M3ET在效率和性能方面的优势。
🎯 应用场景
M3ET适用于资源受限的移动机器人平台,可应用于智能导航、物体识别、人机交互等场景。该研究的实际价值在于降低了多模态学习模型的计算成本,使其能够在低功耗设备上运行,从而扩展了机器人应用的可能性。未来,M3ET可以进一步应用于更复杂的机器人任务,例如自主操作、环境理解和决策制定。
📄 摘要(原文)
In recent years, multimodal learning has become essential in robotic vision and information fusion, especially for understanding human behavior in complex environments. However, current methods struggle to fully leverage the textual modality, relying on supervised pretrained models, which limits semantic extraction in unsupervised robotic environments, particularly with significant modality loss. These methods also tend to be computationally intensive, leading to high resource consumption in real-world applications. To address these challenges, we propose the Multi Modal Mamba Enhanced Transformer (M3ET), a lightweight model designed for efficient multimodal learning, particularly on mobile platforms. By incorporating the Mamba module and a semantic-based adaptive attention mechanism, M3ET optimizes feature fusion, alignment, and modality reconstruction. Our experiments show that M3ET improves cross-task performance, with a 2.3 times increase in pretraining inference speed. In particular, the core VQA task accuracy of M3ET remains at 0.74, while the model's parameter count is reduced by 0.67. Although performance on the EQA task is limited, M3ET's lightweight design makes it well suited for deployment on resource-constrained robotic platforms.