OpenGVL -- Benchmarking Visual Temporal Progress for Data Curation
作者: Paweł Budzianowski, Emilia Wiśnios, Gracjan Góral, Igor Kulakov, Viktor Petrenko, Krzysztof Walas
分类: cs.RO, cs.CL
发布日期: 2025-09-22 (更新: 2025-12-01)
备注: Workshop on Making Sense of Data in Robotics: Composition, Curation, and Interpretability at Scale at CoRL 2025
💡 一句话要点
OpenGVL:用于数据标注的视觉时序进展评估基准
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人 视觉-语言模型 数据标注 时序进展预测 基准测试 数据管理 自动化 数据质量评估
📋 核心要点
- 机器人数据稀缺限制了技术发展,而海量数据的有效利用面临自动标注和管理难题。
- OpenGVL利用视觉-语言模型预测任务进展,为大规模机器人数据自动标注和管理提供解决方案。
- 实验表明,开源模型在时序进展预测方面性能显著低于闭源模型,OpenGVL可用于数据质量评估。
📝 摘要(中文)
数据稀缺仍然是推动机器人技术进步的最主要限制因素之一。然而,大量可用的机器人数据正在成倍增长,为大规模数据利用创造了新的机会。可靠的时序任务完成预测可以帮助自动标注和管理这些大规模数据。最近提出的生成价值学习(GVL)方法,利用视觉-语言模型(VLM)中嵌入的知识来预测视觉观察中的任务进展。在GVL的基础上,我们提出了OpenGVL,这是一个综合性的基准,用于评估涉及机器人和人类的各种具有挑战性的操作任务中的任务进展。我们评估了公开可用的开源基础模型的能力,表明开源模型系列的性能明显低于闭源模型,在时序进展预测任务中仅达到其性能的约70%。此外,我们展示了OpenGVL如何作为自动数据管理和过滤的实用工具,从而能够有效评估大规模机器人数据集的质量。我们发布了该基准以及完整的代码库。
🔬 方法详解
问题定义:论文旨在解决机器人领域中数据标注和管理的问题。现有方法难以有效利用日益增长的海量机器人数据,缺乏可靠的时序任务完成预测机制,导致数据质量参差不齐,阻碍了机器人技术的发展。现有方法,特别是开源模型,在时序进展预测方面表现不佳,无法满足实际应用的需求。
核心思路:论文的核心思路是利用视觉-语言模型(VLMs)中蕴含的知识,通过观察视觉信息来预测任务的进展程度。这种方法避免了手动标注的繁琐和高成本,能够自动地对大规模机器人数据集进行标注和管理。通过评估任务进展,可以有效地筛选出高质量的数据,从而提高机器人学习的效率和性能。
技术框架:OpenGVL的整体框架包括以下几个主要模块:1)数据集构建:收集包含各种机器人和人类操作任务的视频数据。2)特征提取:使用视觉-语言模型(VLMs)从视频帧中提取视觉特征。3)任务进展预测:基于提取的视觉特征,利用GVL方法预测任务的进展程度。4)性能评估:使用OpenGVL基准评估不同模型的任务进展预测性能。5)数据管理:根据任务进展预测结果,对数据集进行自动标注、过滤和排序。
关键创新:OpenGVL的关键创新在于:1)提出了一个综合性的基准,用于评估不同模型在时序任务进展预测方面的性能。2)展示了开源模型在时序进展预测方面与闭源模型的差距,并为开源模型的发展提供了方向。3)验证了GVL方法在自动数据管理方面的有效性,为大规模机器人数据集的利用提供了新的思路。
关键设计:OpenGVL基准包含多种具有挑战性的操作任务,涵盖机器人和人类两种主体。论文使用了公开可用的开源基础模型进行评估,并与闭源模型进行了对比。在任务进展预测方面,论文采用了GVL方法,并针对具体任务进行了优化。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片

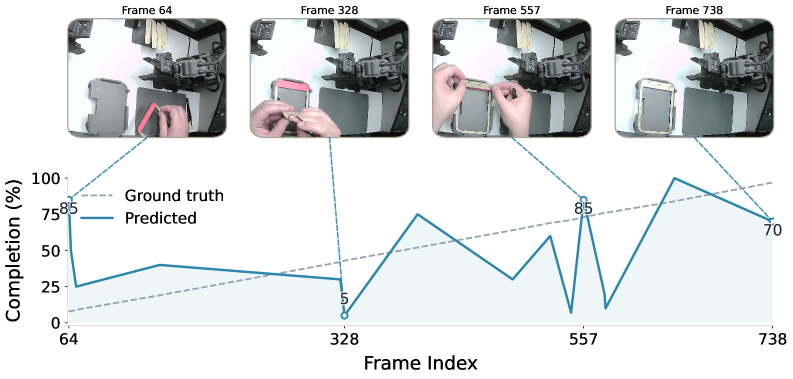

📊 实验亮点
实验结果表明,开源模型在OpenGVL基准上的时序进展预测性能仅为闭源模型的约70%,存在显著差距。OpenGVL能够有效评估数据质量,为大规模机器人数据集的筛选和管理提供有力支持,提升数据利用效率。
🎯 应用场景
OpenGVL可应用于机器人数据集的自动标注、数据清洗和质量评估,提升机器人学习效率。该研究成果有助于推动机器人技术在自动化生产、智能家居、医疗健康等领域的应用,加速机器人智能化进程。
📄 摘要(原文)
Data scarcity remains one of the most limiting factors in driving progress in robotics. However, the amount of available robotics data in the wild is growing exponentially, creating new opportunities for large-scale data utilization. Reliable temporal task completion prediction could help automatically annotate and curate this data at scale. The Generative Value Learning (GVL) approach was recently proposed, leveraging the knowledge embedded in vision-language models (VLMs) to predict task progress from visual observations. Building upon GVL, we propose OpenGVL, a comprehensive benchmark for estimating task progress across diverse challenging manipulation tasks involving both robotic and human embodiments. We evaluate the capabilities of publicly available open-source foundation models, showing that open-source model families significantly underperform closed-source counterparts, achieving only approximately $70\%$ of their performance on temporal progress prediction tasks. Furthermore, we demonstrate how OpenGVL can serve as a practical tool for automated data curation and filtering, enabling efficient quality assessment of large-scale robotics datasets. We release the benchmark along with the complete codebase at \href{github.com/budzianowski/opengvl}{OpenGVL}.