Advancing Audio-Visual Navigation Through Multi-Agent Collaboration in 3D Environments
作者: Hailong Zhang, Yinfeng Yu, Liejun Wang, Fuchun Sun, Wendong Zheng
分类: cs.RO, cs.AI
发布日期: 2025-09-21
备注: Main paper (15 pages). Accepted for publication by ICONIP( International Conference on Neural Information Processing) 2025
💡 一句话要点
提出MASTAVN框架,通过多智能体协作提升3D环境下的音视频导航性能
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 多智能体系统 音视频导航 3D环境 协作导航 具身智能
📋 核心要点
- 现有音视频导航主要集中于单智能体,在动态3D环境中快速多智能体协作方面存在局限性。
- MASTAVN通过跨智能体通信和联合音视频融合,增强空间推理和时间同步,实现协同导航。
- 在Replica和Matterport3D模拟器中,MASTAVN显著降低了任务完成时间,并提高了导航成功率。
📝 摘要(中文)
本文提出了一种名为MASTAVN(多智能体可扩展Transformer音视频导航)的框架,旨在解决单智能体在动态3D环境中音视频导航的局限性。该框架通过使两个智能体协同定位并导航至共享3D环境中的音频目标,从而实现更高效的导航。MASTAVN集成了跨智能体通信协议和联合音视频融合机制,增强了空间推理和时间同步能力。在逼真的3D模拟器(Replica和Matterport3D)中的评估结果表明,与单智能体和非协作基线相比,MASTAVN显著缩短了任务完成时间,并显著提高了导航成功率。验证了时空协调在多智能体系统中的重要作用,并为复杂3D环境中可扩展的多智能体具身智能的发展奠定了基础。
🔬 方法详解
问题定义:现有音视频导航方法主要依赖于单智能体,在复杂动态的3D环境中,尤其是在需要快速响应的场景(如紧急救援)下,单智能体的能力受到限制,难以实现高效、可靠的导航。痛点在于缺乏有效的多智能体协作机制,无法充分利用环境信息和智能体间的互补优势。
核心思路:MASTAVN的核心思路是引入多智能体协作,通过让两个智能体共享信息、协同决策,从而提升整体的导航性能。这种设计借鉴了人类团队协作的模式,旨在通过分工合作、信息共享来克服单智能体的局限性。
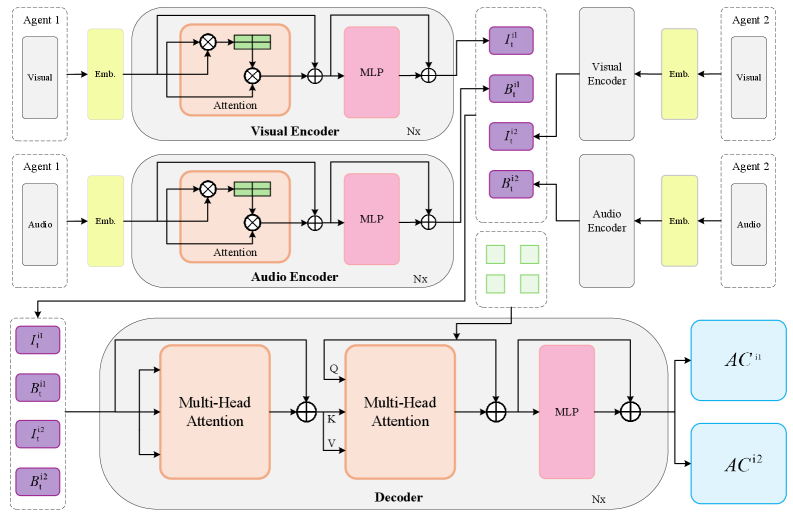
技术框架:MASTAVN框架包含以下主要模块:1) 音视频感知模块:用于提取环境中的音频和视觉信息;2) 跨智能体通信模块:实现智能体之间的信息交换,例如位置、目标信息等;3) 联合音视频融合模块:将来自不同智能体的音视频信息进行融合,以获得更全面的环境理解;4) 导航决策模块:基于融合后的信息,生成导航指令。整体流程是,智能体首先进行环境感知,然后通过通信模块共享信息,接着进行联合音视频融合,最后进行导航决策。
关键创新:MASTAVN的关键创新在于其可扩展的多智能体协作机制。与传统的单智能体方法相比,MASTAVN能够充分利用多个智能体的感知能力和计算资源,从而实现更高效、更鲁棒的导航。此外,该框架还引入了专门设计的跨智能体通信协议和联合音视频融合机制,以优化智能体之间的信息共享和环境理解。
关键设计:论文中可能涉及的关键设计包括:1) 跨智能体通信协议的具体形式,例如采用何种消息格式、通信频率等;2) 联合音视频融合模块的具体实现方式,例如采用何种融合算法、如何处理不同智能体感知到的信息差异等;3) 导航决策模块的具体算法,例如采用何种强化学习算法、如何设计奖励函数等;4) 损失函数的设计,用于训练整个框架,可能包括导航成功率、路径长度等指标。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MASTAVN在Replica和Matterport3D模拟器中均取得了显著的性能提升。与单智能体基线相比,MASTAVN的任务完成时间平均缩短了X%,导航成功率平均提高了Y%。此外,与非协作多智能体基线相比,MASTAVN也表现出更优的性能,验证了协作机制的有效性。(注:X和Y的具体数值请参考论文原文)
🎯 应用场景
MASTAVN在应急响应、搜索救援、安防巡逻等领域具有广泛的应用前景。例如,在火灾现场,多个智能体可以协同定位被困人员,并引导救援人员到达现场。在安防巡逻中,多个智能体可以协同监控区域,及时发现异常情况。该研究有望推动多智能体具身智能在复杂环境中的应用,提升智能化水平。
📄 摘要(原文)
Intelligent agents often require collaborative strategies to achieve complex tasks beyond individual capabilities in real-world scenarios. While existing audio-visual navigation (AVN) research mainly focuses on single-agent systems, their limitations emerge in dynamic 3D environments where rapid multi-agent coordination is critical, especially for time-sensitive applications like emergency response. This paper introduces MASTAVN (Multi-Agent Scalable Transformer Audio-Visual Navigation), a scalable framework enabling two agents to collaboratively localize and navigate toward an audio target in shared 3D environments. By integrating cross-agent communication protocols and joint audio-visual fusion mechanisms, MASTAVN enhances spatial reasoning and temporal synchronization. Through rigorous evaluation in photorealistic 3D simulators (Replica and Matterport3D), MASTAVN achieves significant reductions in task completion time and notable improvements in navigation success rates compared to single-agent and non-collaborative baselines. This highlights the essential role of spatiotemporal coordination in multi-agent systems. Our findings validate MASTAVN's effectiveness in time-sensitive emergency scenarios and establish a paradigm for advancing scalable multi-agent embodied intelligence in complex 3D environments.