Scalable Multi Agent Diffusion Policies for Coverage Control
作者: Frederic Vatnsdal, Romina Garcia Camargo, Saurav Agarwal, Alejandro Ribeiro
分类: cs.RO
发布日期: 2025-09-21
💡 一句话要点
提出MADP:一种可扩展的多智能体扩散策略,用于覆盖控制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体系统 扩散模型 覆盖控制 模仿学习 分散式控制
📋 核心要点
- 现有方法难以有效捕捉多智能体间的复杂依赖关系,限制了其在复杂环境下的协作能力。
- MADP利用扩散模型生成动作分布样本,通过融合智能体间的感知信息,实现分散式策略采样。
- 实验表明,MADP在覆盖控制任务中表现出色,泛化能力强,且优于现有基线方法。
📝 摘要(中文)
本文提出了一种新颖的基于扩散模型的多智能体协作方法MADP,用于分散式机器人集群。MADP利用扩散模型从复杂和高维的动作分布中生成样本,这些分布捕捉了智能体动作之间的相互依赖性。每个机器人基于自身观测和从其他智能体接收到的感知嵌入的融合表示来调节策略采样。为了评估该方法,我们使用MADP控制一组全向移动机器人来解决覆盖控制问题,这是一个典型的多智能体导航问题。该策略通过模仿学习从覆盖控制问题的先知专家处学习,扩散过程由空间Transformer架构参数化,以实现分散式推理。我们在不同数量、位置和方差的重要性密度函数下评估该系统,捕捉了真实世界覆盖任务的鲁棒性需求。实验表明,我们的模型继承了扩散模型的宝贵特性,可以泛化到不同的智能体密度和环境,并且始终优于最先进的基线。
🔬 方法详解
问题定义:论文旨在解决多智能体系统中的覆盖控制问题,即如何有效地利用一组机器人覆盖一个区域,并根据重要性密度函数进行优化。现有方法通常难以处理智能体数量变化、环境复杂以及智能体间依赖关系等挑战,导致覆盖效率和鲁棒性不足。
核心思路:论文的核心思路是利用扩散模型学习复杂的多智能体动作分布,从而实现高效的覆盖控制。通过将每个智能体的策略建模为一个扩散过程,可以有效地捕捉智能体之间的相互依赖关系,并生成协调一致的动作。此外,通过模仿学习,可以从专家策略中学习到有效的覆盖策略。
技术框架:MADP的整体架构包括以下几个主要模块:1)感知模块:每个智能体收集自身观测和来自其他智能体的感知嵌入。2)融合模块:将自身观测和接收到的感知嵌入进行融合,得到一个统一的表示。3)扩散模型:基于融合后的表示,利用扩散模型生成动作样本。4)执行模块:将生成的动作发送给机器人执行。整个流程是分散式的,每个智能体独立进行决策。
关键创新:MADP的关键创新在于将扩散模型应用于多智能体协作控制,并提出了一种基于空间Transformer架构的分散式推理方法。与传统的集中式控制方法相比,MADP具有更好的可扩展性和鲁棒性。与基于强化学习的方法相比,MADP可以通过模仿学习从专家策略中快速学习,避免了复杂的奖励函数设计。
关键设计:扩散模型使用空间Transformer架构进行参数化,以实现分散式推理。损失函数采用模仿学习的损失函数,例如均方误差或交叉熵损失。重要性密度函数用于指导覆盖控制,智能体需要根据重要性密度函数调整其位置,以实现最佳覆盖效果。感知嵌入的设计需要考虑智能体之间的通信带宽限制。
🖼️ 关键图片
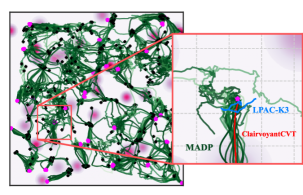
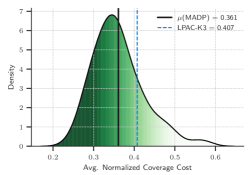

📊 实验亮点
实验结果表明,MADP在覆盖控制任务中显著优于现有基线方法。具体来说,MADP在不同智能体密度和环境下的泛化能力更强,能够更好地适应环境变化。此外,MADP在覆盖效率和鲁棒性方面也表现出色,能够有效地覆盖目标区域,并抵抗干扰。
🎯 应用场景
MADP具有广泛的应用前景,例如环境监测、搜索救援、农业机器人、以及自动驾驶等领域。该方法可以有效地提高多智能体系统的协作效率和鲁棒性,使其能够在复杂和动态的环境中完成各种任务。未来,MADP可以进一步扩展到其他多智能体任务,例如编队控制、协同搬运等。
📄 摘要(原文)
We propose MADP, a novel diffusion-model-based approach for collaboration in decentralized robot swarms. MADP leverages diffusion models to generate samples from complex and high-dimensional action distributions that capture the interdependencies between agents' actions. Each robot conditions policy sampling on a fused representation of its own observations and perceptual embeddings received from peers. To evaluate this approach, we task a team of holonomic robots piloted by MADP to address coverage control-a canonical multi agent navigation problem. The policy is trained via imitation learning from a clairvoyant expert on the coverage control problem, with the diffusion process parameterized by a spatial transformer architecture to enable decentralized inference. We evaluate the system under varying numbers, locations, and variances of importance density functions, capturing the robustness demands of real-world coverage tasks. Experiments demonstrate that our model inherits valuable properties from diffusion models, generalizing across agent densities and environments, and consistently outperforming state-of-the-art baselines.