Orchestrate, Generate, Reflect: A VLM-Based Multi-Agent Collaboration Framework for Automated Driving Policy Learning
作者: Zengqi Peng, Yusen Xie, Yubin Wang, Rui Yang, Qifeng Chen, Jun Ma
分类: cs.RO
发布日期: 2025-09-21
💡 一句话要点
提出基于VLM多智能体协作框架OGR,用于自动驾驶策略的自动化学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 强化学习 视觉语言模型 多智能体协作 奖励函数设计
📋 核心要点
- 复杂动态驾驶任务中,人工设计奖励函数和训练课程耗时费力,成为策略学习的瓶颈。
- OGR框架利用VLM的多模态理解能力,构建分层智能体系统,自动生成奖励函数和训练课程。
- 实验表明,OGR在CARLA模拟器和真实世界中均表现出卓越的性能和泛化能力。
📝 摘要(中文)
本文提出了一种名为OGR(Orchestrate, Generate, Reflect)的自动驾驶策略学习框架,该框架利用基于视觉语言模型(VLM)的多智能体协作。OGR框架利用VLM的推理和多模态理解能力构建分层智能体系统。其中,中心化的协调器规划高层训练目标,生成模块采用两步分析-生成过程来高效生成奖励-课程对,反射模块则基于在线评估促进迭代优化。此外,专门的记忆模块赋予VLM智能体长期记忆能力。为了增强生成过程的鲁棒性和多样性,引入了并行生成方案和人机协作技术来扩充奖励观察空间。通过高效的多智能体协作和利用丰富的多模态信息,OGR能够在线演化强化学习策略,从而获得交互感知的驾驶技能。在CARLA模拟器中的大量实验表明,OGR具有卓越的性能、在不同城市场景中的鲁棒泛化能力以及与各种RL算法的强大兼容性。进一步的真实世界实验突出了该框架的实际可行性和有效性。
🔬 方法详解
问题定义:现有自动驾驶策略学习方法依赖于手动设计的奖励函数和训练课程,这对于复杂和动态的驾驶环境来说是劳动密集且耗时的。如何自动化奖励函数和训练课程的设计,从而降低人工成本并提高策略学习效率,是本文要解决的核心问题。
核心思路:本文的核心思路是利用视觉语言模型(VLM)强大的推理和多模态理解能力,构建一个多智能体协作框架,该框架能够自动生成奖励函数和训练课程,并根据在线评估结果进行迭代优化。通过模仿人类专家设计奖励和课程的过程,实现自动驾驶策略的在线演化。
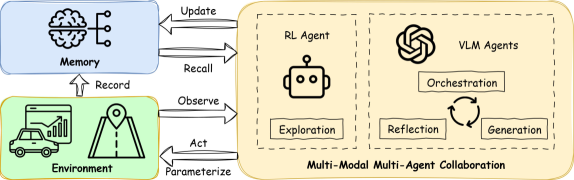
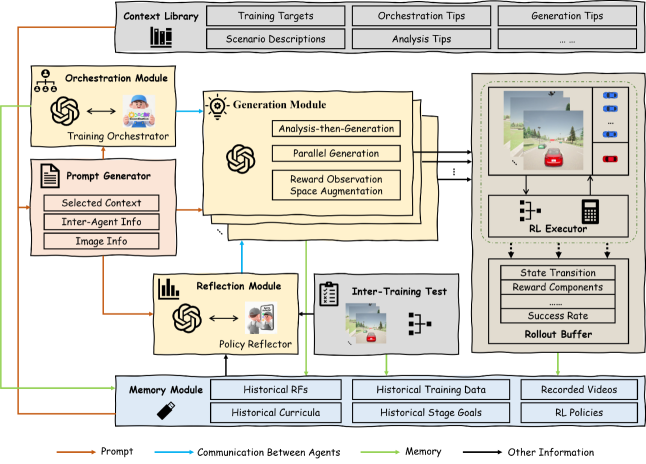
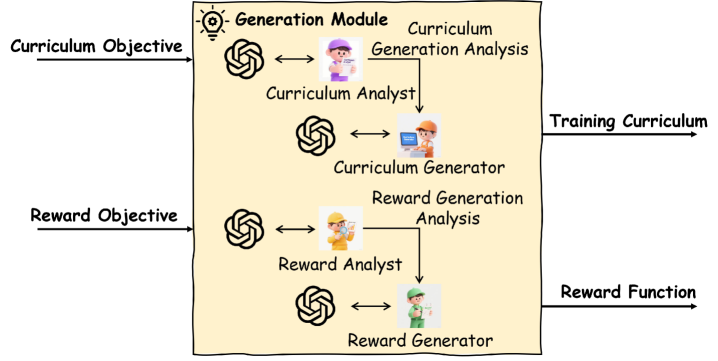
技术框架:OGR框架包含三个主要模块:协调器(Orchestrate)、生成器(Generate)和反射器(Reflect)。协调器负责规划高层训练目标;生成器采用两步分析-生成过程,首先分析当前驾驶场景,然后生成相应的奖励函数和训练课程;反射器则根据在线评估结果,对生成的奖励函数和训练课程进行迭代优化。此外,框架还包含一个记忆模块,用于存储长期记忆,以及一个并行生成模块和一个人机协作模块,用于增强生成过程的鲁棒性和多样性。
关键创新:OGR框架的关键创新在于利用VLM构建多智能体协作系统,实现奖励函数和训练课程的自动化生成和迭代优化。与传统的基于人工设计的奖励函数和训练课程的方法相比,OGR能够显著降低人工成本,并提高策略学习效率。此外,OGR框架还引入了并行生成和人机协作技术,进一步增强了生成过程的鲁棒性和多样性。
关键设计:生成模块采用两步分析-生成过程,首先利用VLM分析当前驾驶场景,提取关键信息,然后根据提取的信息生成相应的奖励函数和训练课程。反射模块则根据在线评估结果,利用强化学习算法对生成的奖励函数和训练课程进行迭代优化。此外,框架还设计了一个专门的记忆模块,用于存储长期记忆,并利用并行生成和人机协作技术来增强生成过程的鲁棒性和多样性。
🖼️ 关键图片
📊 实验亮点
在CARLA模拟器中的实验表明,OGR框架在性能、泛化能力和与各种RL算法的兼容性方面均优于现有方法。在不同的城市场景中,OGR能够学习到交互感知的驾驶技能,并取得显著的性能提升。此外,真实世界实验也验证了OGR框架的实际可行性和有效性。
🎯 应用场景
该研究成果可应用于自动驾驶策略的快速开发和部署,尤其是在复杂和动态的城市环境中。通过自动化奖励函数和训练课程的设计,可以显著降低自动驾驶系统的开发成本,并提高其安全性和可靠性。此外,该框架还可以扩展到其他机器人领域,例如无人机和移动机器人等。
📄 摘要(原文)
The advancement of foundation models fosters new initiatives for policy learning in achieving safe and efficient autonomous driving. However, a critical bottleneck lies in the manual engineering of reward functions and training curricula for complex and dynamic driving tasks, which is a labor-intensive and time-consuming process. To address this problem, we propose OGR (Orchestrate, Generate, Reflect), a novel automated driving policy learning framework that leverages vision-language model (VLM)-based multi-agent collaboration. Our framework capitalizes on advanced reasoning and multimodal understanding capabilities of VLMs to construct a hierarchical agent system. Specifically, a centralized orchestrator plans high-level training objectives, while a generation module employs a two-step analyze-then-generate process for efficient generation of reward-curriculum pairs. A reflection module then facilitates iterative optimization based on the online evaluation. Furthermore, a dedicated memory module endows the VLM agents with the capabilities of long-term memory. To enhance robustness and diversity of the generation process, we introduce a parallel generation scheme and a human-in-the-loop technique for augmentation of the reward observation space. Through efficient multi-agent cooperation and leveraging rich multimodal information, OGR enables the online evolution of reinforcement learning policies to acquire interaction-aware driving skills. Extensive experiments in the CARLA simulator demonstrate the superior performance, robust generalizability across distinct urban scenarios, and strong compatibility with various RL algorithms. Further real-world experiments highlight the practical viability and effectiveness of our framework. The source code will be available upon acceptance of the paper.