ReSeFlow: Rectifying SE(3)-Equivariant Policy Learning Flows
作者: Zhitao Wang, Yanke Wang, Jiangtao Wen, Roberto Horowitz, Yuxing Han
分类: cs.RO, cs.CV
发布日期: 2025-09-20
备注: This work was submitted to 2026 IEEE International Conference on Robotics & Automation
💡 一句话要点
提出ReSeFlow,一种快速、保几何一致性的SE(3)等变策略学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 策略学习 SE(3)等变性 Rectified Flow 扩散模型 生成模型 轨迹规划
📋 核心要点
- 现有的SE(3)等变扩散模型在机器人操作任务中表现出数据效率优势,但推理时间成本较高,限制了其应用。
- ReSeFlow将rectified flow引入SE(3)扩散模型,通过学习一个更直接的映射,加速策略生成过程,同时保持SE(3)等变性。
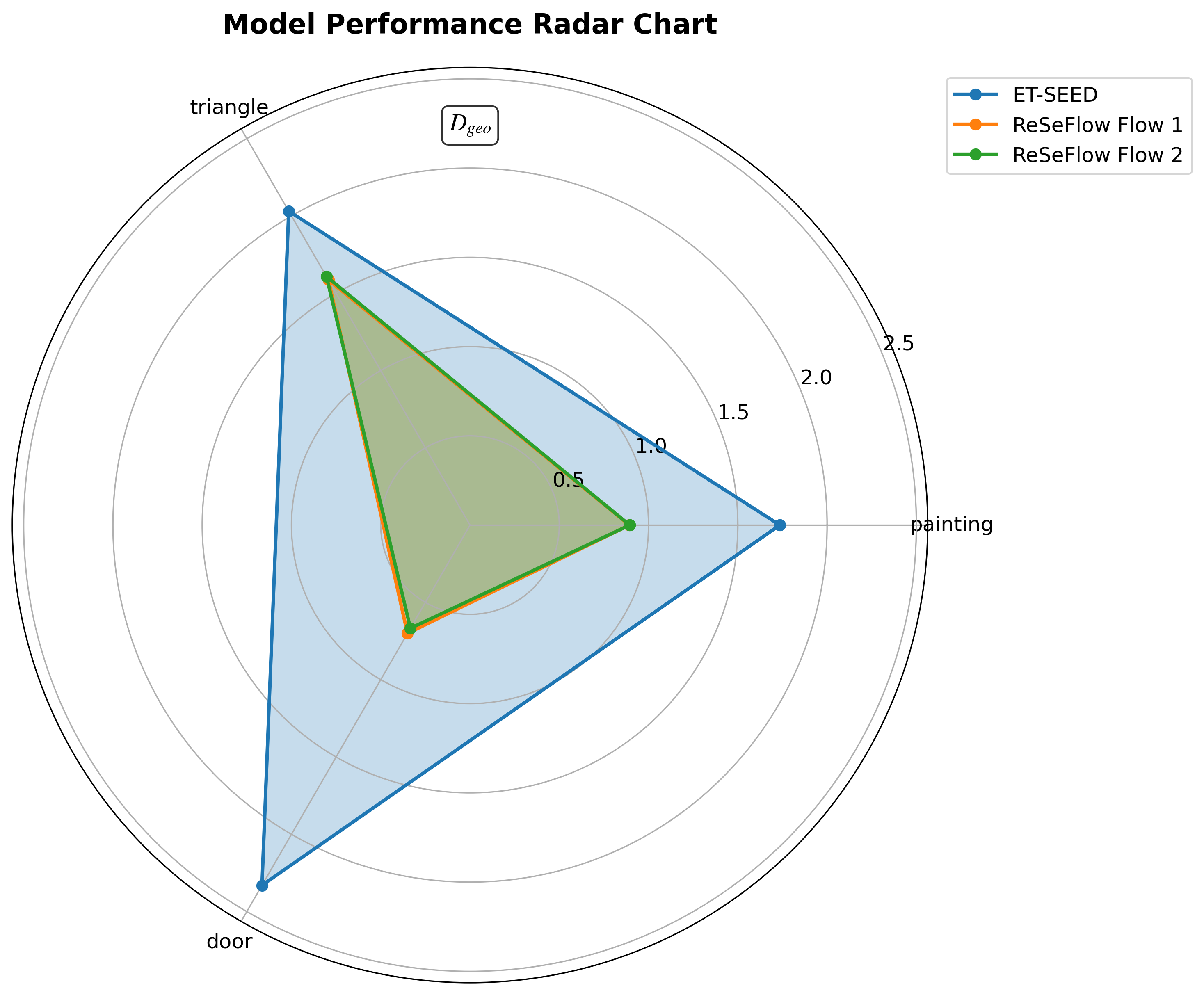
- 实验表明,ReSeFlow仅需单步推理即可超越基线方法多步推理的效果,显著降低了绘画和旋转三角形任务的误差。
📝 摘要(中文)
本文提出ReSeFlow,即Rectifying SE(3)-Equivariant Policy Learning Flows,旨在解决非结构化环境中机器人操作任务中,SE(3)等变扩散模型推理速度慢的问题。ReSeFlow将rectified flow的思想引入SE(3)扩散模型,实现快速、保几何一致性且计算量小的策略生成。该方法利用SE(3)等变网络保持旋转和平移对称性,增强了在刚体运动下的泛化能力。在模拟基准测试中,ReSeFlow仅需一步推理即可达到优于基线方法的性能,并在大地测量距离上表现更佳。在绘画任务中,误差降低高达48.5%,在旋转三角形任务中,误差降低21.9%(对比基线方法100步推理)。ReSeFlow结合了SE(3)等变性和rectified flow的优势,推动了生成策略学习模型在实际应用中的数据和推理效率。
🔬 方法详解
问题定义:论文旨在解决机器人操作任务中,基于SE(3)等变扩散模型的策略学习方法推理速度慢的问题。现有方法虽然数据效率高,但由于扩散模型的迭代特性,推理过程需要多次迭代,计算成本高昂,难以满足实时性要求。
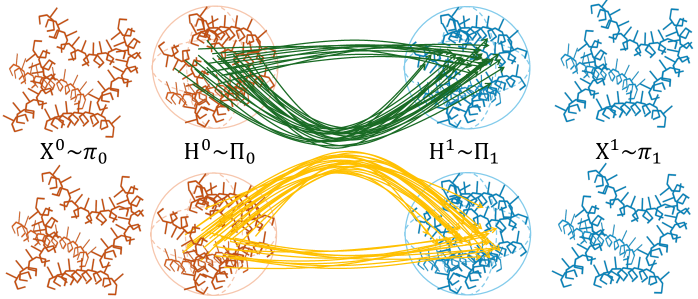
核心思路:论文的核心思路是将rectified flow的思想引入SE(3)等变扩散模型。Rectified flow通过学习一个更直接的映射,将噪声空间直接映射到数据空间,从而减少或消除迭代过程,实现快速推理。结合SE(3)等变性,保证了模型在刚体变换下的鲁棒性。
技术框架:ReSeFlow的整体框架包含两个主要部分:SE(3)等变网络和rectified flow。SE(3)等变网络用于提取感知观测的特征,并保证模型输出对旋转和平移变换的不变性。Rectified flow则学习从噪声空间到策略空间的映射,通过最小化两个分布之间的差异,使得推理过程更加直接和高效。训练过程包括前向过程和反向过程,前向过程用于学习噪声到数据的映射,反向过程则用于优化映射的质量。
关键创新:论文的关键创新在于将rectified flow的思想与SE(3)等变扩散模型相结合,提出了ReSeFlow。这种结合既保留了SE(3)等变模型的鲁棒性,又利用rectified flow加速了推理过程。与传统的扩散模型相比,ReSeFlow无需多次迭代,即可生成高质量的策略。
关键设计:ReSeFlow的关键设计包括:1) 使用SE(3)等变卷积神经网络提取特征,保证模型对刚体变换的不变性;2) 设计合适的损失函数,用于优化rectified flow的映射,例如使用最优传输距离或KL散度等;3) 选择合适的网络结构,例如使用残差连接或注意力机制,提高模型的表达能力和训练稳定性。
🖼️ 关键图片

📊 实验亮点
ReSeFlow在模拟基准测试中表现出色,仅需单步推理即可超越基线方法(100步推理)的性能。在绘画任务中,ReSeFlow的误差降低了48.5%,在旋转三角形任务中,误差降低了21.9%。此外,ReSeFlow还表现出更好的大地测量距离,表明其生成的策略更加平滑和自然。
🎯 应用场景
ReSeFlow具有广泛的应用前景,可应用于各种需要快速、鲁棒策略生成的机器人操作任务中,例如:工业自动化中的装配、抓取,家庭服务机器人中的物体整理,以及医疗机器人中的手术辅助等。该方法能够提高机器人的自主性和适应性,使其能够在复杂、动态的环境中完成任务。
📄 摘要(原文)
Robotic manipulation in unstructured environments requires the generation of robust and long-horizon trajectory-level policy with conditions of perceptual observations and benefits from the advantages of SE(3)-equivariant diffusion models that are data-efficient. However, these models suffer from the inference time costs. Inspired by the inference efficiency of rectified flows, we introduce the rectification to the SE(3)-diffusion models and propose the ReSeFlow, i.e., Rectifying SE(3)-Equivariant Policy Learning Flows, providing fast, geodesic-consistent, least-computational policy generation. Crucially, both components employ SE(3)-equivariant networks to preserve rotational and translational symmetry, enabling robust generalization under rigid-body motions. With the verification on the simulated benchmarks, we find that the proposed ReSeFlow with only one inference step can achieve better performance with lower geodesic distance than the baseline methods, achieving up to a 48.5% error reduction on the painting task and a 21.9% reduction on the rotating triangle task compared to the baseline's 100-step inference. This method takes advantages of both SE(3) equivariance and rectified flow and puts it forward for the real-world application of generative policy learning models with the data and inference efficiency.