End-to-end RL Improves Dexterous Grasping Policies
作者: Ritvik Singh, Karl Van Wyk, Pieter Abbeel, Jitendra Malik, Nathan Ratliff, Ankur Handa
分类: cs.RO, cs.LG
发布日期: 2025-09-19
备注: See our blog post: https://e2e4robotics.com/
💡 一句话要点
提出解耦模拟器与强化学习的策略,提升灵巧抓取的端到端强化学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 灵巧抓取 端到端强化学习 视觉强化学习 解耦模拟器 深度信息蒸馏
📋 核心要点
- 基于视觉的灵巧抓取端到端强化学习,面临着内存效率低和批量大小受限的挑战,阻碍了PPO等算法的有效训练。
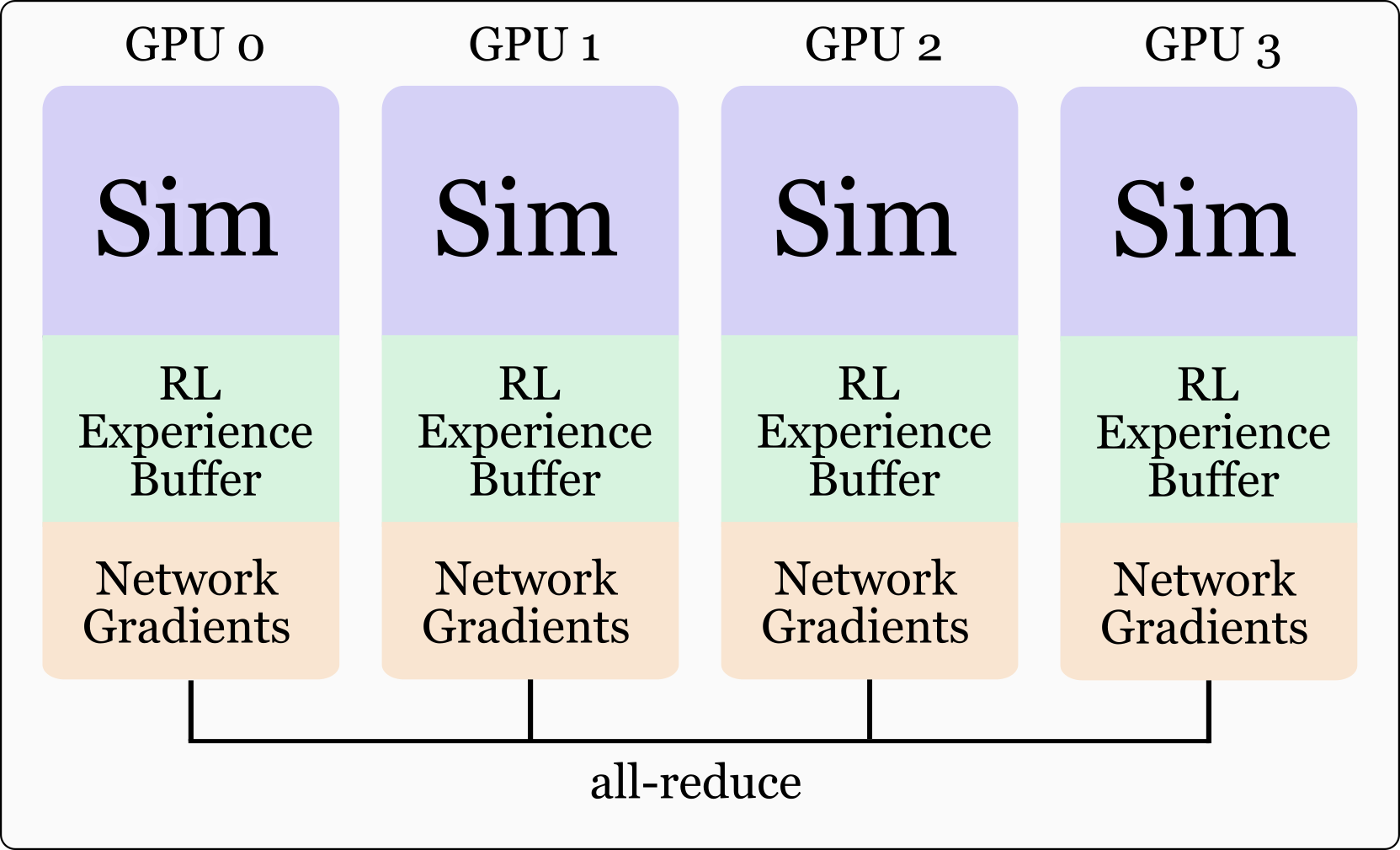
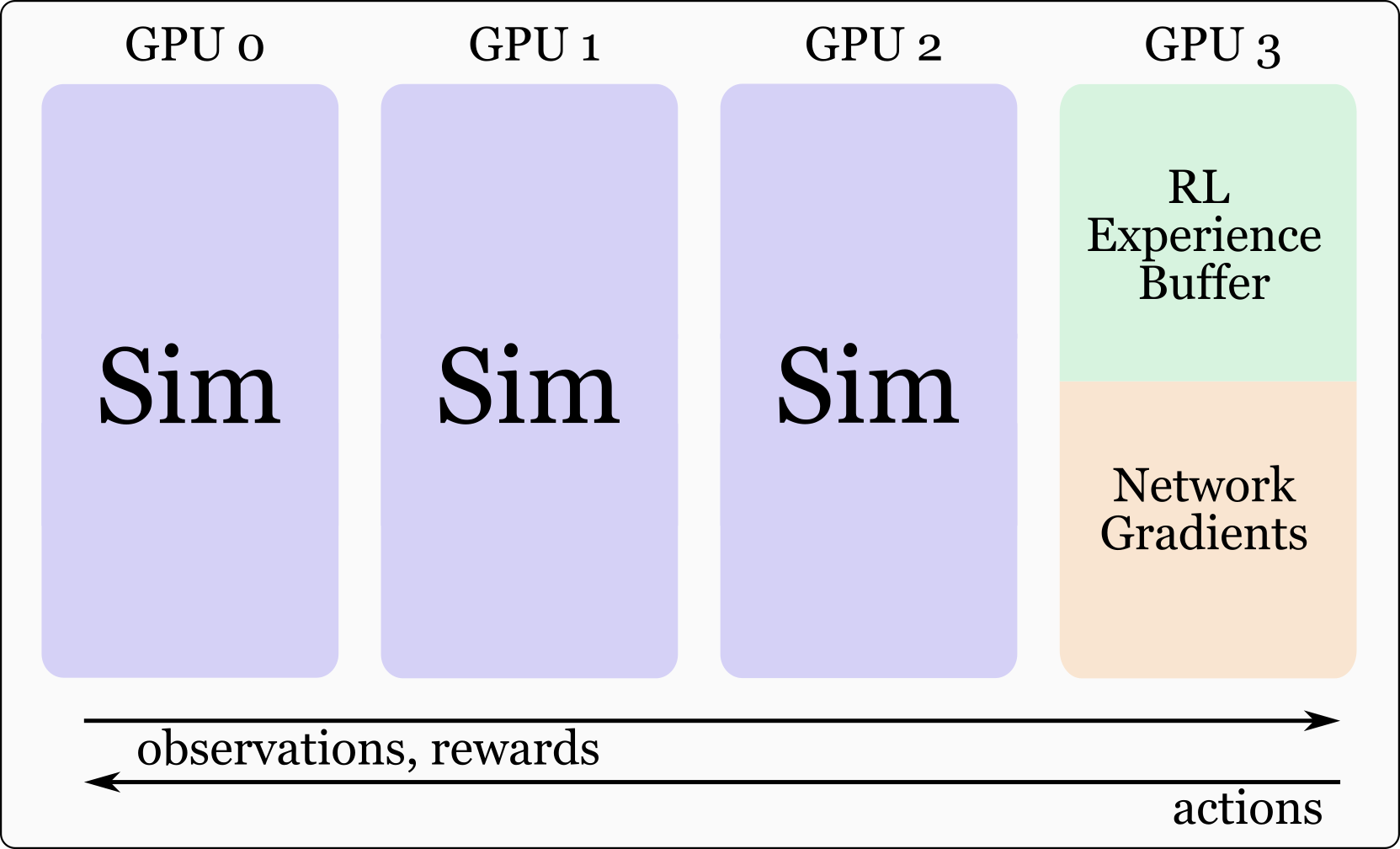
- 论文提出一种解耦模拟器和强化学习的新方法,将它们分配到不同的GPU上,从而显著提升了训练效率和环境数量。
- 实验表明,该方法在模拟和真实环境中均取得了显著的性能提升,尤其是在深度信息蒸馏到立体RGB网络中时。
📝 摘要(中文)
本文探索了扩展基于图像的端到端学习技术,以实现使用机械臂+灵巧手的灵巧抓取。与基于状态的强化学习不同,基于视觉的强化学习在内存效率方面较低,导致批量大小相对较小,这不利于像PPO这样的算法。然而,端到端强化学习仍然是一种有吸引力的方法,因为它不像常用的将基于状态的策略提炼到视觉网络中的技术,它可以实现涌现式的主动视觉行为。我们发现训练这些策略的一个关键瓶颈是大多数现有模拟器使用传统数据并行技术扩展到多个GPU的方式。我们提出了一种新方法,将模拟器和强化学习(包括训练和经验缓冲区)分离到不同的GPU上。在一个具有四个GPU的节点上,模拟器在其中三个上运行,而PPO在第四个上运行。我们能够证明,在相同数量的GPU下,与之前的标准数据并行基线相比,我们可以将现有环境的数量增加一倍。这使我们能够端到端地训练基于视觉的环境,并使用深度信息,而这些环境之前的性能远低于基线。我们训练并将深度和基于状态的策略提炼到立体RGB网络中,并表明深度提炼可以带来更好的结果,无论是在模拟中还是在现实中。这种改进可能是由于状态和视觉策略之间的可观察性差距,而将深度策略提炼到立体RGB时不存在这种差距。我们进一步表明,解耦模拟带来的批量大小增加也提高了现实世界的性能。在现实世界中部署时,我们使用端到端策略改进了先前最先进的基于视觉的结果。
🔬 方法详解
问题定义:论文旨在提升基于视觉的灵巧抓取任务中,端到端强化学习的训练效率和性能。现有方法,特别是基于状态策略蒸馏到视觉网络的方法,难以充分利用视觉信息,且基于视觉的强化学习内存效率低,导致训练时批量大小受限,影响训练效果。传统的数据并行方法在多GPU环境下扩展模拟器时效率不高,成为训练瓶颈。
核心思路:论文的核心思路是将模拟器和强化学习算法(包括经验缓冲区)解耦,并分别分配到不同的GPU上。这样可以充分利用多GPU资源,增加训练时的环境数量和批量大小,从而提高训练效率和性能。解耦的设计允许模拟器专注于环境生成,而强化学习算法专注于策略优化,避免了资源竞争。
技术框架:整体框架包含以下几个主要部分:1) 多个GPU用于运行模拟器,负责生成环境和收集经验数据;2) 一个独立的GPU用于运行强化学习算法(PPO),负责策略更新和训练;3) 一个经验缓冲区,用于存储模拟器生成的经验数据,供强化学习算法使用。模拟器和强化学习算法之间通过数据传输进行通信。
关键创新:最重要的技术创新点在于模拟器和强化学习算法的解耦。这种解耦打破了传统数据并行方法的限制,允许更有效地利用多GPU资源,显著提高了训练效率。此外,论文还探索了深度信息蒸馏到立体RGB网络的方法,进一步提升了视觉策略的性能。
关键设计:论文的关键设计包括:1) 使用PPO作为强化学习算法;2) 将模拟器和强化学习算法分配到不同的GPU上;3) 使用深度信息进行策略蒸馏,将深度策略提炼到立体RGB网络中。具体参数设置和网络结构未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
论文提出的解耦模拟器和强化学习算法的方法,在相同GPU数量下,可以将环境数量增加一倍。实验结果表明,该方法显著提升了基于视觉的灵巧抓取策略的性能,并在真实世界中超越了先前的state-of-the-art结果。深度信息蒸馏到立体RGB网络也带来了显著的性能提升。
🎯 应用场景
该研究成果可应用于机器人灵巧操作、自动化装配、智能辅助等领域。通过提升机器人对复杂环境的感知和操作能力,可以实现更高效、更智能的自动化生产和人机协作。未来,该技术有望在工业、医疗、服务等领域得到广泛应用。
📄 摘要(原文)
This work explores techniques to scale up image-based end-to-end learning for dexterous grasping with an arm + hand system. Unlike state-based RL, vision-based RL is much more memory inefficient, resulting in relatively low batch sizes, which is not amenable for algorithms like PPO. Nevertheless, it is still an attractive method as unlike the more commonly used techniques which distill state-based policies into vision networks, end-to-end RL can allow for emergent active vision behaviors. We identify a key bottleneck in training these policies is the way most existing simulators scale to multiple GPUs using traditional data parallelism techniques. We propose a new method where we disaggregate the simulator and RL (both training and experience buffers) onto separate GPUs. On a node with four GPUs, we have the simulator running on three of them, and PPO running on the fourth. We are able to show that with the same number of GPUs, we can double the number of existing environments compared to the previous baseline of standard data parallelism. This allows us to train vision-based environments, end-to-end with depth, which were previously performing far worse with the baseline. We train and distill both depth and state-based policies into stereo RGB networks and show that depth distillation leads to better results, both in simulation and reality. This improvement is likely due to the observability gap between state and vision policies which does not exist when distilling depth policies into stereo RGB. We further show that the increased batch size brought about by disaggregated simulation also improves real world performance. When deploying in the real world, we improve upon the previous state-of-the-art vision-based results using our end-to-end policies.